
Unicode og tekstkoding
Unicode og ordinaler
Som alle andre datatyper i Python er også strenger egentlig representert under panseret som en sekvens av 0 og 1. For eksempel representeres bokstaven 'A' som 1000001 og bokstaven 'B' som 1000010. Hvis vi i stedet for å tolke sekvensen av 0 og 1 som en bokstav later som sekvensen er et tall i totall-systemet, får vi henholdsvis 65 for 'A' og 66 for 'B'.
På denne måten er hvert eneste symbol (bokstav og tegn, emoji og andre symboler som kan opptre i en streng) knyttet til et tall. Dette tallet kalles en ordinal for symbolet. Hvordan symboler matcher ordinaler gjøres i Python på en standardisert måte som kalles Unicode. Unicode er med andre ord en matching mellom ordinal og symbol. Under viser vi et lite utdrag.
| Ordinal | Symbol |
|---|---|
| 65 | 'A' |
| 66 | 'B' |
| 67 | 'C' |
| … | … |
| 90 | 'Z' |
| 198 | 'Æ' |
| 216 | 'Ø' |
| 197 | 'Å' |
| Ordinal | Symbol |
|---|---|
| 97 | 'a' |
| 98 | 'b' |
| 99 | 'c' |
| … | … |
| 122 | 'z' |
| 230 | 'æ' |
| 248 | 'ø' |
| 229 | 'å' |
| Ordinal | Symbol |
|---|---|
| 9 | '\t' (tab) |
| 10 | '\n' (linjeskift) |
| 32 | ' ' (mellomrom) |
| 33 | '!' |
| 48 | '0' |
| 49 | '1' |
| 50 | '2' |
| 128013 | '🐍' |
For å finne ordinalen til et symbol kan vi bruke funksjonen ord:
symbol = 'A'
ordinal = ord(symbol)
print('Ordinal til', symbol, 'er' , ordinal) # Ordinal til A er 65
For å konvertere fra ordinal til symbol («character») kan vi bruke funksjonen chr:
ordinal = 97
symbol = chr(ordinal)
print('Ordinal', ordinal, 'har symbol', symbol) # Ordinalen 97 har symbol a
Tekstkoding
Ett symbol kan representeres som ett tall, som vist i forrige avsnitt. Men hva om det er flere symboler etter hverandre, som i en streng eller en fil med tekst? Fordi det ikke eksisterer noe naturlig «mellomrom» i noe som representeres som en sekvens av 0 og 1, må vi bestemme oss for noen regler for å skille hvor ett symbol slutter fra hvor det neste starter.
Det finnes flere ulike strategier for dette, som vi kaller koding av en streng (engelsk: encoding). Kodinger som støtter alle Unicode-symboler begynner med «UTF» (Unicode Transformation Format).
Eksempler på kodinger:
ASCII er en gammel standard som Unicode-ordinalene er bakoverkompatibel med. Den deler opp sekvensen av 0’er og 1’ere i blokker på akkurat 8 biter, og så tolker den hver blokk som en ordinal oppgitt i totallsystemet. Hver blokk begynner alltid med 0. Eksempler noen ulike symboler og hvordan de kodes i ASCII:
| Symbol | Unicode | Koding i ASCII |
|---|---|---|
| \n | 10 | 00001010 |
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| Æ | 198 | ikke støttet |
| 🐍 | 128013 | ikke støttet |
Den delen av kodingen som er markert i gult over er selve ordinalen (i totallsystemet). Nullene som kommer foran dette bare fyller opp plassen slik at blokken får størrelse på 8 bit.
-
Fordeler med ASCII: lett å forstå og implementere. Bruker lite lagringsplass. Støttes også av svært gamle systemer.
-
Ulemper med ASCII: Støtter kun symboler med unicode-ordinal under 128. Altså ingen støtte for norske bokstaver æ, ø og å.
UTF-32 er en koding som er enkel å forstå (men som i praksis er lite brukt). Den deler opp sekvensen av 0’er og 1’ere i blokker på akkurat 32 biter, og så tolker den hver blokk som en ordinal oppgitt i totallsystemet (akkurat som ASCII, altså, men tar større plass). Eksempler noen ulike symboler og hvordan de kodes i UTF-32:
| Symbol | Unicode | Koding i UTF-32 |
|---|---|---|
| \n | 10 | 00000000000000000000000000001010 |
| A | 65 | 00000000000000000000000001000001 |
| B | 66 | 00000000000000000000000001000010 |
| Æ | 198 | 00000000000000000000000011000110 |
| 🐍 | 128013 | 00000000000000011111010000001101 |
Den delen av kodingen som er markert i gult over er selve ordinalen (i totallsystemet). Nullene som kommer foran dette bare fyller opp plassen slik at blokken får størrelse på 32 bit.
-
Fordeler med UTF-32: lett å forstå og implementere. Man kan raskt finne ut hvilken bokstav som er i en gitt posisjon. Støtter alle Unicode-symboler.
-
Ulemper med UTF-32: bruker mye unødvendig lagringsplass. Ikke bakoverkompatibel med ASCII.
UTF-8 er den vanligste unicode-kodingen. Den deler opp sekvensen av 0’er og 1’ere i blokker på 8 biter; de vanligste symbolene bruker bare én slik blokk, mens de mer sjeldne bruker flere blokker. Eksempler på hvordan noen ulike symboler blir kodet i UTF-8:
| Symbol | Unicode | Koding i UTF-8 |
|---|---|---|
| \n | 10 | 00001010 |
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| Æ | 198 | 11000011 10000110 |
| 🐍 | 128013 | 11110000 10011111 10010000 10001101 |
Den delen av kodingen som er markert i gult over er selve ordinalen (i totallsystemet). Den delen av kodingen som er markert i rødt inneholder informasjon som UTF-8 bruker for å avgjøre hvor mange blokker symbolet består av. De øvrige nullene bare fyller opp plassen slik at hver blokk får en størrelse på 8 bit.
Fordeler med UTF-8
- Bakoverkompatibel med den eldre standarden ASCII.
- Bruker i praksis mye mindre lagringsplass enn UTF-32.
- Støtter alle Unicode-symboler.
- Er de facto standard på internett (HTTP).
Tekstkodingen cp1252 (også kalt Windows-1252 og noen ganger upresist referert til som ISO 8859-1 eller Latin 1) er en tekstkoding som (dessverre) er standard i noen Microsoft-produkter på Windows fremdeles. Enkodingen er i likhet med UTF-8 bakoverkompatibel med ASCII, men er likevel ikke basert på unicode 😡. Selv om den støtter noen flere symboler enn ASCII (som f. eks. de norske bokstavene æ, ø og å), har den likevel et svært begrenset utvalg av mulige symboler i forhold til unicode-baserte tekstkodinger.
Et symbol i cp1252 er kodet som en sekvens av 0’er og 1’ere i blokker på akkurat 8 biter. Eksempler på hvordan noen ulike symboler blir kodet i cp1252:
| Symbol | Ordinal | Koding i cp1252 |
|---|---|---|
| \n | 10 | 00001010 |
| A | 65 | 01000001 |
| B | 66 | 01000010 |
| Æ | 198 | 11000110 |
| 🐍 | 128013 | ikke støttet |
Fordeler med cp1252
- Bakoverkompatibel med ASCII.
- Bruker lite lagringsplass.
- Støtter de norske bokstavene æ, ø og å.
Ulemper med cp1252
- Er ikke basert på unicode; for eksempel er ordinalen for
€(euro-tegnet) 128 i cp1252, mens det i unicode er 8364. - Det er kun støtte for 256 ulike symboler (dobbelt så mange som ASCII, men likevel veldig lite i forhold til unicode-baserte tekstkodinger).
Forskjellen på cp1252 og latin-1/iso-8859-1 er minimal, men cp1252 er bakoverkompatibel med latin-1 og støtter noen få ekstra symboler, for eksempel skråstilte anførselstegn.
Når man leser eller skriver en tekstfil, må man velge hvilken koding man skal benytte.
- For å skrive til fil er valget enkelt: du bør alltid velge UTF-8 med mindre du har helt spesielle grunner til å gjøre noe annet (f. eks. kompabilititet med et gammelt system).
- For å lese fra en fil må du vite hvilken koding som ble brukt da filen ble lagret. Med 80% sannsynlighet er dette UTF-8, men av og til kan det være noe annet – for eksempel er cp1252 ikke helt uvanlig hvis filen ble opprettet på en Windows-maskin av noen som ikke visste helt hva de gjorde. Hvis du ikke vet hva tekstkodingen er, må du dessverre gjette deg frem eller spørre den som har laget filen. Hvis du får rare tegn i stedet for norske bokstaver, er det sannsynligvis fordi du har gjettet feil. Da kan du prøve å gjette på en annen koding.
Hvis du ikke vet hvilken koding som er brukt, prøv disse tekstkodingene først:
- UTF-8 (anbefalt)
- latin-1 (også kalt ISO-8859-1)
- cp1252 (også kalt Windows-1252)
- UTF-16
- UTF-32
Hvis teksten er på et spesielt språk og ingen av unicode-kodingene (utf-XX) fungerer, kan du også søke på internett etter kodinger som er vanlige for språket. Det er en stor jungel av tekstkodinger tilpasset symboler fra forskjellige språk: for eksempel er cp1251 (også kalt Windows-1251) et alternativ til cp1252 som er tilpasset kyrillisk tekst (russisk etc.), mens cp865 (også kalt IBM865) er et sjeldent benyttet alternativ som er spesielt tilpasset norsk og dansk. Liste over alle tekstkodinger som støttes av Python finner du her.
from pathlib import Path
# Eksempel på å skrive til en fil
text_w = 'Dette er en tekst. Den har æøå og 🐍 i seg.'
Path('myfile.txt').write_text(text_w, encoding='utf-8')
# Eksempel på å lese fra en fil
text_r = Path('myfile.txt').read_text(encoding='utf-8')
print(text_r) # Dette er en tekst. Den har æøå og 🐍 i seg.
Dersom du ikke angir noe for
encoding=vil Python bruke standarden for ditt operativsystem. Dette er vanligvisutf-8på Mac og Linux, ogcp1252på Windows, men kan også variere basert på «locale» -konfigurasjonen av operativsystemet (språk, etc.). Det er derfor lurt å alltid spesifisereencoding=når du skriver til/leser fra filer, slik at du ikke får problemer når du bytter datamaskin.
Sammenblanding av tekstkodinger
Dersom man åpner en fil med feil tekstkoding, vil innholdet tolkes feil, eller det kan oppstå feilmeldinger.
Anta at vi har tekstfiler sample_utf8.txt og sample_cp1252.txt som begge inneholder samme innhold, men er lagret med ulike tekstkodinger (høyreklikk på link og velg «lagre link som» eller lignende for å laste ned). Innholdet i filene er identisk:
blåbærsyltetøy
Avhengig av hvilken tekstkoding vi bruker når vi leser filene, vil vi få ulike resultater (kan avvike noe avhengig av hvilket program du benytter for å lese filene):
| Lest med UTF-8 | Lest med cp1252 | |
|---|---|---|
| Fil lagret med UTF-8 | blåbærsyltetøy |
blåbærsyltetøy |
| Fil lagret med cp1252 | bl�b�rsyltet�y |
blåbærsyltetøy |
Prøv å lese begge filene over i nettleseren (klikk på linkene over på vanlig måte uten å laste dem ned). Hvilken av filene ser riktig ut? Hvilken ser feil ut? Hvorfor? Hvilken tekstkoding benytter nettleseren når den leser filene?
Dersom du åpner en tekstfil i VSCode vil programmet vise på linjen nederst til høyre hvilken tekstkoding som benyttes for å lese filen som vises (f. eks. UTF-8 eller Windows-1252). Om du klikker der, kan du velge å åpne eller lagre filen med en annen tekstkoding.
Tips: for best mulig kompatibilitet, bør du alltid velge UTF-8 når du lager nye filer. Hvis du ser at filen din ser riktig ut i en annen tekstkoding, anbefaler jeg å velge «Save with encoding» og lagre filen på nytt med UTF-8. Dette gjelder også kildekoden til Python-filer du skriver.
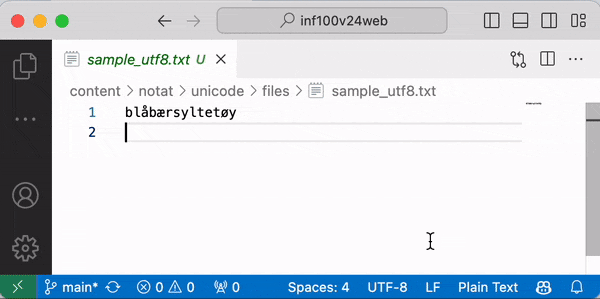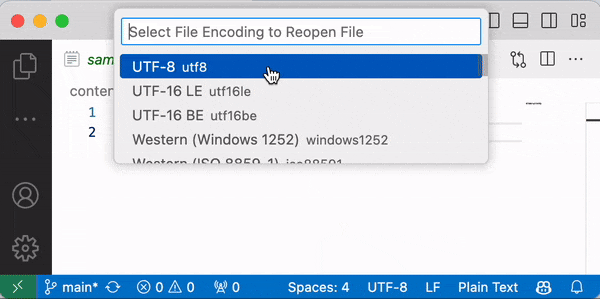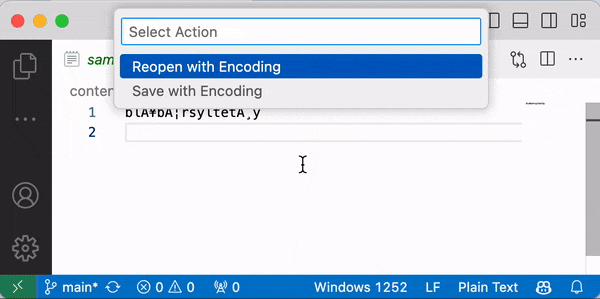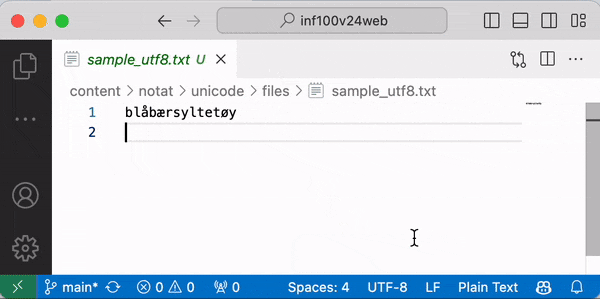
Når vi i våre Python-program leser filer og spesifiserer feil tekstkoding, får vi akkurat samme problemer som vi ser over. Merk:
- å lese med cp1252 en fil som egentlig er kodet i utf-8 krasjer ikke, men vil feile i stillhet;
- å lese med utf-8 en fil som egentlig er kodet i cp1252 vil ofte (men ikke alltid) resultere i at programmet krasjer.
from pathlib import Path
print(Path('sample_utf8.txt').read_text(encoding='utf-8')) # blåbærsyltetøy
print(Path('sample_utf8.txt').read_text(encoding='cp1252')) # blåbærsyltetøy
print(Path('sample_cp1252.txt').read_text(encoding='utf-8')) # --> krasjer <--
print(Path('sample_cp1252.txt').read_text(encoding='cp1252')) # blåbærsyltetøy
Fordi både UTF-8, cp1252 og latin-1 er bakoverkompatible med ASCII, vil filer som kun inneholder ASCII-symboler være helt identiske enten de er lagret med UTF-8 eller cp1252 eller latin-1. Dette er grunnen til at man av og til ønsker å begrense seg til å kun bruke ASCII-symboler såfremt det ikke medfører noen andre ulemper.