
Lab8
Poeng:

Endelig er den her: semesterets siste lab! Denne lab’en er en god blanding av alt vi har lært i løpet av semesteret. Denne lab’en er basert på poeng, og du må få minst 12 poeng for å bestå. Du kan velge selv hvilke oppgaver du ønsker å løse. Hvor mange poeng hver oppgave gir ser du ved stjernemerkene ★
Haiku
I denne oppgaven skal vi spørre brukeren om en haiku og siden printe den på en fin måte til terminalen.
I filen haiku.py, skriv kode som gjør følgende, i oppgitt rekkefølge (merk at noen av de beskrevne punktene her krever mer enn en enkelt linje med Python-kode):
- Spør brukeren om første raden i en haiku. Lagre resultatet i en ny variabel.
- Spør brukeren om andre raden i en haiku. Lagre resultatet i en ny variabel.
- Spør brukeren om tredje raden i en haiku. Lagre resultatet i en ny variabel. Nå burde du ha tre variabeler.
- Finn lengden av hver linje (bruk
len()) - Finn lengden av den lengste linjen (bruk
max()) - Skriv ut en tom linje
- Skriv ut toppen av haiku-rammen. Lengden av den er basert på lengden av den lengste linjen, som vi fant i trinn 5, men pluss fire til. Vi trenger fire til fordi rammen skal gå på utsiden på begge sider (se eksempelkjøring nedenfor).
- Skriv ut hver av de tre linjene. Hver linje skal begynne med
@+ et passende antall mellomrom. Deretterer følger selve teksten, og til slutt et nytt mellomrom og en ny alfakrøll. (Hvor mange mellomrom er passende for hver linje? ) - Skriv ut bunnen av rammen.
Eksempelkjøring:
Første raden:
What a pleasure to
Andre raden:
right justify a haiku
Tredje raden:
as an exercise
@@@@@@@@@@@@@@@@@@@@@@@@@
@ What a pleasure to @
@ right justify a haiku @
@ as an exercise @
@@@@@@@@@@@@@@@@@@@@@@@@@
Husk at strenger kan gjentas flere ganger ved help av
*. For eksempel vil"bar" * 2evaluere til"barbar".
Kollisjonsdeteksjon
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver (A-B) i én felles fil, collision_detection.py.
Del A
I filen collision_detection.py, skriv en funksjon rectangles_overlap som har åtte parametre x1, y1, x2, y2, x3, y3, x4, y4, hvor de fire første parametrene ett hyperrektangel, og de fire siste representerer et annet (et hyperrektangel representeres av to motsatte hjørner, men vi kan ikke gjøre noen ytterligere antakelser om hvilke hjørner). La metoden returnere True dersom rektanglene overlapper hverandre, og False hvis ikke. Vi sier at rektanglene overlapper selv om de kun deler ett enkelt punkt.

Test koden din:
print("Tester rectangles_overlap... ", end="")
assert rectangles_overlap(0, 0, 5, 5, 2, 2, 6, 6) is True # Delvis overlapp
assert rectangles_overlap(0, 5, 5, 0, 1, 1, 4, 4) is True # Fullstendig overlapp
assert rectangles_overlap(0, 1, 7, 2, 1, 0, 2, 7) is True # Kryssende rektangler
assert rectangles_overlap(0, 5, 5, 0, 5, 5, 7, 7) is True # Deler et hjørne
assert rectangles_overlap(0, 0, 5, 5, 3, 6, 5, 8) is False # Utenfor
print("OK")
- Omregn begge rektangler slik at du vet hva som er høyre og venstre, top og bunn (se hint for oppgaven Hyperrektangel).
- Dersom høyresiden til ett rektangel er til venstre for venstresiden av det andre, blir svaret false (tilsvarende logikk med topp og bunn). Husk å sjekke begge retninger.
Illustrasjon av testcasene i assert’ene over:

Del B
I filen collision_detection.py, skriv en funksjon circle_overlaps_rectangle som har syv parametre x1, y1, x2, y2, xc, yc, rc, hvor de fire første parametrene representerer to motstående hjørner i et hyperrektangel, og de tre siste representerer en sirkel sentrert i \((x_c, y_c)\) med radius \(r_c\). La metoden returnere True dersom sirkelen overlapper rektangelet, og False hvis ikke. Dersom sirkelen og rektangelet deler kun ett enkelt punkt regnes det fremdeles som at de er overlappende.

Test koden din:
print("Tester circle_overlaps_rectangle... ", end="")
assert circle_overlaps_rectangle(0, 0, 5, 5, 2.5, 2.5, 2) is True # på midten
assert circle_overlaps_rectangle(0, 5, 5, 0, 8, 3, 2) is False # langt utenfor
assert circle_overlaps_rectangle(0, 0, 5, 5, 2.5, 7, 2.01) is True # på kanten
assert circle_overlaps_rectangle(0, 5, 5, 0, 5.1, 5.1, 1) is True # på hjørnet
assert circle_overlaps_rectangle(0, 0, 5, 5, 8, 8.99, 5) is True # på hjørnet
assert circle_overlaps_rectangle(0, 0, 5, 5, 8, 9.01, 5) is False # bare nesten
print("OK")
- Dersom sirkelens sentrum er inne i rektangelet, er svaret
True. Bruk funksjonen du skrev i oppgaven om punkt i rektangel for å sjekke dette.- Du kan importere funksjonen ved å legge til
from point_in_rectangle import point_in_rectangleøverst i collision_detection.py.
- Du kan importere funksjonen ved å legge til
- La det minste x-koordinatet av
x1ogx2kallesx_left, og la det største kallesx_right. På samme måte, slutt å tenke på punkteney1ogy2, og regn i stedet ut punkteney_topogy_bottom. - «Utvid» rektangelet med sirkelens radius i alle retninger. Hvis sirkelens sentrum er utenfor dette utvidede rektangelet (bruk funksjonen point_in_rectangle igjen), er det garantert ikke noe overlapp.
- I de gjenstående tilfellene befinner sirkelen sitt sentrum seg i rammen rundt rektangelet som er tegnet med stiplet linje i illustrasjonen over.
- Dersom sirkelens x-koordinat befinner seg mellom x-koordinatene til det opprinnelige rektangelet, er det overlapp.
- Tilsvarende for y-aksen.
- Hvis sirkelens sentrum ikke tilfredsstiller noen av de to punktene over, befinner det seg i et av hjørnene. Dersom sirkelens sentrum har større avstand enn \(r_c\) til samtlige hjørner i det opprinnelige rektangelet, er det ingen overlapp (f. eks. slik som på figuren over). For å finne avstanden, bruk funksjonen distance som du kan importere fra en tidligere oppgave (
from distance import distance).
Illustrasjon av testcasene oppgitt over (en sirkel per testcase):


if point_in_rectangle(...): # sirkelens sentrum inne i rektangel?
return True
elif not point_in_rectange(...): # sentrum utenfor utvidet rektangel?
return False
elif ... # punkt er mellom venstre og høyresiden til rektangel (x-aksen)
return True
elif ... # punkt er mellom topp og bunn til rektangel (y-aksen)
return True
elif distance(...) # sirkelen overlapper hjørnet oppe til venstre
return True
elif ... # sirkelen overlapper hjørnet oppe til høyre
return True
...
Tverrsum
En tverrsum er summen av alle sifrene i et tall. For eksempel, tverrsummen av tallet 123 er 1 + 2 + 3 = 6.
Del A: Tverrsum
I filen cross_sum.py skriv en funksjon cross_sum som med en parameter x som tar inn et heltall og returnerer tverrsummen av tallet.
Du kan begynne fra denne koden:
def cross_sum(x):
... # din kode her
Her er tester du kan sette inn på slutten av filen for å teste funksjonen:
def test_cross_sum():
print('Tester cross_sum... ', end='')
assert 6 == cross_sum(123)
assert 7 == cross_sum(34)
assert 0 == cross_sum(0)
assert 1 == cross_sum(100)
print('OK')
if __name__ == '__main__':
test_cross_sum()
Del B: N-te tallet med tverrsum
I samme fil, skriv en funksjon nth_cross_sum med parametre n og x som tar inn heltall og som returnerer ut det n’te tallet med tverrsummen x.
Eksempel: det første tallet med tverrsum 7 er bare tallet 7, mens det andre tallet med tverrsum 7 er 16. Derfor skal programmet ditt skrive ut 7 på input n = 1 og x = 7, mens programmet skal ut 16 på input n = 2 og x = 7.
Her er kode du kan legge til på slutten av filen for å teste funksjonen din:
def test_nth_cross_sum():
print('Tester nth_cross_sum... ', end='')
assert nth_cross_sum(3, 7) == 25
assert nth_cross_sum(1, 10) == 19
assert nth_cross_sum(2, 10) == 28
assert nth_cross_sum(10, 2) == 2000
print('OK')
if __name__ == '__main__':
test_nth_cross_sum()
Du vet ikke før løkken starter hvor mange iterasjoner løkken skal ha. Derfor bør du velge en while-løkke, og ikke en for-løkke for å finne det n-te tallet med en gitt tverrsum.
Minste absolutt-forskjell
I filen least_difference.py skriv funksjonen smallest_absolute_difference som har en liste med tall a som parameter. Funksjonen skal returnerer den minste absolutt-verdi som er forskjellen mellom to tall i listen a.
Her er en testfunksjon du kan bruke for testing:
def test_smallest_absolute_difference():
print('Tester smallest_absolute_difference... ', end='')
assert 1 == smallest_absolute_difference([1, 20, 4, 19, -5, 99]) # 20-19
assert 6 == smallest_absolute_difference([67, 19, 40, -5, 1]) # 1-(-5)
assert 0 == smallest_absolute_difference([2, 1, 4, 1, 5, 6]) #1-1
a = [50, 40, 70, 33]
assert 7 == smallest_absolute_difference(a)
assert [50, 40, 70, 33] == a # Sjekker at funksjonen ikke er destruktiv
print('OK')
Alternativ A (kanskje enklest å komme på, men litt ineffektivt):
- Før løkkene starter, opprett en variabel som har til hensikt å hold på den minste forskjellen mellom to elementer sammenlignet så langt. Initielt kan den for eksempel ha absolutt-verdien av avstanden mellom de to første elementene i listen
- Benytt en indeksert for-løkke for å gå igjennom alle elementene i listen. I iterasjon nummer
iav løkken er hensikten å finne den minste absolutt-verdi-forskjellen mellom elementeta[i]og et element som kommer senere i listen (vi trenger kun å sjekke det som kommer senere i listen – fordi hvis den minste forskjellen var mot et element tidligere i listen, vil denne forskjellen allerede være funnet da vi sjekket det elementet). - Benytt en nøstet for-løkke for å gå gjennom alle posisjoner
jmellomi+1oglen(a); regn ut absolutt-verdien av forskjellen påa[i]oga[j], og dersom den er mindre enn noe vi har sett før, lagre denne avstanden i variabelen som har til hensikt å huske dette. - Når alle iterasjonene er ferdig, returner svaret
Alternativ B (mer effektivt):
Ikke-destruktivt sorter listen
Gå gjennom listen med en indeksert løkke, og regn ut forskjellen på alle etterfølgende elementer. Ta vare på den minste slike avstanden.
Komprimering
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver (A-B) i én felles fil, runlength_encoding.py.
En fil består av en sekvens av 1’ere og 0’ere. Noen filformater har i praksis veldig lange sekvenser med kun 1’ere eller kun 0’ere. For eksempel: en sensor i et alarmsystem gir 1 som output når en dør er åpen, og 0 som output når en dør er lukket; sensoren blir avlest 1 gang i sekundet, og disse data’ene blir lagret som en sekvens av 0’ere og 1’ere i en fil. Et annet eksempel på slike filer er bilder med store hvite eller svarte felter.
For å komprimere slike filer, kan vi omgjøre måten vi skriver filen på til å bestå av en sekvens heltall som forteller vekselvis hvor mange 0’ere og 1’ere som kommer etter hverandre. Det første tallet i komprimeringen forteller hvor mange 0’er det er i begynnelsen. Dette tallet kan være 0 dersom binærtallet begynner med 1. Alle andre tall i komprimeringen vil være positive. Du kan lese mer om denne typen komprimering på Wikipedia.
For enkelhets skyld gjør vi denne oppgaven med strenger og lister og ikke direkte med 1’ere og 0’ere lagret i minnet.
Del A
Opprett en funksjon compress(raw_binary) som tar inn en streng raw_binary bestående av 0’ere og 1’ere. Funksjonen skal retunerer en liste som representerer sekvensen i komprimert form (tall skilles med mellomrom).
Her er en testfunksjon du kan bruke for testing:
def test_compress():
print('Tester compress... ', end='')
assert([2, 3, 4, 4] == compress('0011100001111'))
assert([0, 2, 1, 8, 1] == compress('110111111110'))
assert([4] == compress('0000'))
print('OK')
Det finnes mange måter å løse dette problemet på. Det kan være lurt å begynne med å sjekke om første tegn er “1”. Hvis det er tilfelle legg til 0. Fordi 0 indikerer at det første tegnet ikke er «0».
Lag en variabel som begynner på 0 (int) som kan brukes for å telle antall 0’ere og 1’ere, og opprett en tom liste.
Lag en løkke som går fra 0 opp til lengden av stringen - 1. Dette lar oss sammenligne to tegn samtidig.
I løkken sjekk om tegnet er lik neste tegn, feks “if [i] == [i + 1]:” hvis dette er True øk telleren med 1. Hvis dette ikke stemmer legg verdien som telleren nå har til listen, og tilbakestill telleren til 1.
Når løkken er ferdig legg telleren til listen en siste gang. Nå vil du ha en liste med tall som representerer den komprimerte sekvensen.
Del B
Opprett en funksjon decompress(compressed_binary) som tar inn en liste compressed_binary beståenden av heltall som representerer en komprimert sekvens av 0’ere og 1’ere. La funksjonen returnere den ukomprimerte sekvensen av 0’ere og 1’ere.
Her er en testfunksjon du kan bruke for testing:
def test_decompress():
print('Tester decompress... ', end='')
assert('0011100001111' == decompress([2, 3, 4, 4]))
assert('110111111110' == decompress([0, 2, 1, 8, 1]))
assert('0000' == decompress([4]))
print('OK')
Igjen er det flere måter å løse dette problemet på.
Lag en tom streng som du skal legge til tegn i. Det er denne du returnerer til slutt.
Lag en løkke som går gjennom listen av tall, og legger til
"0"*neller"1"*ntil strengen avhengig av hvilken sin tur det er.Legg merke til at verdier på partallsposisjoner i listen indikerer antall 0’ere, og oddetallsposisjoner indikerer antall 1’ere.
- På posisjon 0 tilsier det hvor mange 0’ere det er i starten av sekvensen.
- På posisjon 1 indikerer det hvor mange 1’ere du skal sette etter det.
- På posisjon 2 indikerer det hvor mange 0’ere du skal sette etter det igjen…
- Og så videre. Er det noen måte du kan plassere 0’ere eller 1’ere avhengig av hvilken posisjon i listen du ser på?
Mulige ord
I filen possible_words.py skriv en funksjon possible_words_from_file(path, letters) som tar inn en filsti path til en fil som inneholder en ordliste med ett lovlig ord på hver linje, samt en bokstavsamling letters med scrabble-brikker. La funksjonen returnere en liste med alle ord man kan lage av de gitte bokstavbrikkene. Det er ikke lov å bruke samme bokstav i ordene du returnerer flere ganger enn den opptrer i letters.
For å teste funksjonen kan du laste ned den offisielle ordlisten fra Norsk Scrabbleforbund (nsf2022.txt) og legge den i samme mappe possible_words.py kjøres fra.
Husk at hvilken mappe du kjører fra ikke alltid er den samme mappen hvor programmet ligger; men dersom du åpner VSCode i samme mappe som skriptet ditt, vil dette også være den mappen du kjører programmet fra.
Test koden din:
def test_possible_words_from_file():
print('Tester possible_words_from_file... ', end='')
assert(['du', 'dun', 'hu', 'hud', 'hun', 'hund', 'nu', 'uh']
== possible_words_from_file('nsf2022.txt', 'hund'))
# Ekstra test for varianten hvor det er wildcard i bokstavene
# assert(['a', 'cd', 'cv', 'e', 'i', 'pc', 'wc', 'æ', 'å']
# == possible_words_from_file('nsf2022.txt', 'c*'))
print('OK')
if __name__ == '__main__':
test_possible_words_from_file()
God stil
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver (A og B) i én felles fil, nice_style.py.
Del A
Tradisjonelt regnes 80 tegn for å være den maksimale lengden på en linje for å ha en god kodestil. Selv om moderne skjermer er i stand til å vise flere tegn på en linje, regnes grensen på 80 fremdeles for å være en god tommelfingerregel, og er for eksempel en del av Python sin offisielle stil-guide PEP 8.
Skriv funksjonen good_style(source_code) som returnerer True hvis alle linjene i strengen source_code er mindre enn eller lik 80 tegn, False ellers.
Merk at grensen på 80 tegn inkluderer selve linjeskift-symbolet på slutten av linjen, slik at det i praksis blir maksimalt 79 tegn på hver linje.
Test koden din:
def test_good_style():
print('Tester good_style... ', end='')
assert good_style('''\
def distance(x0, y0, x1, y1):
return ((x0 - x1)**2 + (y0 - y1)**2)**0.5
''') is True
assert good_style((('x' * 79) + '\n') * 20) is True
assert good_style('x' * 80) is False
assert good_style(
(('x' * 79) + '\n') * 5 +
+ (('x' * 80) + '\n')
+ (('x' * 79) + '\n') * 5
) is False
print('OK')
if __name__ == '__main__':
test_good_style()
Benytt en løkke som itererer over alle linjene i en streng. string.splitlines() kan hjelpe her. Pass på å ta hensyn til linjeskiftene (se også testene over).
Dersom vi blir ferdige med løkken uten å finne en eneste linje som er for lang, er svaret True.
Del B
Skriv funksjonen good_style_from_file(filename) som leser inneholdet i filen filename og returerer True hvis inneholdet har god kodestil (alle linjene har mindre enn eller lik 80 tegn), False hvis ikke. Kjør koden din på filene test_file1.py, test_file2.py og test_file3.py.
Test koden din med denne funksjonen (gjør et kall til den fra if __name__ == '__main__' -blokken). Det kan være du må justere filstien litt slik at «nice_style.py» viser til riktig fil, altså viser til samme fil du kjører koden fra:
def test_good_style_from_file():
print('Tester good_style_from_file... ', end='')
assert good_style_from_file('test_file1.py') is True
assert good_style_from_file('test_file2.py') is False
assert good_style_from_file('test_file3.py') is False
assert good_style_from_file('nice_style.py') is True
print('OK')
Kombinere CSV-filer
I denne oppgaven skal vi bruke CSV- biblioteket til å håndtere CSV-filer. Derfor bør du lese om dette i kursnotatene om csv
I denne oppgaven skal vi kombinere flere CSV-filer som ligger i en mappe til én stor CSV-fil. Hver av CSV-filene har det samme formatet, som også er det formatet den kombinerte CSV-filen skal ha:
uibid,karakter,kommentar
abc101,A,"Veldig bra, fra start til slutt"
abc102,B,"Denne kandidaten kan sin INF100, men bommer litt i oppgave 2 og 3"
abc103,C,"Denne kandidaten valgte å kun svare på partallsoppgavene"
I csv_combiner.py skriv en funksjon combine_csv_in_dir(dirpath, result_path) som har to parametre:
dirpather en sti til en mappe som inneholder en rekke CSV-filer som skal kombineres. Det er kun filene som slutter på .csv i mappen som skal inkluderes, andre filtyper skal vi overse.result_pather en sti til en CSV-fil som skal opprettes, som inneholder de kombinerte dataene fra alle CSV-filene.
For å teste funksjonen kan du laste ned samples.zip og pakke ut innholdet i samme mappe hvor du også finner csv_combiner.py. Innholdet skal ligge i en mappe som heter samples. Du kan så teste funksjonen din med denne koden:
print("Tester combine_csv_in_dir... ", end="")
# Mappen samples må ligge i samme mappe som denne filen
dirpath = os.path.join(os.path.dirname(__file__), "samples")
combine_csv_in_dir(dirpath, "combined_table.csv")
with open("combined_table.csv", "rt", encoding='utf-8') as f:
content = f.read()
assert("""\
uibid,karakter,kommentar
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
""" == content or """\
uibid,karakter,kommentar
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
""" == content)
print("OK")
Merk: csv-biblioteket sin standard oppførsel når du lagrer 2D-lister som CSV er at det kun benyttes hermetegn dersom det er nødvendig. Det er nødvendig med hermetegn dersom en celle inneholder skilletegn (komma), linjeskift eller hermetegn. Dersom cellen ikke inneholder noen av de tre tegnene, vil det ikke inkluderes hermetegn i filen. Denne oppførselen kan endres ved å kalle på write_csv_file -funksjonen i kursnotatene med argumentene quoting=csv.QUOTE_NONNUMERIC eller quoting=csv.QUOTE_ALL (se også offisiell dokumentasjon).
Dette betyr at selv om det kanskje er hermetegn i input-filen, vil disse ikke nødvendigvis bli med i resultat-filen. Assert-setningene over viser resultatet slik det blir med standard-innstillingene til csv-biblioteket.
CSV-filene i dette eksempelet er best lest med csv-biblioteket. Det blir fort komplisert å tolke dem selv, siden det kan være komma-tegn i kommentar-feltet.
Les om
os-modulen, og legg spesielt merke tilos.walk-funksjonen.Bruk gjerne en hjelpefunksjon
merge_table_into(master_table, new_table)som tar som input en 2D-listemaster_tablesom skal muteres, og en 2D-listenew_tablesom inneholder det nye innholdet som skal legges til. For hver rad i new_table (bortsett fra første rad), kopier raden inn i master_table.
Opprett først en 2D-liste for resultat-tabellen vår, som initielt inneholder én rad (overskriftene). På slutten skal vi konvertere denne listen til CSV.
Bruk
os.walkelleros.listdirfor å gå igjennom alle filene i mappen gitt veddirpath(os.walk vil også gå inn i undermapper, og du trenger en nøstet løkke inne i os.walk for å gå gjennom listen med filer; ellers fungerer de nokså likt). For hver fil som ender på .csv (bruk f. eks..endswith-metoden på strenger), åpne filen og les innholdet.Husk å bruke
os.path.join-funksjonen for å omgjøre filnavn til filstier.For hver .csv -fil du finner, omgjør den til en 2D-liste, og legg til radene i resultat-tabellen (bruk hjelpefunksjonen beskrevet over).
Lister vs oppslagsverk
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver i én felles fil, list_vs_dictionary.py.
I denne oppgaven skal vi undersøke slektskapet mellom oppslagsverk og lister. En nøkkel spiller på mange måter samme rolle for et oppslagsverk som en indeks gjør for en liste.
Del A
Skriv funksjonen key_value_getter(d) som tar inn en dictionary d, og skriver ut til skjermen nøklene, verdiene og nøkkel/verdi-par.
Eksempelkjøring:
key_value_getter({
"monday": 0,
"tuesday": 0.7,
"wednesday": 0,
"thursday": 4.7,
"friday": 10
})
skal gi utskriften:
Dictionary keys:
monday
tuesday
wednesday
thursday
friday
Dictionary values:
0
0.7
0
4.7
10
Dictionary keys/value:
monday 0
tuesday 0.7
wednesday 0
thursday 4.7
friday 10
Del B
Skriv funksjonen index_value_getter(a) som tar inn en liste a og skriver ut til skjermen indeksene, verdiene og indeks/verdi -parene.
Eksempelkjøring:
index_value_getter([7.0, 8.0, 10.0, 9.0, 10.0])
skal gi utskriften:
List indices:
0
1
2
3
4
List values:
7.0
8.0
10.0
9.0
10.0
List indices/value:
0 7.0
1 8.0
2 10.0
3 9.0
4 10.0
PS: Det skal ikke komme noen utskrift i terminalen dersom noen importerer filen din som en modul. Hvis du vil teste funksjonene dine lokalt på egen maskin kan du legge til dine egne kall til funksjonene nederst i filen din under if __name__ == "__main__":.
Collatz-sekvensen
Collatz-sekvensen er definert som følger:
- Start med et tall \(n\)
- Hvis \(n\) er jevnt så er neste tall \(\frac{n}{2}\), ellers så er neste tall \(3n +1\)
- Repeter steg \(2\) med det nye tallet helt til du får \(1\). Da er du ferdig.
Her er en funksjon som beregner Collatz-sekvensen gitt en en startverdi \(n\):
def collatz_sequence(n):
sequence = [n]
while n > 1:
if n % 2 == 0:
n = n // 2
else:
n = 3 * n + 1
sequence.append(n)
return sequence
I filen collatz.py, skriv en funksjon som heter collect_collatz(a, b) som bruker collatz_sequence -funksjonen gitt over til å beregne Collatz-sekvensen for alle tall fra og med \(a\) og opp til (men ikke inkludert) \(b\). Sekvensene skal returneres i form av et oppslagsverk hvor startverdiene er nøkler.
Test koden din ved å legge til disse linjene nederst i filen:
def test_collect_collatz():
print('Tester collect_collatz... ', end='')
# Test 1
expected = {
1: [1],
2: [2, 1],
3: [3, 10, 5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(1, 4)
assert expected == actual
# Test 2
expected = {
3: [3, 10, 5, 16, 8, 4, 2, 1],
4: [4, 2, 1],
5: [5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(3, 6)
assert expected == actual
print('OK')
if __name__ == '__main__':
test_collect_collatz()
Begynn med å opprette et tomt oppslagsverk (som du skal returnere på slutten av funksjonen, når det er ferdig fylt opp med nøkler og verdier).
Bruk en løkke for å gå gjennom alle tall fra og med \(a\) opp til men ikke inkludert \(b\).
Inne i løkken: gjør et kall til
collatz_sequence-metoden med iteranden som argument. Oppdater oppslagsverket slik at iteranden blir en ny nøkkel med returverdien fra kallet tilcollatz_sequencesom verdi.
Filter for høye temperaturer
I filen filter_high_temperatures.py, skriv en funksjon som heter filter_high_temperatures med parametre:
path_input, en filsti til en eksisterende fil hvor hver linje inneholder først en dag, deretter et mellomrom, og så en temperatur. For eksempel, temperatures.txt.path_output, en filsti til en fil som skal opprettes, ogthreshold_temp, et flyttall som representerer en temperatur.
La funksjonen åpne filen path_input, gå gjennom linjene i filen og lager en ny fil path_output hvor kun de linjene der temperaturen er minst threshold_temp er inkludert. Om ingen dager har en temperatur som er minst threshold_temp så skal path_output være en tom fil.
For å teste programmet ditt, legg til nederst i filen:
def test_filter_high_temperatures():
print('Tester filter_high_temperatures... ', end='')
filter_high_temperatures('temperatures.txt', 'high_temps.txt', 23.5)
expected = (
'Monday 23.5\n'
'Wednesday 24.0\n'
'Thursday 23.9\n'
'Sunday 23.9\n'
)
with open('high_temps.txt', 'rt', encoding='utf-8') as file:
actual = file.read()
assert expected.strip() == actual.strip()
print('OK')
if __name__ == '__main__':
test_filter_high_temperatures()
Kolonnesum
I filen sum_of_column.py, skriv en funsjon sum_of_column(path, col) som returnerer summen av verdiene fra den oppgitte kolonnen i csv-filen med filsti path. Ikke inkluderer verdier i summen som ikke er flyttall; hvis det ikke finnes noen tallverdier i oppgitt kolonne, skal funksjonen returnere 0. Kolonne 0 er den første kolonnen fra venstre i csv-filen. Du kan anta at csv-filen benytter komma (,) som skilletegn og dobbel rett apostrof (") som anførselstegn/grupperingssymbol («quotechar»).
Eksempelkjøringer med foo.csv, Statistikk_Tilsyn_ar.csv og airport-codes.csv
def test_sum_of_column():
print('Tester sum_of_column... ', end='')
assert(42.0 == sum_of_column('foo.csv', 0))
assert(95.0 == sum_of_column('foo.csv', 1))
assert(0.0 == sum_of_column('foo.csv', 2))
assert(76363.0 == sum_of_column('Statistikk_Tilsyn_ar.csv', 1))
assert(46007.0 == sum_of_column('Statistikk_Tilsyn_ar.csv', 2))
assert(5024518.0 == sum_of_column('airport-codes.csv', 3))
print('OK')
if __name__ == '__main__':
test_sum_of_column()
Lønnsberegning
RandomFirma AS trenger et program for å beregne hvor mye de skal betale sine timeansatte. Arbeidsmiljøloven krever at ansatte får lønn for 1,5 time for alle timer over 40 som de jobber i løpet av en enkelt uke. For eksempel, hvis en ansatt jobber 45 timer, får de 5 timer overtid, til 1,5 ganger grunnlønnen. Regjeringen har innført minstelønn i bransjen dette firmaet operer i, og minstlønnen er 200 kr per time. RandomFirma AS krever også at en ansatt ikke jobber mer enn 60 timer i en uke.
Her er regler oppsummert:
- En ansatt får betalt (arbeidstimer) × (grunnlønn), for hver time inntil 40 timer.
- For hver time over 40 får de overtid = (grunnlønn) × 1,5.
- Grunnlønnen må ikke være lavere enn minstelønnen (200 i timen).
- Antall timer kan ikke være større enn 60.
I filen salary.py skriv en funksjon weekly_pay(hourly_rate, hours) som tar grunnlønn og antall timer en anstatt har jobbet som parametere, og returnerer enten totallønnen som en tallverdi, eller streng med en feilmelding. Feilmeldingene er 'Minstelønnskravet er ikke oppfylt' eller 'En ansatt jobber mer enn 60 timer'. Dersom begge reglene brytes, skal det returneres 'Minstelønnskravet er ikke oppfylt'.
def test_weekly_pay():
print('Tester weekly_pay... ', end='')
assert 2_000 == weekly_pay(200, 10)
assert 40_000 == weekly_pay(1000, 40)
assert 20_000 == weekly_pay(500, 40)
assert 41_500 == weekly_pay(1000, 41)
assert 70_000 == weekly_pay(1000, 60)
assert 'En ansatt jobber mer enn 60 timer' == weekly_pay(1000, 61)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(199, 40)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(100, 100)
print('OK')
if __name__ == '__main__':
test_weekly_pay()
Raskeste løper
En gruppe venner bestemmer seg for å løpe Bergen City Marathon. Eksempel på fil med navn og tider (i minutter) kan lastes ned her: marathon.txt. I filen fastest_runner.py skriv en funksjon fastest_runner(path) som returnerer navnet på den raskeste løperen og antall minutter vedkommende har brukt som en streng. Parameteren path er en filsti til en fil som inneholder navn og tider for alle løperne.
Du kan anta at hver linje i filen begynner med et fullt navn, etterfulgt av et mellomrom og deretter et heltall som representerer tiden i minutter. Du kan ikke gjøre noen antagelser om hvor mange løpere som er nedtegnet i filen, eller hvor mange etternavn og mellomnavn de har.
def test_fastest_runner():
print('Tester fastest_runner... ', end='')
assert 'Tien Pengyen Fei 199' == fastest_runner('marathon.txt')
print('OK')
if __name__ == '__main__':
test_fastest_runner()
Prikkprodukt
I filen dot_product.py skriv funksjonen dot_product(a, b) som regner ut prikkprodukuktet for to like lange lister med tall a og b. Prikkproduktet er definert som summen av produktene av verdiene som har lik posisjon i de to listene; altså (a[0] * b[0] + a[1] * b[1] + …)
def test_dot_product():
print('Tester dot_product... ', end='')
assert 36 == dot_product([1, 2, 3, 4], [4, 5, 6, 1])
assert 12 == dot_product([0, 6, 1], [400, 1, 6])
assert 651 == dot_product([43, 6], [15, 1])
print('OK')
if __name__ == '__main__':
test_dot_product()
Akvakulturregisteret
I denne oppgaven skal vi bruke datafilen Akvakulturregisteret.csv.
PS: akvakulturregisteret er dessverre ikke lagret i utf-8. Prøv deg frem til du finner riktig encoding (se notater om tekstkoding).
Del A (1 poeng)
I filen aquaculture_a.py skriv en funksjon count_facilities_by_species(path) som tar som input en filsti til akvakulturregisteret, og som så skriver ut til terminalen en unicode-alfabetisk liste over antall oppdrettsanlegg for hver art. Med «unicode-alfabetisk» menes den rekkefølgen man får dersom man sorterer en liste med artsnavn med sorted -funksjonen innebygget i Python. Du kan ta utgangspunkt i følgende kode:
def count_facilities_by_species(path):
... # din kode her
if __name__ == '__main__':
count_facilities_by_species('Akvakulturregisteret.csv')
Eksempel på utskrift når programmet kjøres:
Abbor: 8
Acartia tonsa **(oppdrett): 4
Akkar: 1
Amerikansk hummer: 2
Arctic sea ice amphipod *: 1
Arktisk knurrulke: 1
Berggylt: 58
...
Les innholdet i filen til en egnet datastruktur ved å benytte csv -biblioteket.
Bruk et oppslagsverk (dict) for å telle hver art; bruk en løkke over hver rad i filen.
Første gangen du ser en art, opprett en ny nøkkel med artsnavnet i oppslagsverket og gi den verdien 1
Dersom nøkkelen derimot var i oppslagsverket fra før, øk verdien dens med 1
For å finne artene i ‘alfabetisk’ rekkefølge, bruk
sorted-funksjonen og gi listen med nøklene fra oppslagsverket som argument.
Del B (1 poeng, rettes manuelt)
I filen aquaculture_bc.py, skriv et program som plotter alle oppdrettsanleggene i akvakulturregisteret på et kart. Bruk et scatterplot fra matplotlib for å plotte punktene. Posisjonene til oppdrettsanleggene er gitt i kolonnene som kalles Ø_GEOWGS84 og N_GEOWGS84 i csv-filen. Det er fint om punktene tegnes med en viss gjennomsiktighet.
Når du kjører programmet skal omtrent følgende vises:
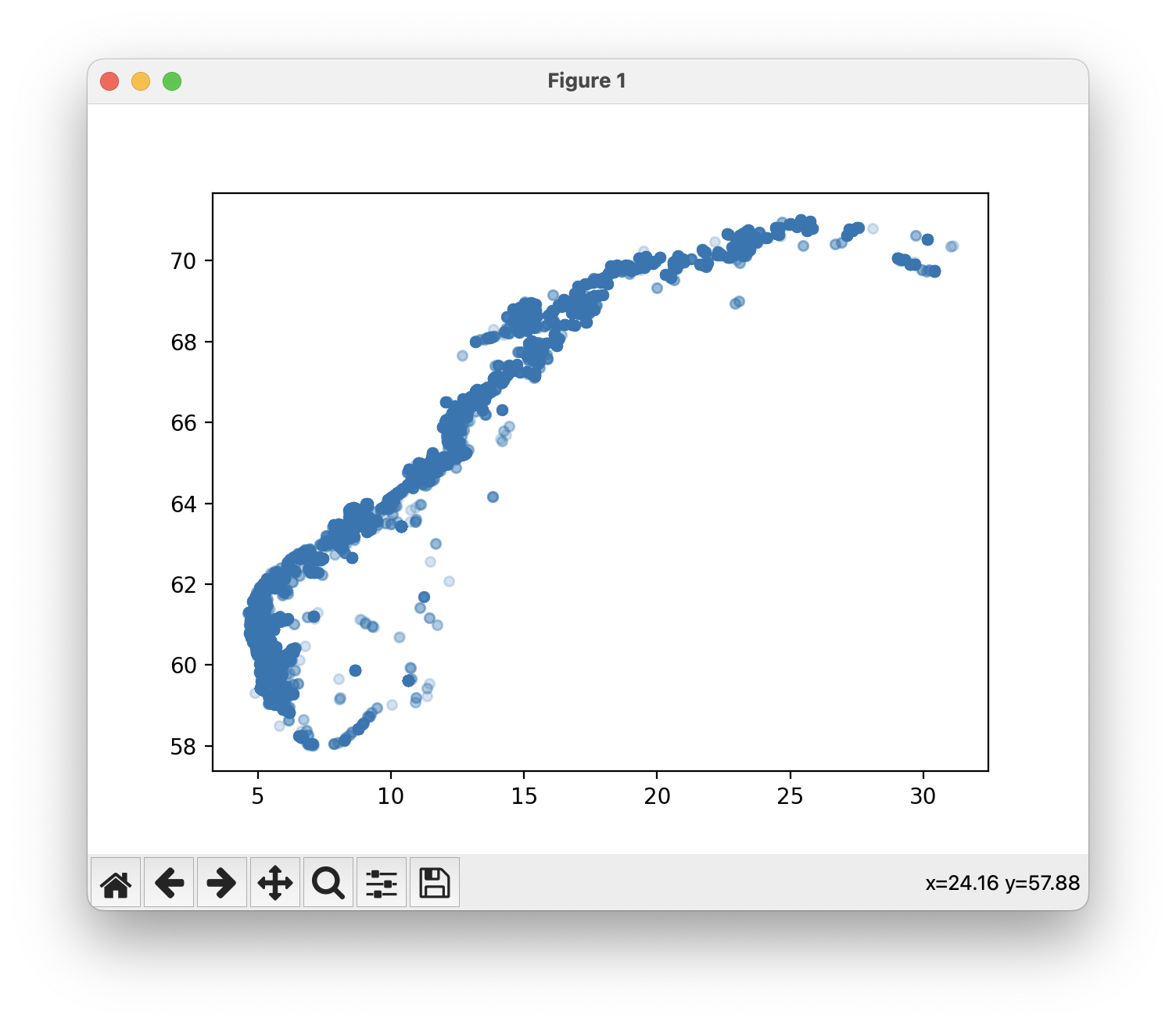
Del C (1 poeng, rettes manuelt)
I filen aquaculture_bc.py, endre programmet slik at punktene får ulik farge avhengig av om det er et oppdrettsanlegg i sjø eller på land.
Når du kjører programmet skal omtrent følgende vises:
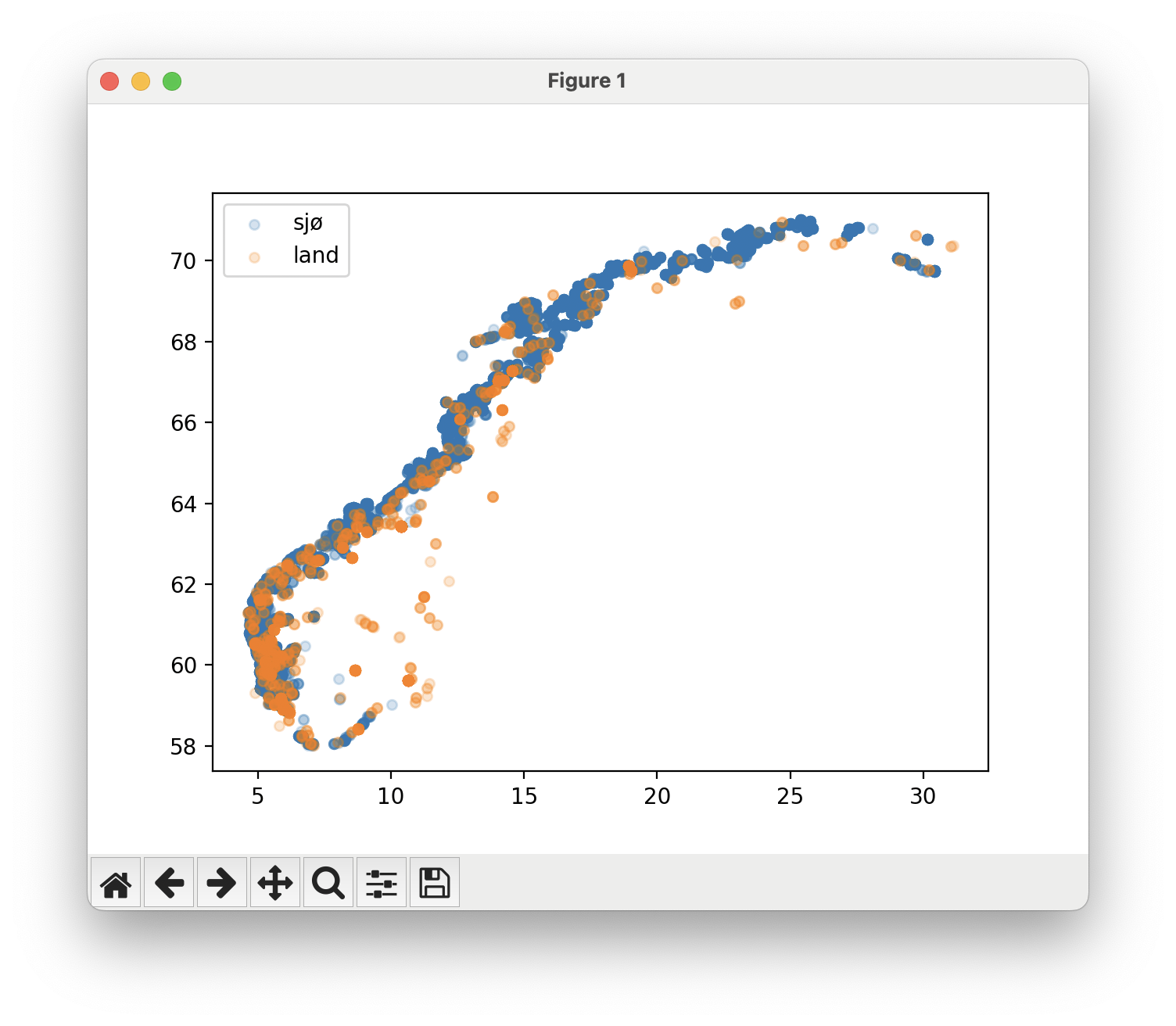
Endre farge på prikk med piltaster
I denne oppgaven skal vi bruke uib_inf100_graphics.event_app for å lage et program hvor brukeren kan forandre fargen på en prikk ved å trykke på piltastene. Denne oppgaven rettes manuelt (det er ingen automatiske tester på CodeGrade).
Les deg gjerne opp på farger i kursnotatene om grafikk før du setter i gang.
En farge er i RGB-systemet representert av tre tall som beskriver lysintensiteten til rødt, grønt og blått lys. Hvert tall er mellom 0 og 255. I programmet vi skal lage i denne oppgaven, skal du tegne en prikk midt på skjermen. Brukeren skal kunne trykke på tastaturet for å endre fargen på prikken
- trykker brukeren på pil opp, økes mengden rød,
- trykker brukeren på pil ned reduseres mengden rød,
- trykker brukeren på pil høyre økes mengden grønn,
- trykker brukeren på pil venstre reduserers mengden grønn,
- trykker brukeren på
aøkes mengden blå, - trykker brukeren på
zreduseres mengden blå.
Ingen farge-verdier skal kunne være mindre enn 0 eller høyere enn 255.
Det ferdige programmet skal skrives i filen colorful_dot.py og skal se omtrent slik ut:
def rgb_to_hex(r, g, b):
return f'#{r:02x}{g:02x}{b:02x}'
# Example usage
hex_string = rgb_to_hex(255, 0, 128)
print(hex_string) # Output: #ff0080
La modellen (app) består av fire variabler: r, g, b (tallverdier) og message (en streng). Initialiser dem i app_started.
La redraw all tegne teksten og en runding midt på skjermen. La fargen være bestemt av r, g og b fra app.
La key_pressed håndtere tastetrykk som beskrevet i oppgaveteksten. I videoen over endres verdien med 10 for hvert tastetrykk.
Bonus:
- Ha ulike modus som bestemmer hvor store steg du tar hver gang. Endre modus ved å trykke på space.
- Ha ulike prikker, der du kan klikke på hvilken prikk du nå skal endre fargen til. Vis hvilken prikk som er valgt f. eks. ved å la den ha outline.