
Eksamen
| 11. mai 2026 |
| 4 timer |
| Lukket digital eksamen (med safe exam browser). |
| Tillatte hjelpemiddel: bøker frå litteraturlista og opp til 6 tosidige A4 ark med eigne notat. |
- Kursnotater er tilgjengelige og søkbare under eksamen: pdf
Oppgavetekster, løsningsforslag og sensorveiledning finner du på denne siden.
Fordi eksamen var en lukket digital eksamen uten tilgang til å kjøre koden eller bruke internett, bes sensor ikke gi poengtrekk for forhold som enkelt ville blitt oppdaget og raskt rettet ved kjøring av koden. Dette inkluderer blant annet:
- manglende
import-setninger, - manglende kodeord (som f. eks. manglende
defforan funksjonsdefinisjoner), - feil navn på funksjoner og metoder i standardbiblioteket, i egen kode eller i eksterne moduler (såfremt det fremgår noenlunde av funksjonsnavnet hva kandidaten egentlig mener),
- feil navn på variabler (f. eks. kalle den samme variabelen både
totalogsumi ulike deler av koden), - enkle syntaks-feil (f. eks. manglende kolon etter
if-setninger), - og så videre.
Logiske feil skal det likevel (som hovedregel) bli trukket litt for; selv om man kunne ha oppdaget at noe var feil ved kjøring av koden. Dette inkluderer blant annet:
-
presedensfeil,
-
forveksling av indekser og elementer,
-
off-by-one -feil,
-
feil i algoritmer,
-
og så videre.
1 Automatisk rettet
Finn riktig datatype til hvert uttrykk (eller identifiser Error)
x = {'count':3}
y = [8, x]
w = ['strawberry']
[42, True, x] | |
'brush' in 'toothbrush' | |
f'{123}' | |
x['count']/2 | |
len(w[0]) | |
{99, 40, 1} | |
y[1] | |
x.pop(3) |
Klikk på de grå feltene for å se svaret.
x = 10
y = '10'
u = [True, 2, 3]
w = {
'cba': 2,
10: u,
}
s = 'cba'
Anta at kodesnutten over har blitt kjørt, og at en av setningene under er den neste setningen som utføres. Hva skrives ut? Hvis programmet krasjer, skriv kun Error.
(Husk at apostrofer og hermetegn som omgir strenger i kildekoden ikke er blir inkludert i utskriften.)
print(x != y) | |
print(not u[0]) | |
print(y + y) | |
print(y[0]) | |
print(s[-1]) | |
print(u[1:]) | |
print(s*w[s]) | |
print(w[x][2]) |
Klikk på de grå feltene for å se svaret.
def f(y):
y *= 2
return y
def g(x):
x = f(x)
return f(x) + x
Anta at funksjonene over er definert. Hva evaluerer disse uttrykkene til? (hvis uttrykket krasjer, skriv kun Error)
f(3) | |
g(4) | |
f(g(1)) |
Klikk på de grå feltene for å se svaret.
def update(x, y):
if x - y > 50:
return 2*y
elif x - y < 50:
y += 50
else:
x -= 50
print(y)
return y // x
x = 100
y = x + 50
Anta at kodesnutten over har blitt kjørt, og at setningen under er den neste setningen som utføres. Hva skrives ut? Hvis programmet krasjer, skriv kun Error.
print(update(x,y)) |
Klikk på det grå feltet for å se svaret.
def f(x, y):
result = []
for num in x:
if num % y == 0:
result.append(num // y)
else:
result.append(num)
return result
a = [8, 10, 36, 25]
b = f(a, 5)
Anta at kodesnutten over har blitt kjørt, og at en av setningene under er den neste setningen som utføres. Hva skrives ut? Hvis programmet krasjer, skriv kun Error.
print(a) | |
print(b) | |
print(f(f(a,5),5)) |
Klikk på de grå feltene for å se svaret.
x = 20
y = 1
while x > 0:
x -= 2
if x % 4 == 0:
continue
if x < 10:
break
y = 1 - y
Anta at kodesnutten over har blitt kjørt, og at setningen under er den neste setningen som utføres. Hva skrives ut? Hvis programmet krasjer, skriv kun Error.
print(x+y) |
Klikk på det grå feltet for å se svaret.
Denne oppgaven handler om presedens og assosiativitet. Hvordan plassere parenteser for å få et uttrykk identisk med x or not y and z or w
x or ((not (y and z)) or w) | |
(x or ((not y) and z)) or w | |
(x or (not (y and z))) or w | |
x or (((not y) and z) or w) |
Klikk på de grå feltene for å se svaret.
2 Forklaring
Et revolusjonært komité har tatt makten. De ga i oppdrag å utvikle følgende program for å administrere lederskapet:
def foo(lst):
last = lst[-1]
for i in range(len(lst) - 1, 0, -1):
lst[i] = lst[i - 1]
lst[0] = last
names = ["Bashar", "Robert", "Fidel", "Vladimir", "Kim"]
foo(names)
print(names)
- Hva gjør funksjonen foo()? Hva skriver programmet ut?
- Gi funksjonen foo() et bedre navn, slik at folk enkelt kan forstå hva funksjonen gjør uten å vite hvordan den er implementert.
- Funksjonen flytter det siste elementet i listen til første posisjon og forskyver alle de øvrige elementene én plass mot høyre i listen.
- Programmet skriver ut [“Kim”, “Bashar”, “Robert”, “Fidel”, “Vladimir”]
- Et bedre navn for denne funksjonen kan være
rotate. Navnet må uttrykke betydningen av å rotere eller forskyve.
- (2 poeng) Hva gjør funksjonen foo()?
- (1 poeng) Hva skriver programmet ut?
- (2 poeng) Gi funksjonen foo() et bedre navn, slik at folk enkelt kan forstå hva funksjonen gjør uten å vite hvordan den er implementert.
Størrelsen på et embryo måles i de første ukene av svangerskapet ved hjelp av CRL (crown-rump length) – avstanden fra toppen av hodet til enden av ryggraden. En lege ønsker å estimere CRL-verdiene for neste trimester basert på en forventet vekstfaktor. Følgende funksjon brukes til å beregne dette:
def times_factor(crl_measurements, factor):
new_lst = []
for sub_lst in crl_measurements:
new_sub_lst = []
for num in sub_lst:
new_sub_lst.append(num*factor)
new_lst.append(new_sub_lst)
return new_lst
data = [[12, 16, 21], [38, 45, 52]]
times_factor(data, 10)
print(data)
- Kjøringen gir outputen [[12, 16, 21], [38, 45, 52]], som ikke var forventet. Hva tror du den forventede utskriften burde være?
- Hvorfor klarer ikke programmet å gjøre dette?
- Hvordan vil du fikse det?
- Den forventede utskriften burde være [[120, 160, 210], [380, 450, 520]].
times_factorer en ikke-destruktiv funksjon. Det muterer ikke parameterencrl_measurements. Så listendatablir ikke endret, ogprint(data)vil skrive ut nøyaktig den samme listen som var argumentet til funksjonentimes_factor.- Problemet er at det mangler en variabel for å lagre returverdien fra
times_factor. Den korrigerte koden kan være:
def times_factor(crl_measurements, factor):
new_lst = []
for sub_lst in crl_measurements:
new_sub_lst = []
for num in sub_lst:
new_sub_lst.append(num*factor)
new_lst.append(new_sub_lst)
return new_lst
data = [[12, 16, 21], [38, 45, 52]]
predicting_data = times_factor(data, 10)
print(predicting_data)
En annen løsning er å omskrive funksjonsimplementasjonen slik at den blir destruktiv:
def times_factor(crl_measurements, factor):
for sub_lst in crl_measurements:
for i in range(len(sub_lst)):
sub_lst[i] *= factor
data = [[12, 16, 21], [38, 45, 52]]
times_factor(data, 10)
print(data)
- (1 poeng) Hva tror du den forventede utskriften burde være?
- (2 poeng) Hvorfor klarer ikke programmet å gjøre dette?
- (2 poeng) Hvordan vil du fikse det?
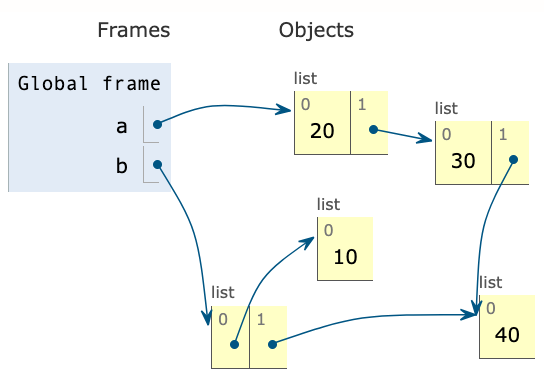
Skriv ein kodesnutt slik at minnet får den tilstanden som er vist ovanfor. For full pott må du løse oppgaven uten å bruke hjelpevariabler/andre variabler enn a og b. (bilde er hentet fra Python Tutor).
a = [20, [30, [40]]]
b = [[10], a[1][1]]
Klikk på «se steg» -knappen for å verifisere at koden gir riktig bilde av minnet.
Vi teller poengene slik:
- (2 poeng) a har verdi [20, [30, [40]]]
- (1 poeng) b har verdi [[10], [40]]
- (2 poeng) b[1] og a[1][1] peker på nøyaktig det samme liste i minnet
Du får 5 poeng for en korrekt løsning dersom du løser oppgaven uten å bruke hjelpevariabler eller andre variabler enn a og b, slik at uttrykket nedenfor evaluerer til True.
(
a == [20, [30, [40]]] and
b == [[10], [40]] and
b[1] is a[1][1] and
type(b[0]) == list and
type(b[1]) == type(a[1][1]) == list
)
Hvis du bruker andre variabler enn a og b men disse variablene finnes ikke i rammene til slutt, vil du få 4 poeng. For eksempel,
c = [40]
d = [30, c]
e = [10]
a = [20, d]
b = [e, c]
del c
del d
del e
Hvis du bruker andre variabler enn a og b men disse variablene blir fortsatt værende i rammene til slutt, vil du få 3 poeng. For eksempel,
c = [40]
d = [30, c]
e = [10]
a = [20, d]
b = [e, c]
Klikk på «se steg» -knappen for å verifisere at koden gir riktig bilde av minnet.
3 Kodeskriving
Skriv en funksjon count_letter(letter, wordlist) som teller hvor mange ganger en gitt bokstav forekommer i en liste med ord. For eksempel forekommer bokstaven ‘b’ totalt 5 ganger i listen [‘stubborn’, ‘house’, ‘cabbage’, ‘job’, ’exam’].
I denne oppgaven kan du prøve koden du skriver mot noen tester underveis i eksamen. Testene blir kjørt når du trykker på knappen «test kode» under kodefeltet. Dersom du ikke passerer alle testene, kan likevel sensor gi delvis uttelling etter en manuell vurdering.
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | count_letter(‘b’, [‘stubborn’, ‘house’, ‘cabbage’, ‘job’, ’exam’]) | 5 |
| 2 | count_letter(‘k’, [‘bookkeeping’, ’lake’, ‘kickoff’, ’tree’, ‘rucksack’]) | 7 |
| 3 | count_letter(‘b’, [‘house’, ’tree’, ‘car’, ’light’]) | 0 |
Startkode:
def count_letter(letter, wordlist):
# Skriv koden her
# ...
# IKKE rediger under denne linjen!
print(eval(input()))
def count_letter(letter, wordlist):
num = 0
for word in wordlist:
for l in word:
if l == letter:
num += 1
return num
def count_letter(letter, wordlist):
num = 0
for word in wordlist:
num += word.count(letter)
return num
def count_letter(letter, wordlist):
num = 0
for i in range(len(wordlist)):
num += wordlist[i].count(letter)
return num
- (2 poeng) Riktig bruk av løkke(r) som går igjennom elementene i listen
- (2 poeng) Tell antall forekomster av den gitte bokstaven. Startverdien til tellevariabelen er 0.
- (1 poeng) Funksjonen returnerer resultatet. return-setningen skal være utenfor løkkene.
Fortsett med den forrige oppgaven (Oppgave 11).
Skriv en funksjon count_letters(data).
dataer en liste med tupler på formen (letter, wordlist)
Funksjonen skal returnere en liste med heltall, der hvert tall angir hvor mange ganger den tilhørende bokstaven forekommer i sin ordliste.
I denne oppgaven kan du prøve koden du skriver mot noen tester underveis i eksamen. Testene blir kjørt når du trykker på knappen «test kode» under kodefeltet. Dersom du ikke passerer alle testene, kan likevel sensor gi delvis uttelling etter en manuell vurdering.
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | count_letters([(‘b’, [‘stubborn’, ‘house’, ‘cabbage’, ‘job’, ’exam’]),(‘k’, [‘bookkeeping’, ’lake’, ‘kickoff’, ’tree’, ‘rucksack’])]) | [5,7] |
| 2 | count_letters([(‘b’, [‘stubborn’, ‘house’, ‘cabbage’, ‘job’, ’exam’]), (‘b’, [‘house’, ’tree’, ‘car’, ’light’]), (‘k’, [‘bookkeeping’, ’lake’, ‘kickoff’, ’tree’, ‘rucksack’])]) | [5,0,7] |
Startkode:
def count_letters(data):
# Skriv koden her
# ...
# IKKE rediger under denne linjen!
print(eval(input()))
def count_letter(letter, wordlist):
num = 0
for word in wordlist:
for l in word:
if l == letter:
num += 1
return num
def count_letters(data):
result = []
for letter, wordlist in data:
result.append(count_letter(letter, wordlist))
return result
def count_letter(letter, wordlist):
num = 0
for word in wordlist:
for l in word:
if l == letter:
num += 1
return num
def count_letters(data):
result = []
for letter, wordlist in data:
result += [count_letter(letter, wordlist)]
return result
- (2 poeng) Hent dataene korrekt fra hver tuple
- (2 poeng) Funksjonen skal returnere en liste med heltall, der hvert tall angir hvor mange ganger den tilhørende bokstaven forekommer i sin ordliste.
- (1 poeng) return-setningen skal være utenfor løkkene
Det er tillatt å bruke funksjonen count_letter(letter, wordlist) i denne oppgaven uten å måtte skrive selve koden for funksjonen på nytt.
Skriv et Python-program som leser en CSV-fil med personopplysninger, og beregner hver enkelt persons anbefalte daglige vanninntak (i milliliter).
Vektbasert (metrisk): Multipliser vekten (kg) med 30 (ml/kg). (For eksempel: 70 kg * 30 ml/kg = 2100 ml per dag)
Anta at du har en fil health.csv med innholdet nedenfor:
Name;Weight(kg)
Henrik;70
Ingrid;52
Mathias;85
Svanhild;60
Utskriften fra programmet ditt bør være en liste med oppslagsverker:
[{"Name":"Henrik", "Weight(kg)":70,"Water":2100},
{"Name":"Ingrid", "Weight(kg)":52,"Water":1560},
{"Name":"Mathias", "Weight(kg)":85,"Water":2550},
{"Name":"Svanhild", "Weight(kg)":60,"Water":1800}]
from pathlib import Path
def main():
content_string = Path('health.csv').read_text(encoding='utf-8')
content = content_string.splitlines()
header = content[0].split(';')
body = content[1:]
result = []
for person in body:
data = person.split(';')
new_data = {}
for i in range(len(header)):
if header[i] == "Weight(kg)":
new_data[header[i]] = int(data[i])
else:
new_data[header[i]] = data[i]
new_data['Water'] = water_intake(new_data["Weight(kg)"])
result.append(new_data)
print(result)
def water_intake(w):
return w * 30
if __name__ == '__main__':
main()
from pathlib import Path
import csv
import io
def main():
content_string = Path('health.csv').read_text(encoding='utf-8')
reader = csv.DictReader(io.StringIO(content_string), delimiter=';')
data = list(reader)
for person in data:
person["Weight(kg)"] = int(person["Weight(kg)"])
person['Water'] = water_intake(person["Weight(kg)"])
print(data)
def water_intake(w):
return w * 30
if __name__ == '__main__':
main()
- (2 poeng) Les csv-filen på fornuftig måte
- (1 poeng) Bruke konverteringsfunksjonen int() for vektverdiene
- (2 poeng) Lag en formel for å beregne det daglige vanninntaket
- (2 poeng) Vanninntaket er korrekt lagt inn i oppslagsverkene
- (2 poeng) Alle nøkkel–verdi-parene i oppslagsverkene er korrekte
- (1 poeng) Utskriften fra programmet er en liste med oppslagsverker
Et logistikkselskap har gitt deg data om sine leveringsruter og trenger at du skriver en rapport.
Anta at du har en fil routes.json med innholdet som er vist nedenfor.
{
"1" : { "planned_idx": [...], "actual_idx": [...], "distances": [...] },
"2" : {
"planned_idx": [
0,
1,
2
],
"actual_idx": [
0,
2,
1
],
"distances": [
[
0,
30870,
31775
],
[
31004,
0,
1499
],
[
32054,
1625,
0
]
]
},
...,
"100" : { "planned_idx": [...], "actual_idx": [...], "distances": [...] }
}
I routes.json inneholder hver datapost tre opplysninger: den planlagte ruten som sjåføren fikk fra logistikkfirmaet, ruten som sjåføren faktisk endte opp med å kjøre, og avstandsmatrisen. Hver kunde er identifisert med et unikt id-nummer.
For eksempel, i dataposten “2” angir den planlagte ruten at sjåføren skal levere pakkene i følgende rekkefølge: kunde 0, deretter kunde 1, og til slutt kunde 2. Sjåføren fulgte derimot en annen rute: kunde 0, deretter kunde 2, og til slutt kunde 1. For enkelhets skyld viser vi kun dataposten “2” og representerer innholdet i de andre datapostene med ellipser (…).
Indeksene i avstandsmatrisen representerer kundenes id. Hver rad viser avstandene fra én kunde til alle de andre kundene i ruten. For eksempel, i rad 0 i avstandsmatrisen for dataposten “2”, er avstanden fra kunde 0 til seg selv 0, avstanden fra kunde 0 til kunde 1 er 30870, og avstanden fra kunde 0 til kunde 2 er 31775.
Anta at routes.json inneholder 100 dataposter, og at listene planned_idx og actual_idx har samme lengde i hver datapost. For hver datapost, beregn den totale avstanden for den planlagte ruten og den faktiske ruten ved å bruke den oppgitte avstandsmatrisen. Deretter sammenlignes de to totalsummene, og man holder oversikt over hvor mange ganger:
- den faktiske ruten er kortere enn den planlagte ruten,
- den planlagte ruten er kortere enn den faktiske ruten, og
- begge rutene har lik total avstand.
I tillegg ønsker logistikkfirmaet å vite den totale avstanden som ble spart av sjåførene i tilfeller der den faktiske ruten er kortere enn den planlagte. Summer disse besparelsene for alle slike dataposter.
from pathlib import Path
import json
def main():
content_string = Path('routes.json').read_text(encoding = 'utf-8')
content = json.loads(content_string)
planned_shorter = 0
actual_shorter = 0
equal = 0
distance_saved = 0
for data_entry_id in content:
info = content[data_entry_id]
planned_distance, actual_distance = calculate_distances(info["planned_idx"], info["actual_idx"], info["distances"])
if actual_distance < planned_distance:
actual_shorter += 1
distance_saved += (planned_distance - actual_distance)
elif planned_distance < actual_distance:
planned_shorter += 1
else:
equal += 1
print(f'{actual_shorter} routes had a shorter actual route')
print(f'{planned_shorter} routes had a shorter planned route')
print(f'{equal} routes were equal')
print(f'{distance_saved} distance are saved in total')
def calculate_distances(planned, actual, distances):
planned_distance = 0
actual_distance = 0
for i in range(len(planned)-1):
planned_distance += distances[planned[i]][planned[i+1]]
for i in range(len(actual)-1):
actual_distance += distances[actual[i]][actual[i+1]]
return (planned_distance, actual_distance)
if __name__ == '__main__':
main()
- (1 poeng) Les json-filen på fornuftig måte
- (6 poeng) Beregne den totale avstanden for den planlagte ruten og den faktiske ruten for hver datapost. Koden skal kunne håndtere et vilkårlig antall kunder. Men vi trekker ikke poeng hvis koden din bare kan håndtere 3 kunder.
- (2 poeng) Hent listene over planned_idx, actual_idx og distances i en datapost
- (2 poeng) Bruk innholdet i en ruteliste som indekser i den todimensjonale avstandsmatrisen for å hente ut avstanden mellom to kunder.
- (2 poeng) Beregne den totale avstanden for en ruteliste
- (3 poeng) Sammenlign den planlagte ruten og den faktiske ruten for hver datapost, ett sammenligningstilfelle hver
- (2 poeng) Summer opp tallene på tvers av alle datapostene. Siden vi antar at det finnes 100 dataposter i
routes.json, er det greit å definere en løkke som iterere nøyaktig 100 ganger. - (1 poeng) Beregn den totale avstanden som sjåførene sparer
Til slutt gjøres en helhetsvurdering verdt 2 poeng. Sensor vurderer her helheten av besvarelsen og om delene fungerer i sammenheng. For eksempel, sensor vil vurdere om kodestrukturen er god, om koden er lett å lese og forstå, og om det brukes gode variabelnavn. Sensor skal ikke trekke for syntaksfeil dersom intensjonen er tydelig og algoritmen er presist beskrevet, men ser på om programmet som helhet henger sammen og er logisk strukturert.