
Pandas
- Hvorfor pandas?
- Grunnleggende
- Indeks og subset
- Sett sammen to dataframes
- Opperasjoner med dataframes
- Gruppering
Introduksjon

(designed by Nerdy Vogue)
Mennesker produserer enorme mengder data hver dag. Hver gang noen trykker på en skjerm, kjøper noe på butikken eller besøker en nettside lager du data som lagres i et gitt format. Den enkleste måten å forestille seg data på er i tabeller: hver rad representerer en observasjon og hver kolonne represerer en attribut/ kategori for den gitte observasjonen.
Når det gjelder å jobbe med datatabeller på datamaskiner, er Excel, Sheets eller R de første verktøyene man tenker på. De er alle gode, men ingen av dem gir like stor skalerbarhet, støtte fra brukersamfunnet og allsidige muligheter for videre arbeid med dataene på samme tid. Hva om vi ønsker å analysere tabelldata i Python? Svaret er biblioteket Pandas! Det er egnet for ulike formater, som for eksempel:
- Tabelldata lagret i relasjonsdatabaser med kolonner av ulike datatyper, som i en SQL-tabell eller et Excel-regneark
- Ordnede og uordnede tidsserier og panel data (som gav navnet til pandas)
- Vilkårlige matrisedata
- En hver form for observasjonsbasert eller statistiske datasett
Grunnleggende
Datatabeller i pandas kalles DataFrames. Det er en 2-dimensjonal, størrelsesmuterbar, potensielt hetrogen tabell. Man kan tenke på det som et oppslagsverk der nøklene er variabelnavnene, og verdiene er data i dataframen. Her er hvordan man kan lage en dataframe fra bunn av:
# importrer pakken (hvis ModuleNotFoundError: pip install pandas)
import pandas as pd
## mulighet 1: fra et oppslagsverk med nøkler som kolonnenavn og verdi som kolonneverdier
gene_data = {
"Gene": [ # kolonnenavn
"BRCA1", # kolonneverdier
"TP53",
"MYC"
],
"Level": [150, 320, 210]
}
df = pd.DataFrame(gene_data)
print(df, "\n\n", type(df)) # <class 'pandas.core.frame.DataFrame'>
# Gene Level
# 0 BRCA1 150
# 1 TP53 320
# 2 MYC 210
## mulighet 2: fra en 2D-liste med data pluss en vanlig liste med kolonnenavn
colnames = ["Gene", "Level"]
values = [
["BRCA1", 150],
["TP53", 320],
["MYC", 210]]
df = pd.DataFrame(values, columns = colnames)
print(df, "\n\n", type(df)) # <class 'pandas.core.frame.DataFrame'>
# Gene Level
# 0 BRCA1 150
# 1 TP53 320
# 2 MYC 210
Når det er sagt, jobber vi ofte med dataframes som allerede er lagd. De kan være lagret i ulike formater. De mest vanlige er .csv, .xls og .json. En av de mest populære datasettene for trening er iris. Nå skal vi undersøke det litt nærmere:
import csv
import requests
import io
csv_url = 'https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv'
## mulighet 1: last ned en CSV-fil fra internettet, konverter den til et oppslagsverk og sett det som en DataFrame
# Last ned CSV-filen fra GitHub
response = requests.get(csv_url) # last ned CSV-filen
response.raise_for_status() # valgfritt: Sikre at filen ble hentet
data_string = response.text
# Les csv-fil akkurat som tidligere!
reader = csv.DictReader(io.StringIO(data_string), delimiter=',', quotechar="'")
headers = reader.fieldnames
data = list(reader)
iris = pd.DataFrame(data)
print(iris.head(5)) # vis de første N radene
## mulighet 2: ybruk read_csv-metoden (ikke bruk denne på eksamen!)
iris2 = pd.read_csv(csv_url,
dtype={'sepal_length': float,
'sepal_width': float,
'petal_length': float,
'petal_width': float,}) # , index_col=0
print(iris2.head()) # (5 er default)
## begge vil skrive ut:
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
iris = iris2
Som med oppslagsverk, kan man lage nye kolonner i dataframen ved å henvise til nye kolonnenavn.
import random
print('Før ny kolonne ble lagt til:', iris.shape) # (150, 5) - 150 rows, 5 columns
random_values = [round(random.random(), 2) for i in range(len(iris))] # passer på at den nye listen er like lang som antall rader i dataframen
# lage ny kolonne
iris['nonsence_random_floats'] = random_values
print('Etter kolonne ble lagt til:', iris.shape) # (150, 6) - ny kolonne vises
# slette eksisterende kolonne
iris = iris.drop(columns=['nonsence_random_floats'])
print('Etter drop:', iris.shape) # (150, 5) - ha det kolonne!
I tillegg til .head() og .tail() for å se de første og siste N radene, kan man også se dataframens kolonner og konvertere de tilbake til numpy arrays:
print(iris.head(2), '\n\n') # viser de første 2 radene
print(iris.tail(2), '\n\n') # viser de siste 2 radene
print(iris.columns, '\n\n') # viser kolonnenes navn: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width','species']
print(iris.index, '\n\n') # viser radens indekser (kun en range hvis ikke annet er spesifisert)
print(iris.to_numpy()[0:3]) # konverterer dataframen til et numpy array
Indeks og subset
Akkurat som dataholdere i Python, tillater dataframes oss å hente spesifikk data. For pandas dataframes kan man bruke både nøkler (kolonnenavn) og indekser (radnummer) til å hente data:
# hente kolonner
species_column = iris['species'] # akkurat som med oppslagsverk
species_column2 = iris.species # eller som en attributt
assert species_column.equals(species_column2) # True
print(species_column, "\n\n", type(species_column)) # <class 'pandas.core.series.Series'>
# 0 setosa
# 1 setosa
# 2 setosa
# ...
# 149 virginica
# Name: species, dtype: object
# hente rader
row = iris.loc[2] # 3rd obs/rad (med indeks 2)
print(row, "\n\n", type(row)) # <class 'pandas.core.series.Series'>
# sepal_length 4.7
# sepal_width 3.2
# petal_length 1.3
# petal_width 0.2
# species setosa
# Name: 2, dtype: object
Ved begge metoder får man en pandas serie - et 1D array. Den første printer hele art-kolonnen, mens den andre kun henter ut en spesifikk rad.
Hvis man vil hente ut eller endre en spesifikk celles verdi, kan man gjøre følgende:
print(iris.iloc[5,2]) # 1.7
iris.iat[5,2] = 1.8 # endrer verdien på 6. rad og 3. kolonne til 1.8 (pass på at det er samme datatype)
Man kan også lage subset av en dataframe. Dette gjøres på 2 måter:
- Ved å velge kolonner og rader som skal (husk doble firkantparanteser dersom det gjelder flere kolonner, for eksempel [‘col1’,‘col2’]).
- Ved å filtrere dataframen med en boolean maske - akkurat som med numpy arrays: lag en logisk betingelse og sett den inni firkantparantes under dataframen.

# lage subset uten filter
irises_sepals_data = iris[['sepal_length', 'sepal_width' , 'species']] # velg kun kolonnene om sepals og art
half_of_irises_sepals_data = irises_sepals_data.sample(frac=0.5) # bonus: hent tilfeldig utvalg av 50% av observasjonene
print(half_of_irises_sepals_data.head()) # vis N rader
# sepal_length sepal_width species
# 127 6.1 3.0 virginica
# 84 5.4 3.0 versicolor
# 130 7.4 2.8 virginica
# 114 5.8 2.8 virginica
# 100 6.3 3.3 virginica...
# Filtrer rader der sepal_width er større enn 3
more_than_3_mask = iris['sepal_width'].astype(float) > 3 # filtrer rader etter en betingelse
print(more_than_3_mask, '\n') # Boolean maske
# 0 True
# 1 False
# 2 True
# ...
# Behold kun radene der betingelsen er True
print(iris[more_than_3_mask], '\n') # Filtrerte rader
# # [67 rows x 5 columns]
# Alternativt i en komprimert linje (motsatt betingelse):
print(iris[iris['sepal_width'].astype(float) <= 3]) # Filtrer radene etter motsatt betingelse
# [83 rows x 5 columns]
Sett sammen to dataframes
Noen ganger trenger man å merge to dataframes. Her er ulike måter å gjøre det på:
- concat - sett sammen serien/dataframen akkurat som numpy arrays
- merge - sett sammen etter en felles nøkkel/kolonne og setter sammen rader som matcher
La oss splitte iris dataframen og sette den sammen igjen:
# del iris dataframen i 2
iris1 = iris.iloc[:75] # første halvdel
iris2 = iris.iloc[75:] # andre halvdel
# concatenate to dataframes
iris_combined = pd.concat([iris1, iris2], axis=0) # axis=0 betyr rader
# lag en ny Serie med størrelse på blomstene basert på observasjonene i dataframen
sizes = pd.Series({'virginica': 'big', 'versicolor': 'medium', 'setosa': 'small'}, name='size')
iris = iris.merge(sizes, left_on='species', right_index=True, how='left') # merge iriser med den nye dataen etter kolonnen 'species'
print(iris.sample(3)) # vis 3 tilfeldige rader
Opperasjoner med dataframes
Dataframe-objekter arver noen attributter fra numpy array-klassen. Man kan altså sjekke ting som -size, .shape og .dtypes.
Når det kommer til metoder (pandas-funksjoner som brukes etter dataframen som df.head()), er det mye nyttig man kan gjøre.
# hent formen på dataframen
print("\nForm på dataframen:", iris.shape) # (150, 5)
# hent datatypen for hver kolonne
print("\nDatatype for hver kolonne:\n", iris.dtypes, sep = "")
# sepal_length float64
# sepal_width float64
# petal_length float64
# petal_width float64
# species object
Den største fordelen er likevel at man kan se oppsummerings-statistikk. Her er det viktig at alle kolonner har korrekt datatype
iris.info()
summary = iris.describe() # oppsummerigs-statistikk
print("Oppsummerings-statistikk:\n", summary.transpose(), sep = "") # for lesbarhet
# Oppsummerings-statistikk:
# count mean std min 25% 50% 75% max
# sepal_length 150.0 5.843333 0.828066 4.3 5.1 5.80 6.4 7.9
# sepal_width 150.0 3.057333 0.435866 2.0 2.8 3.00 3.3 4.4
# petal_length 150.0 3.758000 1.765298 1.0 1.6 4.35 5.1 6.9
# petal_width 150.0 1.199333 0.762238 0.1 0.3 1.30 1.8 2.5
Gruppering
Denne statistikken kan også kalkuleres for hver art - dette kalles gruppering, eller group by. Dette referer normal til en prosess som involverer ett eller flere av de følgende stegene:
- Splitte dataene inn i grupper basert på gitte betingelser
- Kalle på en funksjon på gruppene hver for seg
- Kombinere resultatet inn i en datastruktur
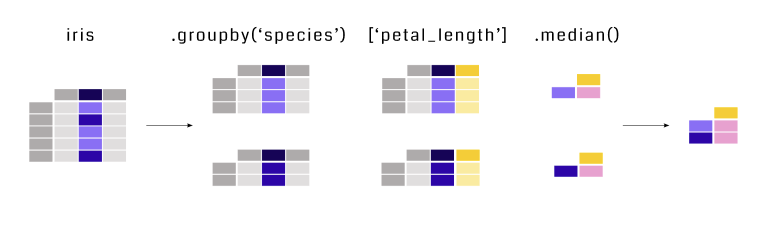
grouped_medians = iris.groupby('species')['petal_length'].median() # gruppere etter art og finne medianen
print("Grouped Summary Statistics by Species:\n", grouped_medians)