
Eksamen
| 15. mai 2025 |
| 4 timer |
| Lukket digital eksamen (med safe exam browser). |
| Tillatte hjelpemiddel: bøker fra litteraturlisten og opp til 6 tosidige A4 ark med egne notat. |
- Oppgavesett fra Inspera: bokmål (pdf), nynorsk (pdf)
- Vedlegg til oppgave 2b, 2c og 2d (pdf)
- Vedlegg til oppgave 3b, 3c og 3d (pdf)
- Kursnotater tilgjengelige som pdf under eksamen (pdf)
Oppgavetekster, løsningsforslag og sensorveiledning finner du på denne siden.
Fordi eksamen var en lukket digital eksamen uten tilgang til å kjøre koden eller bruke internett, bes sensor ikke gi poengtrekk for forhold som enkelt ville blitt oppdaget og raskt rettet ved kjøring av koden. Dette inkluderer blant annet:
- manglende
import-setninger, - Feilstavede kodeord eller syntaks inspirert av andre programmeringsspråk (for eksempel hvis kandidaten skriver
funi stedet fordefved funksjonsdefinisjoner), - feil navn på funksjoner ved funksjonskall til egne funksjoner, innbygde funksjoner eller til funksjoner fra importerte moduler (såfremt det fremgår av funksjonsnavnet hva kandidaten egentlig mener – for eksempel hvis studenten har definert en funksjon som heter
rise_upmen kaller en funksjon som heterstand_upblir det ikke trekk for dette), - feil navn på variabler (f. eks. kalle den samme variabelen både
totalogsumi ulike deler av koden), - enkle syntaks-feil (f. eks. manglende kolon etter
if-setninger), - og så videre.
Logiske feil skal det likevel bli trukket for; selv om man kunne ha oppdaget at noe var feil ved kjøring av koden. Dette inkluderer blant annet:
presedensfeil,
forveksling av indekser og elementer,
off-by-one -feil,
setninger plassert med feil innrykk,
feil grunnet for tidlig return,
feil i algoritmer,
og så videre.
1 Automatisk rettet
- For å lese oppgavene uten fasit, se oppgavesettet over.
- Fasit for 1a, 1b, 1c, 1d fra Inspera: bokmål, nynorsk
x = 2
y = '2'
a = [-2, x, y]
Anta at kodesnutten over har blitt kjørt, og at en av setningene under er den neste setningen som utføres. Hva skrives ut? Hvis programmet krasjer, skriv kun Error.
(Husk at apostrofer og hermetegn som omgir strenger i kildekoden ikke er blir inkludert i utskriften.)
print(x) | |
print(y) | |
print('a') | |
print(a[1]) | |
print(y + y) | |
print(a[1] + x) | |
print(a[a[1]] * 3) |
Klikk på de grå feltene for å se svaret.
x = 2
y = '2'
a = [-2, x, y]
expressions = '''\
print(x)
print(y)
print('a')
print(a[1])
print(y + y)
print(a[1] + x)
print(a[a[1]] * 3)
'''
for expression in expressions.splitlines():
print(f'{expression:24}--> ', end='')
try:
eval(expression)
except Exception:
print('Error')
For å se fasit, klikk «kjør».
a = 2
b = 2
a = a + b
b = a + b
a += 1
print(b - a)
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
For å se fasit, klikk «kjør».
def incremented(x):
x += 1
return x
def foo(x):
x = incremented(x)
y = incremented(x)
return x + y
x = 3
x = foo(x)
print(x)
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
For å se fasit, klikk «kjør».
a = ['a', 'b', 'c', 'd', 'e', 'f']
n = len(a) // 2
for i in range(n):
x = a[i]
a[i] = a[i*2]
a[i*2] = x
r = ''
for c in a:
r += c
print(r)
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
For å se fasit, klikk «kjør».
Oppgave 1(e) og 1(f) ba kandidatene om å skrive korte kodesnutter. Noen tester var oppgitt, og man kunne teste/kjøre koden sin underveis på eksamen i disse oppgavene. Kandidatene fikk vite umiddelbart om koden man skrev passerte de oppgitte testene. De fikk ikke ikke vite resultatet på de hemmelige testene (som også måtte passeres for å få poeng på oppgaven).
Skriv en funksjon is_overweight med to parametre height og weight. Du kan anta at «height» og «weight» viser til tallverdier for respektivt en persons høyde (i meter) og tyngde (i kilogram). Funksjonen skal returnere True hvis personen er overvektig, og False hvis ikke.
En person er overvektig dersom kroppsmasseindeksen (KMI) til personen er 25 eller høyere. KMI er definert som KMI = vekt(kg) / høyde(m)^2
For å få uttelling på denne oppgaven må alle testene (inkludert hemmelige tester) passere.
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | is_overweight(1.80, 120) | True |
| 2 | is_overweight(2.00, 100) | True |
| 3 | is_overweight(2.01, 100) | False |
| 4 | is_overweight(2.00, 99) | False |
# Din kode her:
def is_overweight(height, weight):
...
I tillegg til de synlige testene, måtte koden også passere de hemmelige testene for at den skulle gi poeng. De hemmelige testene var:
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | is_overweight(1.60, 60) | False |
| 2 | is_overweight(3.60, 200) | False |
| 3 | is_overweight(3.60, 2000) | True |
def is_overweight(height, weight):
bmi = weight / height ** 2
return bmi >= 25
Skriv en funksjon starts_with_h med en parameter animals. Du kan anta at «animals» peker til en liste med strenger. Funksjonen skal returnere en ny liste som inneholder alle dyrene som begynner på bokstaven ‘h’.
For å få uttelling på denne oppgaven må alle testene (inkludert hemmelige tester) passere.
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | starts_with_h([‘horse’, ‘cow’, ‘hyena’]) | [‘horse’, ‘hyena’] |
| 2 | starts_with_h([‘dog’, ‘cow’, ‘cat’]) | [] |
| 3 | starts_with_h([‘dog’, ‘seahorse’, ‘horse’]) | [‘horse’] |
# Din kode her:
def starts_with_h(animals):
...
I tillegg til de synlige testene, måtte koden også passere de hemmelige testene for at den skulle gi poeng. De hemmelige testene var:
| Test case # | Input | Forventet output |
|---|---|---|
| 1 | starts_with_h([‘cow’, ‘horse’, ‘hen’, ‘dog’, ‘haa’]) | [‘horse’, ‘hen’, ‘haa’] |
| 2 | starts_with_h([‘haa’, ‘ooh’]) | [‘haa’] |
def starts_with_h(animals):
result = []
for animal in animals:
if animal[:1] == 'h':
result.append(animal)
return result
def starts_with_h(animals):
return [animal for animal in animals if animal[:1] == 'h']
2 Forklaring
| |
Når programmet over kjøres, krasjer det med feilmeldingen:
File "/path/to/foo.py", line 2
int(x) = input('Det første tallet: ')
^^^^^^
SyntaxError: cannot assign to function call here. Maybe you meant '==' instead of '='?
Deloppgave i:
- Forklar i korthet hva som er feil og hvordan programmet kan rettes.
Avhengig av hvilken tankefeil vi har gjort, er det ikke alltid forklaringsteksten i feilmeldingen og løsningsidéen den gir oss er spesielt hjelpsomme. Feilmeldingen sier likevel noe om hva som har gått galt.
Deloppgave ii:
- Forklar hvorfor det står «cannot assign to function call» i feilmeldingen.
Maksimalt 300 ord.
Deloppgave (i)
Når programmet leser input fra brukeren med input() vil resultatet alltid være en streng. Derfor ønsker programmet å konvertere til typen int, slik at tallet brukeren skrev kan benyttes i matematiske operasjoner senere. Syntaksen er imidlertid feil; konverteringen må gjøres på høyre side av tilordningssymbolet =. En riktig linje vil se slik ut:
x = int(input('Det første tallet: '))
Merk at identisk feil er gjort på linje 3 også. Samme rettelse må gjøres der.
Deloppgave (ii)
Når Python-fortolkeren leser linje 2, tolker den int(x) i begynnelsen av linje 2 som et funksjonskall. Dette gir mening, siden det er akkurat slik funksjonskall ser ut: først navnet på funksjonen, og deretter parenteser; mellom parentesene er eventuelle argumenter. Når man tilordner verdier med = trenger vi imidlertid at venstre side er en variabel (eller en annen slags referanse, f. eks. en listeposisjon).
Et funksjonskall er ikke samme type ting som en variabel og vil ikke kunne evaluere til en variabel. Funksjonskall evaluerer bare til objekter/verdier. Det gir derfor ikke mening å tilordne en verdi til et funksjonskall. Input til et funksjonskall gis som argumenter, ikke ved å bruke =.
Deloppgave (i) (4 poeng)
- Programmet forsøker å konvertere streng til int (2 poeng)
- Korrekt rettelse (2 poeng)
Deloppgave (ii) (4 poeng)
int(x)har syntaksen til å være et funksjonskall (2 poeng)- tilordning med
=krever at venstre side er en variabel, eller annen type referanse (men ok å bare nevne variabel) (2 poeng)
Helhetsvurdering (2 poeng)
Poengene i denne kategorien deles ut helhetlig, ikke punkt for punkt. Sensor kan bruke dennne kategorien for å trekke opp eller ned kandidater som demonstrerer større eller mindre forståelse enn hva rubrikken forøvrig tilsier. Sensor ser etter:
- Det er lett å forstå hva kandidaten mener.
- God/relevant bruk av faguuttrykk der det er formålstjenelig.
- Demonstrerer generelt god forståelse.
Oppgave 2b, 2c og 2d omhandler alle det samme mystiske programmet.
Anta at du har en fil foo.csv med innholdet under.
name,discipline,value,unit
Kari,long jump,5,m
Per,long jump,500,cm
Pål,long jump,5000,mm
Espen,standing long jump,123,cm
Du kjører programmet under. Hva blir innholdet i bar.csv?
| |
name,m
Kari,5.0
Per,5.0
Pål,5.0
Espen,1.23
Maksimalt 4 poeng. Poengene gis av sensor som en helhetsvurdering. Det gis kun 4 poeng dersom svaret er nøyaktig riktig. Hvis ikke kan man få opp til 3 poeng:
- 1 poeng: kandidaten skjønner at verdier konverteres til meter
- 1 poeng: kandidaten skjønner at kolonnene i bar.csv er «name» og «m»
- 1 poeng: det er akkurat én rad i bar.csv for hver rad i foo.csv i samme rekkefølge.
Dersom sensor mener en besvarelse demonstrerer vesentlig mer eller mindre forståelse enn rubrikken legger opp til, kan hen gjøre en skjønnsmessig justering av poengkarakter.
Oppgave 2b, 2c og 2d omhandler alle det samme mystiske programmet.
Programmet under har dårlige variabelnavn, som gjør det vanskelig å lese og forstå. Forklar rollen til de ulike variablene i koden, og foreslå nye, selvbeskrivende navn for variabel- og funksjonsnavn.
PS: svar gjerne med en tabell (kopier den inn i svaret ditt og fyll den ut):
| Org. navn | Nytt navn | Forklaring av variabelens rolle |
| a | ||
| b | ||
| c | ||
| d | ||
| e | ||
| f | ||
| g | ||
| h |
| |
| Org. navn | Nytt navn | Forklaring av variabelens rolle |
| a | org_csv_content | Hele innholdet i foo.csv som en stor streng. |
| b | org_csv_reader | Innholdet i foo.csv men representert som et «DictReader» -objekt. Vi kan tenke på objektet som en slags liste av oppslagsverk. |
| c | result_rows | En liste vi fyller opp med oppslagsverk som til syvende og sist vil utgjøre radene med data i den nye CSV-filen. |
| d | org_row | Et oppslagsverk som representerer én rad med data fra den opprinnelige filen foo.csv. I hver iterasjon av løkken vil variabelen vise til en ny rad. |
| e | unit | En streng som representerer verdien fra «unit»-kolonnen i foo.csv for den raden som er aktuell i hver iterasjon av løkken. |
| f | value | Et flyttall som representerer verdien fra «value»-kolonnen i foo.csv for den raden som er aktuell i hver iterasjon av løkken. |
| g | result_paper | I denne konteksten kan vi tenke på et StringIO-objekt som en slags muterbar streng. Vi bruker den til å bygge den strengen som skal bli innholdet i resultatet bar.csv. Vi kan også forestille oss at det er som «papiret» resultatet skrives på. |
| h | result_writer | Vi bruker DictWriter-objektet til å konvertere result_rows (en liste av oppslagsverk) til CSV-formatet (en streng med komma-separerte verdier). |
from csv import DictReader, DictWriter
from io import StringIO
from pathlib import Path
org_csv_content = Path('foo.csv').read_text(encoding='utf-8')
org_csv_reader = DictReader(StringIO(org_csv_content), delimiter=',')
result_rows = []
for org_row in org_csv_reader:
unit = org_row['unit']
value = float(org_row['value'])
if unit == 'cm':
value /= 100
elif unit == 'mm':
value /= 1000
elif unit != 'm':
raise ValueError('I love crashing!')
result_rows.append({
'name': org_row['name'],
'm': value
})
result_paper = StringIO()
result_writer = DictWriter(
result_paper,
fieldnames=['name', 'm'],
lineterminator='\n'
)
result_writer.writeheader()
result_writer.writerows(result_rows)
Path('bar.csv').write_text(
result_paper.getvalue(),
encoding='utf-8'
)
Det gis 1 poeng for hver av variabelnavnene med tilhørende forklaring. Det legges mest vekt på at forståelsen av variabelens rolle er riktig.
2 poeng gis som helhetsvurdering: god bruk av fagbegreper, god helhetlig forståelse, eller for å justere opp eller ned dersom sensor mener kandidaten demonstrerer et annet nivå av forståelse enn det poengsummen fra rubrikken forøvrig tilsier.
Oppgave 2b, 2c og 2d omhandler alle det samme mystiske programmet.
Forklar hensikten med linje 17 i programmet under, og kom med et forslag til en bedre streng du kan bruke. «I love crashing!» er tross alt ikke særlig nyttig informasjon.
| |
f"Unit not recognized: '{e}' (valid units are 'm', 'cm' and 'mm')"
- Viser forståelse for at programmet krasjer dersom enheten ikke er gyldig (2 poeng).
- Feilmeldingen er meningsfull (2 poeng).
Sensor har anledning til å justere poengene dersom kandidaten demonstrerer vesentlig større eller mindre forståelse enn hva rubrikken tilsier.
3 Kodeskriving
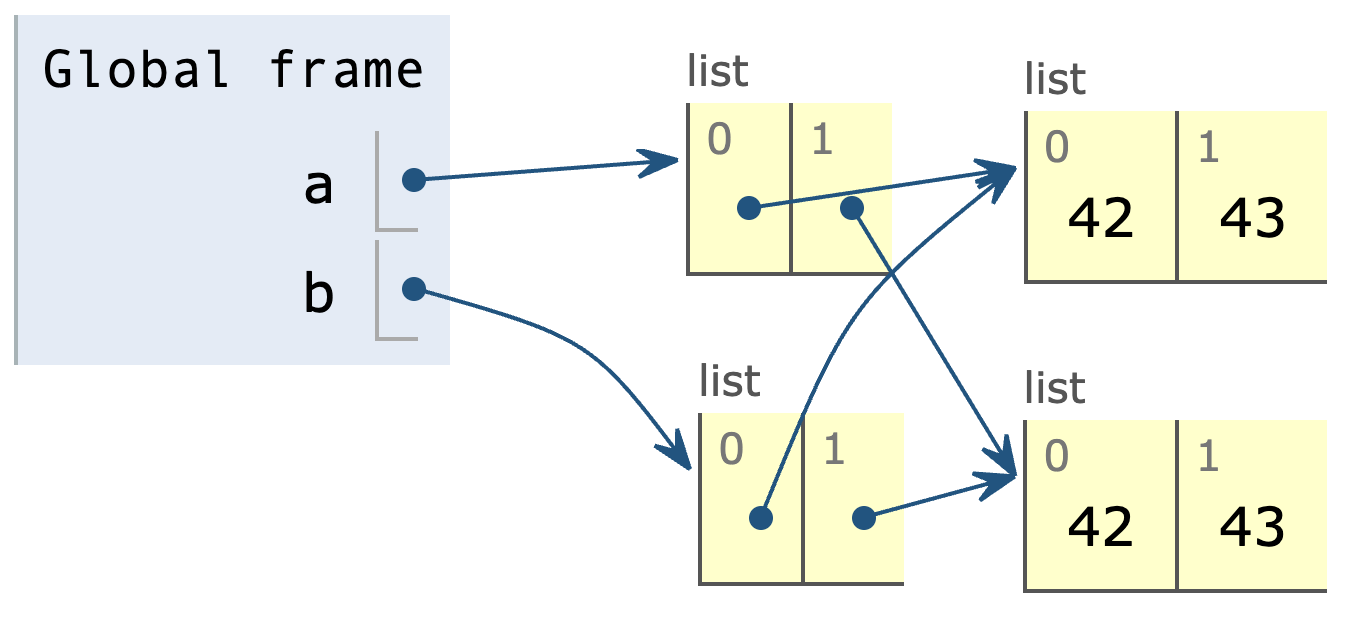
Skriv en kodesnutt slik at minnets tilstand blir som vist over. Du vil ikke få trekk i poeng dersom du definerer andre variabler i tilegg.
Klikk på «se steg» -knappen for å verifisere at denne koden gir riktig bilde av minnet.
a = [[42, 43], [42, 43]]
b = [a[0], a[1]]
temp1 = [42, 43]
temp2 = [42, 43]
a = [temp1, temp2]
b = [temp1, temp2]
- 1 poeng hvis a og b begge er lik
[[42, 43], [42, 43]] - 1 poeng hvis
aogbikke er aliaser, oga[0]er alias medb[0]men ikke meda[1] - 1 poeng hvis
aogbikke er aliaser, ogb[1]er alias meda[1]men ikke medb[0]
Sensor har anledning til å gjøre en skjønnsmessig justering i tilfeller der hen mener disse testene ikke gir et representativt bilde av hva studenten demonstrerer.
Sensor skal ikke kreve syntaktisk korrekthet – men hvis besvarelsen er syntaktisk korrekt eller er rettet opp til å bli det kan poengsummen som beskrevet over regnes ut med følgende kode:
points = sum([
a == b == [[42, 43], [42, 43]],
a is not b and a[0] is b[0] and a[0] is not a[1],
a is not b and a[1] is b[1] and b[0] is not b[1],
])
# PS: i kontekst av matematisk aritmetikk regnes True som 1 og False som 0.
Ola og Kari har to sønner, Per og Pål, som er oppkalt etter besteforeldrene sine. Et lite utsnitt av familietreet deres ser du her:
I filen family.json vedlagt ser du en tekstuell representasjon av den samme informasjonen som på bildet. Hver person har en unik id. Id-nummeret har imidlertid ingen faktisk betydning utover å bli brukt for intern organisasjon av filen. For enkelhets skyld kan du anta at alle foreldreskap beskrevet i filen er biologiske; altså at adoptivforeldre og lignende relasjoner ikke er beskrevet.

{
"people": [
{
"id": 1001,
"name": "Ola Nordmann",
"born": { "year": 1980, "month": 6, "day": 20 }
},
{
"id": 1002,
"name": "Kari Svensson",
"born": { "year": 1985, "month": 5, "day": 15 }
},
{
"id": 1003,
"name": "Per Nordmann",
"born": { "year": 2010, "month": 1, "day": 5 }
},
{
"id": 1004,
"name": "Pål Nordmann",
"born": { "year": 2012, "month": 8, "day": 10 }
},
{
"id": 1005,
"name": "Anna Smith",
"born": { "year": 1953, "month": 3, "day": 25 }
},
{
"id": 1006,
"name": "Per Nordmann",
"born": { "year": 1950, "month": 5, "day": 22 }
},
{
"id": 1007,
"name": "Jane Doe",
"born": { "year": 1956, "month": 11, "day": 30 }
},
{
"id": 1008,
"name": "Pål Svensson",
"born": { "year": 1957, "month": 7, "day": 18 }
}
],
"parenthoods": [
{ "parent": 1001, "child": 1003 },
{ "parent": 1002, "child": 1003 },
{ "parent": 1001, "child": 1004 },
{ "parent": 1002, "child": 1004 },
{ "parent": 1005, "child": 1001 },
{ "parent": 1006, "child": 1001 },
{ "parent": 1008, "child": 1002 },
{ "parent": 1007, "child": 1002 }
],
"marriages": [
{ "spouse1": 1001, "spouse2": 1002 },
{ "spouse1": 1005, "spouse2": 1006 }
]
}
Ola har en tvilling, Nora Nordmann. Hvordan er det naturlig å utvide json-filen slik at Nora også blir med i familietreet?
Du skal svare med å vise hvordan json-filen ser ut etter endringene dine. Du trenger ikke å kopiere hele json-filen, bare du viser hvordan den nye informasjonen er skrevet og viser/forklarer hvor den befinner seg i forhold til resten av innholdet i json-filen.
{
"people": [
..., # de andre personene er som før
{
"id": 1009,
"name": "Nora Nordmann",
"born": { "year": 1980, "month": 6, "day": 20 }
}
],
"parenthoods": [
..., # de andre foreldreskapene er som før
{ "parent": 1005, "child": 1009 },
{ "parent": 1006, "child": 1009 }
],
... # resten av json-filen er som før
}
Alternativ løsning som også godkjennes fullt ut:
# ... leser inn family.json og lar 'tree' peke på resultatet
tree["people"].append({
"id": 1009,
"name": "Nora Nordmann",
"born": { "year": 1980, "month": 6, "day": 20 }
})
tree["parenthoods"].append({ "parent": 1005, "child": 1009 })
tree["parenthoods"].append({ "parent": 1006, "child": 1009 })
# ... skriver innholdet i 'tree' tilbake til family.json
Det godkjennes også løsninger som beskriver tydelig med ord hva som skal injeseres hvor; men en slik forklaring må være svært presis for å gi full uttelling.
- Fornuftig opprettelse av ny person (2 poeng)
- Fornuftig opprettelse av nye foreldreskap (2 poeng)
Hvis kandidaten utelukkende benytter en forklarende beskrivelse men er vag med detaljer (nøyaktig hvilke verdier de nye objektene får og hvor de befinner seg), gis det kun delvis uttelling.
Ola og Kari har to sønner, Per og Pål, som er oppkalt etter besteforeldrene sine. Et lite utsnitt av familietreet deres ser du her:
I filen family.json vedlagt ser du en tekstuell representasjon av den samme informasjonen som på bildet. Hver person har en unik id. Id-nummeret har imidlertid ingen faktisk betydning utover å bli brukt for intern organisasjon av filen. For enkelhets skyld kan du anta at alle foreldreskap beskrevet i filen er biologiske; altså at adoptivforeldre og lignende relasjoner ikke er beskrevet.
{
"people": [
{
"id": 1001,
"name": "Ola Nordmann",
"born": { "year": 1980, "month": 6, "day": 20 }
},
{
"id": 1002,
"name": "Kari Svensson",
"born": { "year": 1985, "month": 5, "day": 15 }
},
{
"id": 1003,
"name": "Per Nordmann",
"born": { "year": 2010, "month": 1, "day": 5 }
},
{
"id": 1004,
"name": "Pål Nordmann",
"born": { "year": 2012, "month": 8, "day": 10 }
},
{
"id": 1005,
"name": "Anna Smith",
"born": { "year": 1953, "month": 3, "day": 25 }
},
{
"id": 1006,
"name": "Per Nordmann",
"born": { "year": 1950, "month": 5, "day": 22 }
},
{
"id": 1007,
"name": "Jane Doe",
"born": { "year": 1956, "month": 11, "day": 30 }
},
{
"id": 1008,
"name": "Pål Svensson",
"born": { "year": 1957, "month": 7, "day": 18 }
}
],
"parenthoods": [
{ "parent": 1001, "child": 1003 },
{ "parent": 1002, "child": 1003 },
{ "parent": 1001, "child": 1004 },
{ "parent": 1002, "child": 1004 },
{ "parent": 1005, "child": 1001 },
{ "parent": 1006, "child": 1001 },
{ "parent": 1008, "child": 1002 },
{ "parent": 1007, "child": 1002 }
],
"marriages": [
{ "spouse1": 1001, "spouse2": 1002 },
{ "spouse1": 1005, "spouse2": 1006 }
]
}
Ola og Kari har blitt helt revet med, og legger til flere og flere familiemedlemmer. Til slutt har family.json blitt så stor at den inneholder informasjon om tusenvis av personer, samt foreldreskap og giftermål mellom dem.
Underveis i arbeidet legger de merke til at flere personer har akkurat samme navn; for eksempel heter Per Nordmann (født 2010) nøyaktig det samme som bestefaren sin (født 1950).
Oppgavetekst
Skriv en funksjon get_ids med to parametre:
- tree, et oppslagsverk (dict) som representerer et familietre. Du kan anta at det har samme format du ser et eksempel på i family.json.
- name, en streng (str) som representerer et navn.
Funksjonen skal returnere en liste med ID’er til personer med det gitte navnet. Eksempel: et kall til get_ids(tree, ‘Per Nordmann’) skal returnere en liste [1003, 1006].
def get_ids(tree, name):
result = []
for person in tree['people']:
if name == person['name']:
result.append(person['id'])
return result
def get_ids(tree, name):
return [p['id'] for p in tree['people'] if name == p['name']]
- Benytter en eller annen form for løkke (1 poeng)
- Løkken går gjennom elementene i
tree['people'](1 poeng) - Det opprettes en (tom) liste for å ta vare på resultatene et egnet sted (typisk før løkken) (1 poeng)
- Betingelsen for å legge til er riktig (1 poeng)
- Det er riktig verdi (ID’en) som legges til i resultatet (1 poeng)
- Helhetsvurdering/alt fungerer i sammenheng (2 poeng)
Sensor skal ikke trekke for syntaksfeil dersom intensjonen er tydelig og algoritmen er presist beskrevet.
Ola og Kari har to sønner, Per og Pål, som er oppkalt etter besteforeldrene sine. Et lite utsnitt av familietreet deres ser du her:
I filen family.json vedlagt ser du en tekstuell representasjon av den samme informasjonen som på bildet. Hver person har en unik id. Id-nummeret har imidlertid ingen faktisk betydning utover å bli brukt for intern organisasjon av filen. For enkelhets skyld kan du anta at alle foreldreskap beskrevet i filen er biologiske; altså at adoptivforeldre og lignende relasjoner ikke er beskrevet.
{
"people": [
{
"id": 1001,
"name": "Ola Nordmann",
"born": { "year": 1980, "month": 6, "day": 20 }
},
{
"id": 1002,
"name": "Kari Svensson",
"born": { "year": 1985, "month": 5, "day": 15 }
},
{
"id": 1003,
"name": "Per Nordmann",
"born": { "year": 2010, "month": 1, "day": 5 }
},
{
"id": 1004,
"name": "Pål Nordmann",
"born": { "year": 2012, "month": 8, "day": 10 }
},
{
"id": 1005,
"name": "Anna Smith",
"born": { "year": 1953, "month": 3, "day": 25 }
},
{
"id": 1006,
"name": "Per Nordmann",
"born": { "year": 1950, "month": 5, "day": 22 }
},
{
"id": 1007,
"name": "Jane Doe",
"born": { "year": 1956, "month": 11, "day": 30 }
},
{
"id": 1008,
"name": "Pål Svensson",
"born": { "year": 1957, "month": 7, "day": 18 }
}
],
"parenthoods": [
{ "parent": 1001, "child": 1003 },
{ "parent": 1002, "child": 1003 },
{ "parent": 1001, "child": 1004 },
{ "parent": 1002, "child": 1004 },
{ "parent": 1005, "child": 1001 },
{ "parent": 1006, "child": 1001 },
{ "parent": 1008, "child": 1002 },
{ "parent": 1007, "child": 1002 }
],
"marriages": [
{ "spouse1": 1001, "spouse2": 1002 },
{ "spouse1": 1005, "spouse2": 1006 }
]
}
Ola og Kari har blitt helt revet med, og legger til flere og flere familiemedlemmer. Til slutt har family.json blitt så stor at den inneholder informasjon om tusenvis av personer, samt foreldreskap og giftermål mellom dem.
Oppgavetekst
Ola og Kari har en hypotese om at barn av ugifte foreldre (såkalte «kjærlighetsbarn») har større sannsynlighet for å bli født om våren (i mars, april eller mai). Skriv et program som finner
- hvor mange kjærlighetsbarn vi vet om totalt i slektstreet, og
- hvor mange av dem som ble født om våren.
Vi definerer et kjærlighetsbarn som en person hvor begge foreldre til personen er med i familietreet, men foreldrene ikke er markert som gift med hverandre.
Du kan anta at du har tilgang på en fil family.json på samme format som vist i eksempelet. I eksempelet finner vi ett kjærlighetsbarn (Kari), og hun ble født på våren (i mai). Koden du skriver må imidlertid virke også når family.json beskriver et slektstre med tusenvis av personer.
Du trenger ikke å ha optimal kjøretid for å få full uttelling på oppgaven. Det viktigste er at løsningen er korrekt og lett å forstå. Sensor vil legge vekt på at du klarer å dele opp oppgaven i egnede hjelpefunksjoner.
| |
Rubrikken vil vise til elementer fra løsningsforslaget. Det er verdt å merke seg at det kan finnes andre løsninger. I slike tilfeller må sensor gjøren en skjønnsmessig vurdering.
Lese fra json-fil (1 poeng). Tilsvarer linje 6-7 i løsningsforslaget.
Telle personer som er kjærlighetsbarn (2 poeng). Kode for å telle antall kjærlighetsbarn vil innebære en eller annen form for sjekk av alle personer, formodentlig i en løkke. Poengene her gis om logikken for selve tellingen og iterasjon gjennom elementene som potensielt skal telles fungerer. I løsningsforslaget tilsvarerer dette i hovedsak get_love_children -funksjonen på linje 17-28 samt linje 13 i hovedfunksjonen.
Identifisere om en person er et kjærlighetsbarn (2 poeng). Kode for å sjekke om en gitt person er et kjærlighetsbarn innebærer å finne foreldrene til personen, verifisere at det er to av dem og sjekke om de har vært gift. Dersom man identifiserer at det er disse elementene man trenger og man samler dette i en fornuftig betingelse, gis poengene. Dette tilsvarer koden i is_love_child -funksjonen linje 31-39 i løsningsforslaget.
Finne foreldrene til en person (2 poeng). Å finne foreldrene til en person innebærer at man går igjennom alle foreldreskapene i familietreet. Det mest effektive med tanke på prossesorutnyttelse er å gjøre dette i et pre-prossesseringssteg hvor man oppretter et oppslagsverk hvor person-ID nøkler og tilhørende verdi er en liste over foreldres ID; men det kan også gjøres med en ny løkke hver gang man sjekker en ny person. Det gir ikke trekk å benytte den mindre effektive løsningen, og det er denne som er vist i hovedløsningsforslaget (se funksjonen get_parents linje 42-50).
Sjekke om to personer er gift (2 poeng). Å sjekke om to personer er gift innebærer at man går igjennom alle giftermål i familietreet. Det mest effektive med tanke på prossesorutnyttelse er å gjøre dette i et pre-prossesseringssteg hvor man oppretter et oppslagsverk hvor person-ID nøkler og tilhørende verdi er en liste over personer man er (/har vært) gift med; men det kan også gjøres med en ny løkke hver gang man sjekker en ny person. Det gir ikke trekk å benytte den mindre effektive løsningen, og det er denne som er vist i hovedløsningsforslaget (se funksjonen get_parents linje 53-64).
Identifisere hvilke kjærlighetsbarn som er født om våren (1 poeng). I løsningsforslaget (linje 67-75) gjøres dette ved å benytte en ny løkke etter at man først har lagt alle kjærlighetsbarna i en liste man søker i. Det er også mulig å identifisere vår-barn i samme løkke som man først identifiserer kjærlighetsbarn. Pass på at det kun er kjærlighetsbarn som telles, ikke alle vår-barn.
Hovedprogram som binder alt sammen og helhetsvurdering (4 poeng). Er koden delt inn i egnede hjelpefunksjoner? Kalles hjelpefunksjonene der det er hensiktsmessig? Brukes det gode variabel- og funksjonsnavn? Har koden et startpunkt, eller er alt bare funksjoner som aldri kalles?