
Prøveeksamen
| 26. april 2024 |
| 4 timer |
| Lukket digital eksamen (med safe exam browser). |
| Alle skrevne og trykte hjelpemidler tillatt. |
Oppgavetekster, løsningsforslag og sensorveiledning finner du på denne siden.
Fordi eksamen var en lukket digital eksamen uten tilgang til å kjøre koden eller bruke internett, bes sensor ikke gi poengtrekk for forhold som enkelt ville blitt oppdaget og raskt rettet ved kjøring av koden. Dette inkluderer blant annet:
- manglende
import-setninger, - manglende kodeord (som f. eks. manglende
defforan funksjonsdefinisjoner), - feil navn på funksjoner og metoder i standardbiblioteket, i egen kode eller i eksterne moduler (såfremt det fremgår noenlunde av funksjonsnavnet hva kandidaten egentlig mener),
- feil navn på variabler (f. eks. kalle den samme variabelen både
totalogsumi ulike deler av koden), - enkle syntaks-feil (f. eks. manglende kolon etter
if-setninger), - og så videre.
Logiske feil skal det likevel (som hovedregel) bli trukket litt for; selv om man kunne ha oppdaget at noe var feil ved kjøring av koden. Dette inkluderer blant annet:
presedensfeil,
forveksling av indekser og elementer,
off-by-one -feil,
feil i algoritmer,
og så videre.
1 Automatisk rettet
- For å lese oppgavene uten fasit, se oppgavesettet over.
- Fasit for automatisk rettede oppgaver: pdf
2 Forklaring
Tidemann held på med lab5 (Snake), men har gjort noko feil i steget der han skal teikna eit rutenett. Når test-programmet hans view_test.py køyrer, blir programmet til venstre vist, sjølv om han eigentleg skulle ønske at det såg ut som programmet til høgre. Det kjem ingen feilmeldingar i terminalen.
 |  |
Kva har Tidemann gjort feil? Les koden hans, og forklar:
- kva han har gjort feil,
- kvifor feilen fører til åtferda som blir vist, og
- kva han kan gjera for å retta feila.
Maks 400 ord.
Tidemann har gjort flere feil:
I snake_view.py på linje 11 i funksjonen draw_board er det oppgitt at løkken skal gå gjennom elementene i
range(rows). Dette fører til at det blir tegnet for få kolonner i rutenettet. For å rette feilen, endre linje 11 slik at løkken går igjennom elementene irange(cols)i stedet.I snake_view.py, på linje 32-33 i funksjonen get_color angis det at fargen skal være oransje dersom den innkommende verdien er større enn eller lik 0. Dette fører til at funksjonen vil returnere fargen oransje selv om verdien er
0, som ikke er riktig oppførsel, og vi ser på bildet at hele brettet tegnes i den oransje fargen, også der det skulle vært grå. Dette problemet kan løses på (minst) tre ulike måter, og ideelt sett burde man gjøre alle disse rettelsene (selv om hvert enkelt grep i seg selv er egentlig er tilstrekkelig for rette funksjonaliteten):- I stedet for å sammenligne med
>=, burde man sammenlignet med>. Da ville ikke kroppen til denne if-setningen bli utført, og det er istedet den lysegrå fargen som blir angitt til color-variabelen tidligere i funksjonen (linje 30-31) som gjør seg gjeldende. - I stedet for å angi verdi til en variabel
colorsom returneres på slutten av funksjonen, kunne man returnert verdier direkte inne i if-blokkene. Da ville funksjonen returnert allerede i den første if-blokken. - I stedet for å benytte flere if-setninger, burde man benyttet seg av én if-setning med flere elif-ledd; altså endre
ifpå linje 32 tilelif. Da ville color-variabelen blitt angitt kun i det første leddet av if-elif-sekvensen.
- I stedet for å sammenligne med
I snake_view.py, på linje 22-26 i funksjonen draw_board tegnes debug-informasjon for en celle i en if-setning; men denne if-setningen har et innrykk for lite, og utføres derfor kun én gang for hver rad, etter at den innerste løkken er ferdig utført. Variablene x_left, x_right, y_top og y_bottom vil fortsatt ha de verdiene de fikk i siste iterasjon av den innerste løkken, som er ansvarlig for å tegne siste kolonne i raden. Derfor tegnes debug-informasjonen kun for den siste kolonne. For å rette koden, må innrykket på linjene 22-26 økes med ett innrykk (fire mellomrom).
- For få kolonner (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- For mye oransje (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- Debug vises kun for siste kolonne (2 poeng)
- Identifiserer at dette er et problem.
- Foreslår funksjonell løsning for hva som kan gjøres for å rette problemet.
- Helhetsvurdering (4 poeng)
Meningsfulle forklaringer av sammenheng mellom kode og resultatbilde.
Gode bruk av faguttrykk.
Finner ikke feil som ikke er feil.
| |
Koden over skal telle hvor mange ganger tegnet 'a' opptrer i en streng s, men det virker ikke.
Finn alt som er feil, og beskriv hva man kan gjøre for å fikse funksjonen.
Ca to-tre avsnitt, helst ikke mer enn 200 ord.
Feil i funkjsonen count_a:
- Innrykket på linje 5 er feil. Det skal være på samme nivå som linje 2 og 3 (to mellomrom må altså fjernes).
- Løkken går over indeksene til strengen s, men på linje fire benyttes iteranden c som om den var et tegn i strengen. Dette kan fikses ved å endre
count[c] += 1tilcount[s[c]] += 1, eller ved å endrefor c in range(len(s))tilfor c in s. Variabelnavnet «c» tyder på at det er den sistnevnte løsningen som var ment, sidencer en vanlig betegnelse for en karakter i en streng, mensier en vanlig betegnelse for en indeks. - Programmet vil krasje dersom s inneholder et annet tegn enn
'a', sidencounter et oppslagsverk som kun inneholder nøkkelen'a'før løkken begynner. Dette kan fikses inne i løkken ved å enten- ignorere alle tegn som ikke er ‘a’ (
if c != 'a': continue), eller - som første steg inne i løkken, opprette en nøkkel for c i count med verdien 0 dersom c ikke allerede er en nøkkel i count (
if c not in count: count[c] = 0).
- ignorere alle tegn som ikke er ‘a’ (
- 2 poeng: feil innrykk og riktig løsning på dette.
- 2 poeng: iteranden i løkken brukes feil, og god løsning på dette.
- 3 poeng: krasjer dersom s inneholder et annet tegn enn
'a'og god løsning på dette. - 3 poeng: helhetsvurdering (god bruk av fagbegreper, påstander gir mening, forståelse er korrekt etc).
Othilie har lese seg opp om oppslagsverk, og har lagt merke til at dei er muterbare. Men kva innberar eigentleg det? Kva omsyn må Othilie ta med muterbare objekter, som kanskje ikkje ville vore nødvendig elles?
Gi ei forklaring til Othilie med illustrerande døme, kor døme er basert på oppslagsverk. Me forventar ca 3-4 avsnitt, ikkje meir enn 600 ord.
En verdi er muterbar hvis det er mulig å endre på selve verdien i minnet etter at den har blitt opprettet første gang. Når Othilie arbeider med muterbare verdier, må hun være oppmerksom på at endringer i verdien vil påvirke alle referanser (aliaser) til den verdien. Dette kan føre til uventede bugs hvis én del av kildekoden tror det er greit å mutere verdien, mens en annen del av kildekoden ikke er klar over at verdien muteres.
Et eksempel: anta at Othilie har et oppslagsverk som inneholder karakterkortet hennes:
othilie_grades = {'Skriving': 5, 'Lesing': 4 }
Othilie lurer på hva snittkarakteren hennes blir hvis hun får karakteren x i sitt neste fag. Hun skriver derfor følgende funksjon:
def ave_if_adding_grade_x(grades, x):
grades['new_grade'] = x
# OBS! operasjonen over muterer grades!
# men det er i det minste lett å regne ut gjennomsnittet nå:
return sum(grades.values()) / len(grades)
Når Othilie tester funksjonen, ser det ut som den fungerer som den skal:
print('Testing ave_if_adding_grade_x...', end=' ')
assert 5.0 == ave_if_adding_grade_x(othilie_grades, 6)
assert 4.0 == ave_if_adding_grade_x(othilie_grades, 3)
print('OK') # Tjohei, testene passerer!
Men når Othilie nå ser på karakterkortet sitt, ser hun at det har skjedd noe rart:
print(othilie_grades)
Gir utskriften
{'Skriving': 5, 'Lesing': 4, 'new_grade': 3}
Det som har skjedd, er at funksjonen ave_if_adding_grade_x muterer grades slik at det blir enklere å deretter regne ut gjennomsnittet. Det man ikke tenkte på, var at grades i ave_if_adding_grade_x er et alias til othilie_grades i hovedprogrammet, slik at enhver mutasjon av grades også vil reflekteres i othilie_grades.
Generelt når man benytter seg av verdier som er av en muterbar type, må man være bevisst på hvorvidt det finnes andre referanser/aliaser til verdien og hvilken rolle den spiller der før man bestemmer seg for å mutere den.
- 2 poeng: meningsfull definisjon («En verdi er muterbar dersom selve objektet kan endres uten å opprette en ny verdi i minnet») eller lignende.
- 2 poeng: meningsfullt svar på hvilke hensyn man må ta («Man må være bevisst på hvorvidt det finnes andre referanser/aliaser til en verdi før man bestemmer seg for å mutere den») eller lignende.
- 2 poeng: eksempel basert på oppslagsverk, ikke kun lister.
- 2 poeng: meningsfull drøfting av aliaser/to variabler som peker til samme objekt, eventuelt et godt eksempel som illustrerer dette.
- 2 poeng: helhetsvurdering (bruk av fagbegreper, påstander gir mening, forståelse er korrekt etc).
3 Kodeskriving
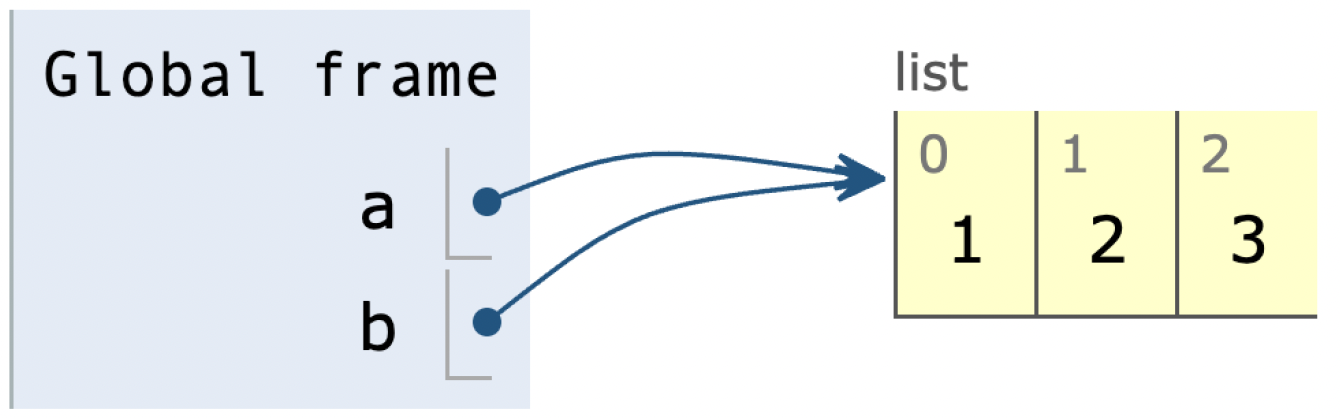
Opprett to variabler a, og b som refererer til den samme listen, slik at minnets tilstand blir som vist på bildet over.
Klikk på «se steg» -knappen for å verifisere at denne koden gir riktig bilde av minnet.
a = [1, 2, 3]
b = a
- 1 poeng hvis
aer korrekt (a == [1, 2, 3]). - 1 poeng hvis
aer likb(a == b). - 2 poeng hvis
aogbviser til samme objekt (a is b).
Sensor har anledning til å gjøre en skjønnsmessig justering i tilfeller der det er gjort feil disse testene ikke tar høyde for. Poengsummen som beskrevet over kan regnes ut med følgende kode:
points = sum([
a == [1, 2, 3],
a == b,
(a is b) * 2,
])
# PS: i kontekst av matematisk aritmetikk regnes True som 1 og False som 0.
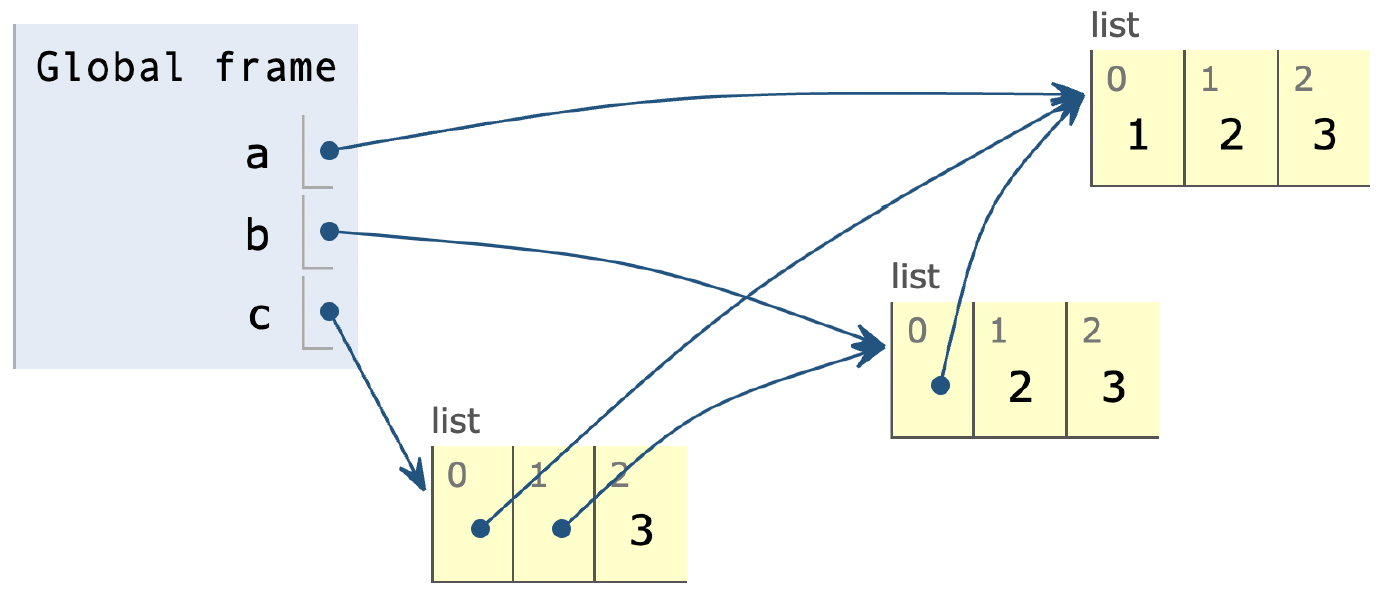
Opprett tre variabler a, b og c slik at minnets tilstand blir som vist på bildet over.
Klikk på «se steg» -knappen for å verifisere at denne koden gir riktig bilde av minnet.
a = [1, 2, 3]
b = [a, 2, 3]
c = [a, b, 3]
- 1 poeng hvis
aer korrekt (a == [1, 2, 3]). - 1 poeng hvis
ber korrekt (b == [[1, 2, 3], 2, 3]). - 1 poeng hvis
aer første element i b (a is b[0]). - 1 poeng hvis
aer første element i c (a is c[0]). - 1 poeng hvis
ber lik c[1] (b == c[1]). - 1 poeng hvis
ber viser til samme element som c[1] (b is c[1]).
Sensor har anledning til å gjøre en skjønnsmessig justering i tilfeller der det er gjort feil disse testene ikke tar høyde for. Poengsummen som beskrevet over kan regnes ut med følgende kode:
points = sum([
a == [1, 2, 3],
b == [[1, 2, 3], 2, 3],
a is b[0],
a is c[0],
b == c[1],
b is c[1],
])
# PS: i kontekst av matematisk aritmetikk regnes True som 1 og False som 0.
I denne oppgaven skal du lage fem funksjoner som del av et rapporteringssystem fra et idrettsstevne «Nyttårsløpet 2017» som finner sted 31. desember 2017.
Funksjonene skal operere på en liste av deltakere. Hver deltaker i listen er igjen representert som en liste av 5 elementer: en streng som inneholder fornavn, en streng som inneholder etternavn, en bokstav som representerer kjønn (‘K’ for kvinne og ‘M’ for mann), et heltall som er fødselsåret, og en streng som representerer tiden vedkommende klarte å gjennomføre en halvmaraton på. (‘1:59:20’ betyr 1 time, 59 minutter og 20 sekunder.) Et eksempel på en slik liste av lister er som følger:
data = [
['Kari', 'Hansen', 'K', 1969, '1:59:20'],
['Eli', 'Nansen', 'K', 1975, '1:49:46'],
['Karl', 'Jansen', 'M', 1985, '1:35:40'],
['Erik', 'Karlsen', 'M', 1970, '1:40:48'],
['Anne', 'Jensen', 'K', 1964, '2:03:09'],
['Kurt', 'Johnsen', 'M', 1987, '1:32:43'],
['May', 'Berntsen', 'K', 1989, '1:36:54'],
['Jan', 'Thorsen', 'M', 1990, '1:45:24'],
['Hans', 'Monsen', 'M', 1998, '1:25:05'],
]
Som del av rapporteringssystemet skal du lage følgende fem Python-funksjoner.
Funksjonen time er en hjelpefunksjon til winners.
group
Parametre:
dataen liste av lister som representerer resultatene fra et idrettsstevne som beskrevet over.genderen streng som enten er'K'eller'M'.age_loweren int som representerer nedre aldersgrense (inklusiv)age_upperen int som representerer øvre aldersgrense (eksklusiv)
Returverdi: ingen
Sideeffekter:
- Alle deltakere i
datasom har kjønngenderog som har alder mellomage_lowerogage_upperpå arrangementsdagent skal skrives ut på formatetfornavn etternavn (alder) tidpå hver sin line.
Eksempelutskrift for et kall til group(data, 'K', 25, 50) gitt data som beskrevet over:
Kari Hansen (48) 1:59:20
Eli Nansen (42) 1:49:46
May Berntsen (28) 1:36:54
search
Parametre:
dataen liste av lister som representerer resultatene fra et idrettsstevne som beskrevet over.worden streng som skal søkes etter.
Returverdi:
- en liste som representerer deltakerne fra
datahvorwordfinnes i enten fornavnet eller etternavnet til deltakeren. Formatet på resultatlisten skal være akkurat den samme som fordata, altså en liste av lister.
Sideeffekter: ingen
Eksempel på tester:
# Test 1
actual = search(data, 'Hans')
expected = [
['Kari', 'Hansen', 'K', 1969, '1:59:20'],
['Hans', 'Monsen', 'M', 1998, '1:25:05'],
]
assert expected == actual
# Test 2
actual = search(data, 'M')
expected = [
['May', 'Berntsen', 'K', 1989, '1:36:54'],
['Hans', 'Monsen', 'M', 1998, '1:25:05'],
]
assert expected == actual
winners
Parametre:
dataen liste av lister som representerer resultatene fra et idrettsstevne som beskrevet over.
Returverdi: ingen
Sideeffekter:
- Den raskeste mannen og den raskeste kvinnen skal skrives ut på hver sin linje på formatet vist i eksempelet under.
Eksempelutskrift for et kall til winners(data) gitt data som i eksempelet over:
The fastest woman is May Berntsen with time 1:36:54
The fastest man is Hans Monsen with time 1:25:05
time
Parametre:
sen streng på formatetH:MM:SSsom representerer en tid hvor H er antall timer, MM er antall minutter og SS er antall sekunder.
Returverdi:
- En int for antall sekunder som tilsvarer tiden
s.
Sideeffekter: ingen
Dersom s ikke er på riktig format skal funksjonen krasje.
Eksempel på test:
actual = time("1:59:20")
expected = 7160
assert expected == actual
save_file
Parametre:
dataen liste av lister som representerer resultatene fra et idrettsstevne som beskrevet over.filenameen streng som representerer filnavnet som resultatene skal lagres i.
Returverdi: ingen
Sideeffekter:
- Resultatene i
dataskal lagres i filenfilenamei et CSV-format hvor verdier separeres med semikolon. Første linje skal inneholde egnede overskrifter. De neste radene i filen skal inneholde fornavn, etternavn, kjønn, fødselsår og tid for hver av deltakerne.
# Del 1
def group(data, gender, age_lower, age_upper):
for p_first, p_last, p_gender, p_birth_year, p_time in data:
age = 2017 - p_birth_year
if (gender == p_gender) and (age_lower <= age < age_upper):
print(f'{p_first} {p_last} ({age}) {p_time}')
# Del 2
def search(data, word):
result = []
for p in data:
p_first, p_last, *__ = p
if (word in p_first) or (word in p_last):
result.append(p)
return result
# Del 3
def winners(data):
woman_winner = get_fastest(data, 'K')
first, last, *__, time = woman_winner
print(f'The fastes woman is {first} {last} with time {time}')
man_winner = get_fastest(data, 'M')
first, last, *__, time = man_winner
print(f'The fastes man is {first} {last} with time {time}')
def get_fastest(data, gender):
best_person = []
best_time = None
for person in data:
*__, p_gender, __ , p_time = person
if p_gender != gender:
continue
seconds = time(p_time)
if (best_time is None) or (seconds < best_time):
best_time = seconds
best_person = person
return best_person
# Del 4
def time(s):
h, mm, ss = s.split(':')
return int(h) * 60 * 60 + int(mm) * 60 + int(ss)
# Del 5
def save_file(data, filename):
with open(filename, 'wt', encoding='utf-8') as f:
f.write('fornavn;etternavn;kjønn;fødselsår;tid\n')
for p in data:
f.write(';'.join([str(x) for x in p]))
f.write('\n')
Alle poeng tildeles ved skjønssmessig vurdering.
- 5 poeng: group
- 1 poeng: løkke over data
- 1 poeng: hente ut fødselsår for elementene i løkken
- 1 poeng: meningsfull betingelse
- 2 poeng: helhetsvurdering
- 5 poeng: search
- 1 poeng: løkke, hente ut årstall for person og regne ut alder
- 1 poeng: bruk av append eller tilsvarende på resultat-liste
- 1 poeng: meningsfull betingelse uten presedensfeil
- 2 poeng: helhetsvurdering
- 5 poeng: winners
- 2 poeng: filtrerer på kjønn
- 2 poeng: finner raskeste
- 1 poeng: helhetsvurdering
- 5 poeng: time
- 1 poeng: isolerer timer, minutter, sekunder i streng
- 1 poeng: konverterer til int
- 1 poeng: regnestykke er rimelig
- 2 poeng: helhetsvurdering
- 5 poeng: save_file
- 1 poeng: åpner fil på fornuftig måte
- 1 poeng: header
- 1 poeng: løkke
- 2 poeng: helhetsvurdering