
Lab8
Endelig er den her: semesterets siste lab! I denne lab’en er delt inn i to deler:
- Del A gir til sammen 10 poeng. Oppgavene finner du på CodeGrade/mitt.uib.
- Del B gir til sammen 15 poeng. Oppgavetekstene leser du her på denne nettsiden, og du leverer som vanlig på CodeGrade/mitt.uib.
Lister vs oppslagsverk
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver i én felles fil, list_vs_dictionary.py.
I denne oppgaven skal vi undersøke slektskapet mellom oppslagsverk og lister. En nøkkel spiller på mange måter samme rolle for et oppslagsverk som en indeks gjør for en liste.
Del A
Skriv funksjonen key_value_getter(d) som tar inn en dictionary d, og skriver ut til skjermen nøklene, verdiene og nøkkel/verdi-par.
Eksempelkjøring:
key_value_getter({
"monday": 0,
"tuesday": 0.7,
"wednesday": 0,
"thursday": 4.7,
"friday": 10
})
skal gi utskriften:
Dictionary keys:
monday
tuesday
wednesday
thursday
friday
Dictionary values:
0
0.7
0
4.7
10
Dictionary keys/value:
monday 0
tuesday 0.7
wednesday 0
thursday 4.7
friday 10
Del B
Skriv funksjonen index_value_getter(a) som tar inn en liste a og skriver ut til skjermen indeksene, verdiene og indeks/verdi -parene.
Eksempelkjøring:
index_value_getter([7.0, 8.0, 10.0, 9.0, 10.0])
skal gi utskriften:
List indices:
0
1
2
3
4
List values:
7.0
8.0
10.0
9.0
10.0
List indices/value:
0 7.0
1 8.0
2 10.0
3 9.0
4 10.0
PS: Det skal ikke komme noen utskrift i terminalen dersom noen importerer filen din som en modul. Hvis du vil teste funksjonene dine lokalt på egen maskin kan du legge til dine egne kall til funksjonene nederst i filen din under if __name__ == "__main__":.
Collatz-sekvensen
Collatz-sekvensen er definert som følger:
- Start med et tall \(n\)
- Hvis \(n\) er jevnt så er neste tall \(\frac{n}{2}\), ellers så er neste tall \(3n +1\)
- Repeter steg \(2\) med det nye tallet helt til du får \(1\). Da er du ferdig.
Her er en funksjon som genererer Collatz-sekvensen ut fra en gitt startverdi \(n\):
def collatz_sequence(n):
sequence = [n]
while n > 1:
if n % 2 == 0:
n = n // 2
else:
n = 3 * n + 1
sequence.append(n)
return sequence
I filen collatz.py, skriv en funksjon som heter collect_collatz(a, b) som bruker collatz_sequence -funksjonen gitt over til å beregne Collatz-sekvensen for alle tall fra og med \(a\) og opp til (men ikke inkludert) \(b\). Sekvensene skal returneres i form av et oppslagsverk hvor startverdiene er nøkler.
Test koden din ved å legge til disse linjene nederst i filen:
def test_collect_collatz():
print('Tester collect_collatz... ', end='')
# Test 1
expected = {
1: [1],
2: [2, 1],
3: [3, 10, 5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(1, 4)
assert expected == actual
# Test 2
expected = {
3: [3, 10, 5, 16, 8, 4, 2, 1],
4: [4, 2, 1],
5: [5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(3, 6)
assert expected == actual
print('OK')
if __name__ == '__main__':
test_collect_collatz()
-
Begynn med å opprette et tomt oppslagsverk (som du skal returnere på slutten av funksjonen, når det er ferdig fylt opp med nøkler og verdier).
-
Bruk en løkke for å gå gjennom alle tall fra og med \(a\) opp til men ikke inkludert \(b\).
-
Inne i løkken: gjør et kall til
collatz_sequence-metoden med iteranden som argument. Oppdater oppslagsverket slik at iteranden blir en ny nøkkel med returverdien fra kallet tilcollatz_sequencesom verdi.
Fredag 13.
I filen friday_13th.py skriv en funksjon first_friday_13th_after(date) som tar et datetime-objekt som parameter. Funksjonenen returnerer et nytt datetime-objekt, som befinner seg på første fredag den 13. etter den gitte datoen. Dersom input-datoen selv er på en fredag den 13., er det neste datoen som skal returneres.
Denne oppgaven skal løses ved hjelp av datetime -modulen fra Python sitt standardbibliotek.
Test koden din:
def test_first_friday_13th_after():
print('Tester first_friday_13th_after... ', end='')
# Test 1
result = first_friday_13th_after(datetime(2022, 10, 24))
assert (2023, 1, 13) == (result.year, result.month, result.day)
# Test 2
result = first_friday_13th_after(datetime(2023, 1, 13))
assert (2023, 10, 13) == (result.year, result.month, result.day)
# Test 3
result = first_friday_13th_after(datetime(1950, 1, 1))
assert (1950, 1, 13) == (result.year, result.month, result.day)
print('OK')
-
Se eksempel på bruk av datetime på den offisielle dokumentasjonen for datetime.
-
Kan være lurt å ha en hjelpefunksjon som sjekker om et gitt tidspunkt er på en fredag den trettende.
-
Forsøk å øke datoen med én dag helt til du treffer en dag som er på en fredag den trettende.
Kodesporing
I denne oppgaven skal du se på kode og finne ut hva koden gjør. Denne typen oppgave kommer ofte på eksamen, og er derfor ment som eksamenstrening. Eksamen foregår uten internett og uten noe måte å kjøre koden på, så vi anbefaler at du svarer på disse oppgavene uten å bruke VSCode eller andre hjelpemidler til å kjøre koden.
Her er en json-fil du kan fylle ut for å svare: svar.json
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
x = 42
y = 1
p = 3.14
s = '42'
li = ['42', (4, 5, 6, 7), None]
d = {
p: [s, li],
'x': y,
y: p,
}
print(d[3.14][1][-1])
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
a = 1
b = 2
a = a + b
b = a * b
a -= 1
print(b - a)
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
def decremented(x):
return x - 1
def foo(x):
x += 2
return x + decremented(x)
x = 3
x = foo(x)
print(x)
Hva skriver dette programmet ut? (hvis programmet krasjer, skriv kun Error)
s = 'abc'
t = ''
for c in s:
t = c + t
print(t)
t = ['a', 'b', 'c']
for i in range(len(t)):
m = t[i]
t[i] = t[i-1]
t[i-1] = m
Hvilken verdi har t etter at kodesnutten har kjørt? (i svar.json, skriv svaret ditt som én stor bokstav)
Alternativer:
| A | ['a', 'b', 'c'] |
| B | ['a', 'c', 'b'] |
| C | ['b', 'a', 'c'] |
| D | ['b', 'c', 'a'] |
| E | ['c', 'a', 'b'] |
| F | ['c', 'b', 'a'] |
| G | Programmet krasjer |
Studentregister
Du har et register med studentdata i en JSON-fil. I filen student_registry.py skal du lage en funksjon convert_students_to_csv som tar inn en sti til en JSON-fil med studentdata og en sti til en CSV-fil, og som så skriver dataen til CSV-filen med CSV-format. Bruk semikolon som skillesymbol i CSV-filen du oppretter.
Eksempler på studentdata i en JSON-fil:
{
"students": [
{
"id": 1,
"name": "Alice",
"area": "Biology",
"year": "1"
},
{
"id": 2,
"name": "Bob",
"area": "Chemistry",
"year": "2"
},
{
"id": 3,
"name": "Charlie",
"area": "Physics",
"year": "4"
}
]
}
JSON-filen representerer et oppslagsverk med én nøkkel, «students», der tilhørende verdi er en liste med oppslagsverk. Hvert oppslagsverk i denne listen representerer en student og har nøklene «id», «name», «area» og «year».
Når du har konvertert dataen fra students.json til en csv-filen, skal innholdet den se slik ut:
id;name;area;year
1;Alice;Biology;1
2;Bob;Chemistry;2
3;Charlie;Physics;4
Du kan laste ned eksemplene students.json og students2.json, programmet ditt skal fungere for begge disse samt andre JSON-filer som følger samme struktur.
-
Lag en funksjon convert_students_to_csv som tar inn en filsti til en JSON-fil med studentdata og en filsti til en CSV-fil.
-
Les innholdet fra json-filen til en streng og konverter strengen til et oppslagsverk
datamed loads -funksjonen fra den innbygde json modulen. -
Legg merke til at for hver student skal du til syvende og sist opprette én linje i den endelige strengen som skal bli innholdet i csv-filen. I tillegg kommer den øverste linjen i CSV-filen med overskriftene.
-
Gå gjennom
data['students']med en for-løkke. I hver iterasjon av løkken vil iteranden referere til et nytt oppslagsverk som representerer en student.
For å teste funksjonen din, legg til den følgende koden på slutten av filen din og sjekk at csv-filen blir skrevet til disk slik som vist over.
if __name__ == "__main__":
convert_students_to_csv("students.json", "students.csv")
convert_students_to_csv("students2.json", "students2.csv")
Polynom
Forberedelser: Gjør tutorial for pyplot og les gjennom notatene om det eksterne biblioteket matplotlib
I denne oppgaven skal du lage en funksjon som bruker matplotlib til å visualisere en andregradsfunksjon. I filen function_visualiser.py lag en funksjon plot_polynomial som har parametre for koeffisientene a, b og c til en andregradsfunksjon, og en samling med tall xs som angir x-verdiene som skal plottes. Funksjonen skal plotte funksjonen for disse x-verdiene med matplotlib. Vi skal også sette navn på aksene og gi plottet en tittel. Aksenavnene skal være «x» og «f(x)», og tittelen skal være «f(x) = ax^2 + bx + c» hvor du setter inn riktige verdier for a, b og c (se også eksempel under).
Husk at en andregradsfunksjon er gitt ved formelen: $$f(x) = ax^2 + bx + c$$
For å teste funksjonen, legg til dette på slutten av filen (gitt at du har importert matplotlib ved import matplotlib.pyplot as plt):
import matplotlib.pyplot as plt
def plot_polynomial(a, b, c, xs):
... # din kode her
if __name__ == "__main__":
plot_polynomial(1, -5, 100, [-10, -8, -6, -4, -2, 0, 2, 4, 6, 8, 10])
plt.show() # ha gjerne plt.show() utenfor plot_polynomial
Du skal få et vindu som ser omtrent slik ut hvis du har gjort det riktig:
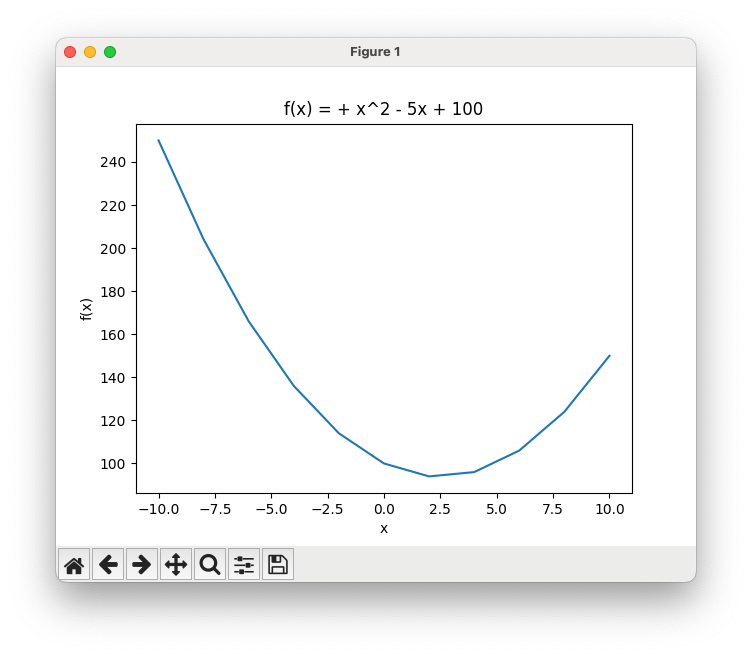
Siden det ser litt rart ut å ha «1x^2» i tittelen når a = 1, eller « + -3x» når b = -3, kan du lage en funksjon som setter riktig fortegn foran koeffisientene a, b og c i tittelen. Her er forslag til en måte å gjøre det på som blir litt finere, selv om heller ikke denne tar hensyn til alt:
def coeff_string(coefficient):
if coefficient == 1:
return " + "
elif coefficient == 0:
return None
elif coefficient >= 0:
return f" + {coefficient}"
elif coefficient < 0:
return f" - {abs(coefficient)}"
Du kan da bruke f-strengen
f'f(x) ={coeff_string(a)}x^2{coeff_string(b)}x{coeff_string(c)}'
som tittel på plottet.
Bonusoppgave (helt frivillig): lag en funksjon get_polynomial_string med en parameter coefficients som får gitt en liste med koeffisienter som argument. Funksjonen returnerer en pen strengrepresentasjon av funksjonsuttrykket.
def test_get_polynomial_string():
assert '2x^2 + 4x + 5' == get_polynomial_string([2, 4, 5])
assert '3x^3 + 2x^2 + 4x + 5' == get_polynomial_string([3, 2, 4, 5])
assert '3x^3 - 2x^2 + 4x + 5' == get_polynomial_string([3, -2, 4, 5])
assert '- 3x^3 + 2x^2 + 4x + 5' == get_polynomial_string([-3, 2, 4, 5])
assert '3x^3 + 4x - 5' == get_polynomial_string([3, 0, 4, -5])
assert '2x^2' == get_polynomial_string([2, 0, 0])
assert '- 3x' == get_polynomial_string([0, -3, 0])
assert '0' == get_polynomial_string([0, 0, 0])
assert '5' == get_polynomial_string([5])
assert '0' == get_polynomial_string([])
I funksjonen plot_function kan du gjøre følgende:
- Opprett en liste som inneholder \(f(x)\) for alle verdiene \(x\) i
xs. Dette blir altså en liste over y-verdiene. - Bruk
plt.plot(xs, ys)for å plotte funksjonen hvoryser y-verdiene du regnet ut i steg 1. - Sett navn på aksene med
plt.xlabelogplt.ylabel-funksjonene. - Bruk
plt.titleog en f-streng for å sette tittel. På grunn av fortegnene kan det bli litt kluss når du får negative koeffisienter, så se gjerne på hintet over for å få det til.
Filter for høye temperaturer
I filen filter_high_temperatures.py, skriv en funksjon som heter filter_high_temperatures med parametre:
path_input, en filsti til en eksisterende fil hvor hver linje inneholder først en dag, deretter et mellomrom, og så en temperatur. For eksempel, temperatures.txt.path_output, en filsti til en fil som skal opprettes, ogthreshold_temp, et flyttall som representerer en temperatur.
La funksjonen åpne filen path_input, gå gjennom linjene i filen og lager en ny fil path_output hvor kun de linjene der temperaturen er minst threshold_temp er inkludert. Om ingen dager har en temperatur som er minst threshold_temp så skal path_output være en tom fil.
For å teste programmet ditt, legg til nederst i filen:
def test_filter_high_temperatures():
print('Tester filter_high_temperatures... ', end='')
filter_high_temperatures('temperatures.txt', 'high_temps.txt', 23.5)
expected = (
'Monday 23.5\n'
'Wednesday 24.0\n'
'Thursday 23.9\n'
'Sunday 23.9\n'
)
with open('high_temps.txt', 'rt', encoding='utf-8') as file:
actual = file.read()
assert expected.strip() == actual.strip()
print('OK')
if __name__ == '__main__':
test_filter_high_temperatures()
Lønnsberegning
RandomFirma AS trenger et program for å beregne hvor mye de skal betale sine timeansatte. Arbeidsmiljøloven krever at ansatte får lønn for 1,5 time for alle timer over 40 som de jobber i løpet av en enkelt uke. For eksempel, hvis en ansatt jobber 45 timer, får de 5 timer overtid, til 1,5 ganger grunnlønnen. Regjeringen har innført minstelønn i bransjen dette firmaet operer i, og minstlønnen er 200 kr per time. RandomFirma AS krever også at en ansatt ikke jobber mer enn 60 timer i en uke.
Her er regler oppsummert:
- En ansatt får betalt (arbeidstimer) × (grunnlønn), for hver time inntil 40 timer.
- For hver time over 40 får de overtid = (grunnlønn) × 1,5.
- Grunnlønnen må ikke være lavere enn minstelønnen (200 i timen).
- Antall timer kan ikke være større enn 60.
I filen salary.py skriv en funksjon weekly_pay(hourly_rate, hours) som tar grunnlønn og antall timer en anstatt har jobbet som parametere, og returnerer enten totallønnen som en tallverdi, eller streng med en feilmelding. Feilmeldingene er 'Minstelønnskravet er ikke oppfylt' eller 'En ansatt jobber mer enn 60 timer'. Dersom begge reglene brytes, skal det returneres 'Minstelønnskravet er ikke oppfylt'.
def test_weekly_pay():
print('Tester weekly_pay... ', end='')
assert 2_000 == weekly_pay(200, 10)
assert 40_000 == weekly_pay(1000, 40)
assert 20_000 == weekly_pay(500, 40)
assert 41_500 == weekly_pay(1000, 41)
assert 70_000 == weekly_pay(1000, 60)
assert 'En ansatt jobber mer enn 60 timer' == weekly_pay(1000, 61)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(199, 40)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(100, 100)
print('OK')
if __name__ == '__main__':
test_weekly_pay()
Endre farge på prikk med piltaster
I denne oppgaven skal vi bruke uib_inf100_graphics.event_app for å lage et program hvor brukeren kan forandre fargen på en prikk ved å trykke på piltastene. Denne oppgaven rettes manuelt (det er ingen automatiske tester på CodeGrade).
Les deg gjerne opp på farger i kursnotatene om grafikk før du setter i gang.
En farge er i RGB-systemet representert av tre tall som beskriver lysintensiteten til rødt, grønt og blått lys. Hvert tall er mellom 0 og 255. I programmet vi skal lage i denne oppgaven, skal du tegne en prikk midt på skjermen. Brukeren skal kunne trykke på tastaturet for å endre fargen på prikken
- trykker brukeren på pil opp, økes mengden rød,
- trykker brukeren på pil ned reduseres mengden rød,
- trykker brukeren på pil høyre økes mengden grønn,
- trykker brukeren på pil venstre reduserers mengden grønn,
- trykker brukeren på
aøkes mengden blå, - trykker brukeren på
zreduseres mengden blå.
Ingen farge-verdier skal kunne være mindre enn 0 eller høyere enn 255.
Det ferdige programmet skal skrives i filen colorful_dot.py og skal se omtrent slik ut:
def rgb_to_hex(r, g, b):
return f'#{r:02x}{g:02x}{b:02x}'
# Example usage
hex_string = rgb_to_hex(255, 0, 128)
print(hex_string) # Output: #ff0080
-
La modellen (app) består av fire variabler: r, g, b (tallverdier) og message (en streng). Initialiser dem i app_started.
-
La redraw all tegne teksten og en runding midt på skjermen. La fargen være bestemt av r, g og b fra app.
-
La key_pressed håndtere tastetrykk som beskrevet i oppgaveteksten. I videoen over endres verdien med 10 for hvert tastetrykk.
Bonus:
- Ha ulike modus som bestemmer hvor store steg du tar hver gang. Endre modus ved å trykke på space.
- Ha ulike prikker, der du kan klikke på hvilken prikk du nå skal endre fargen til. Vis hvilken prikk som er valgt f. eks. ved å la den ha outline.
I denne oppgaven (som rettes manuelt) er det nå mulig å få 1 bonuspoeng. Det er fortsatt 15 poeng man trenger til 100% av lab8 DelB, sånn at det faktisk er bonus og kan balansere poeng man mister på andre oppgaver.
Akvakulturregisteret
I denne oppgaven skal vi bruke datafilen Akvakulturregisteret.csv.
PS: akvakulturregisteret er dessverre ikke lagret i utf-8. Prøv deg frem til du finner riktig encoding (se notater om tekstkoding).
Del A
I filen aquaculture_a.py skriv en funksjon count_facilities_by_species(path) som tar som input en filsti til akvakulturregisteret, og som så skriver ut til terminalen en unicode-alfabetisk liste over antall oppdrettsanlegg for hver art. Med «unicode-alfabetisk» menes den rekkefølgen man får dersom man sorterer en liste med artsnavn med sorted -funksjonen innebygget i Python. Du kan ta utgangspunkt i følgende kode:
def count_facilities_by_species(path):
... # din kode her
if __name__ == '__main__':
count_facilities_by_species('Akvakulturregisteret.csv')
Eksempel på utskrift når programmet kjøres:
Abbor: 8
Acartia tonsa **(oppdrett): 4
Akkar: 1
Amerikansk hummer: 2
Arctic sea ice amphipod *: 1
Arktisk knurrulke: 1
Berggylt: 58
...
-
Les innholdet i filen til en egnet datastruktur ved å benytte csv -biblioteket.
-
Bruk et oppslagsverk (dict) for å telle hver art; bruk en løkke over hver rad i filen.
-
Første gangen du ser en art, opprett en ny nøkkel med artsnavnet i oppslagsverket og gi den verdien 1
-
Dersom nøkkelen derimot var i oppslagsverket fra før, øk verdien dens med 1
-
For å finne artene i ‘alfabetisk’ rekkefølge, bruk
sorted-funksjonen og gi listen med nøklene fra oppslagsverket som argument.
Del B
I filen aquaculture_bc.py, skriv et program som plotter alle oppdrettsanleggene i akvakulturregisteret på et kart. Bruk et scatterplot fra matplotlib for å plotte punktene. Posisjonene til oppdrettsanleggene er gitt i kolonnene som kalles Ø_GEOWGS84 og N_GEOWGS84 i csv-filen. Det er fint om punktene tegnes med en viss gjennomsiktighet.
Når du kjører programmet skal omtrent følgende vises:
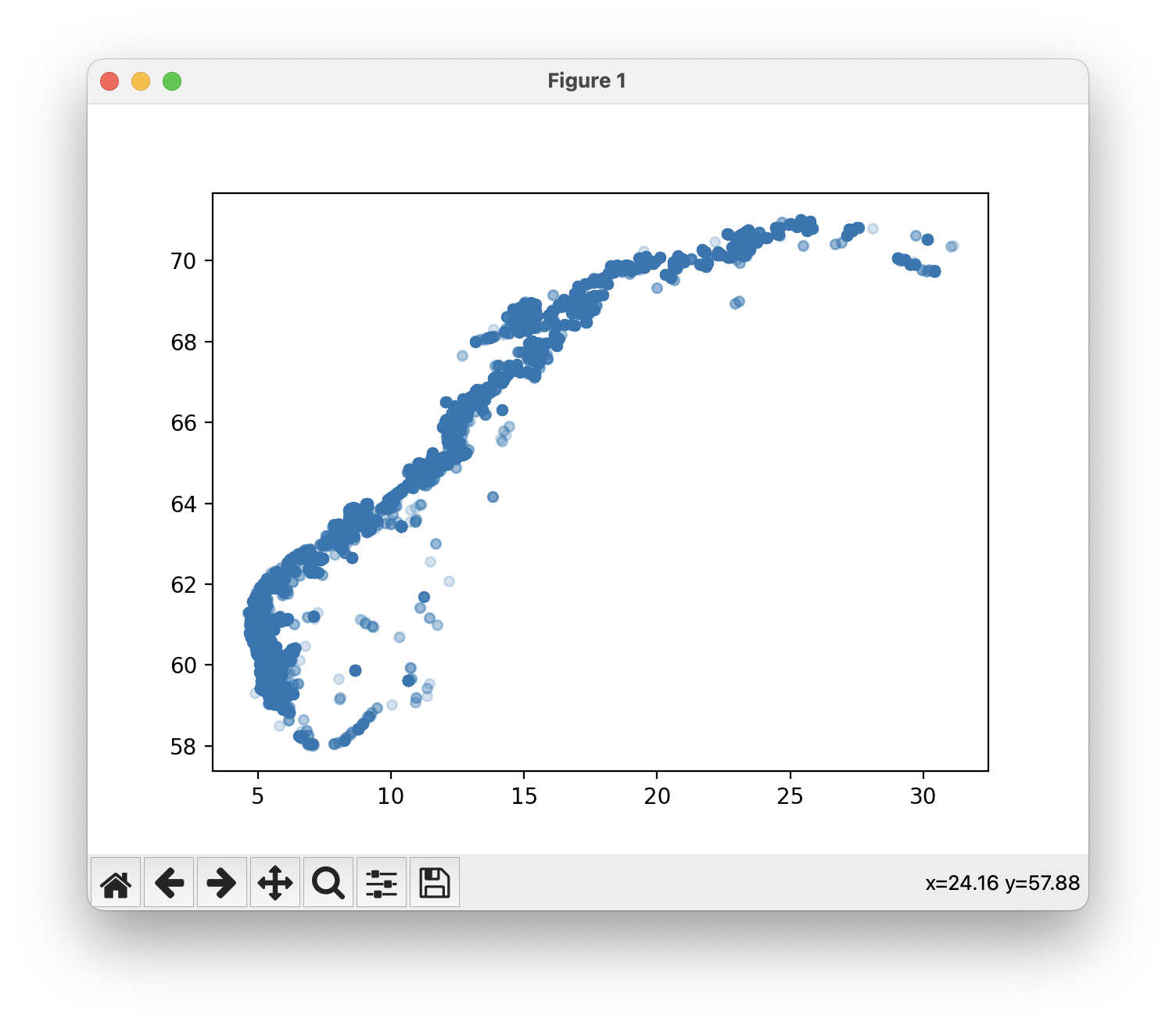
Del C
I filen aquaculture_bc.py, endre programmet slik at punktene får ulik farge avhengig av om det er et oppdrettsanlegg i sjø eller på land.
Når du kjører programmet skal omtrent følgende vises:
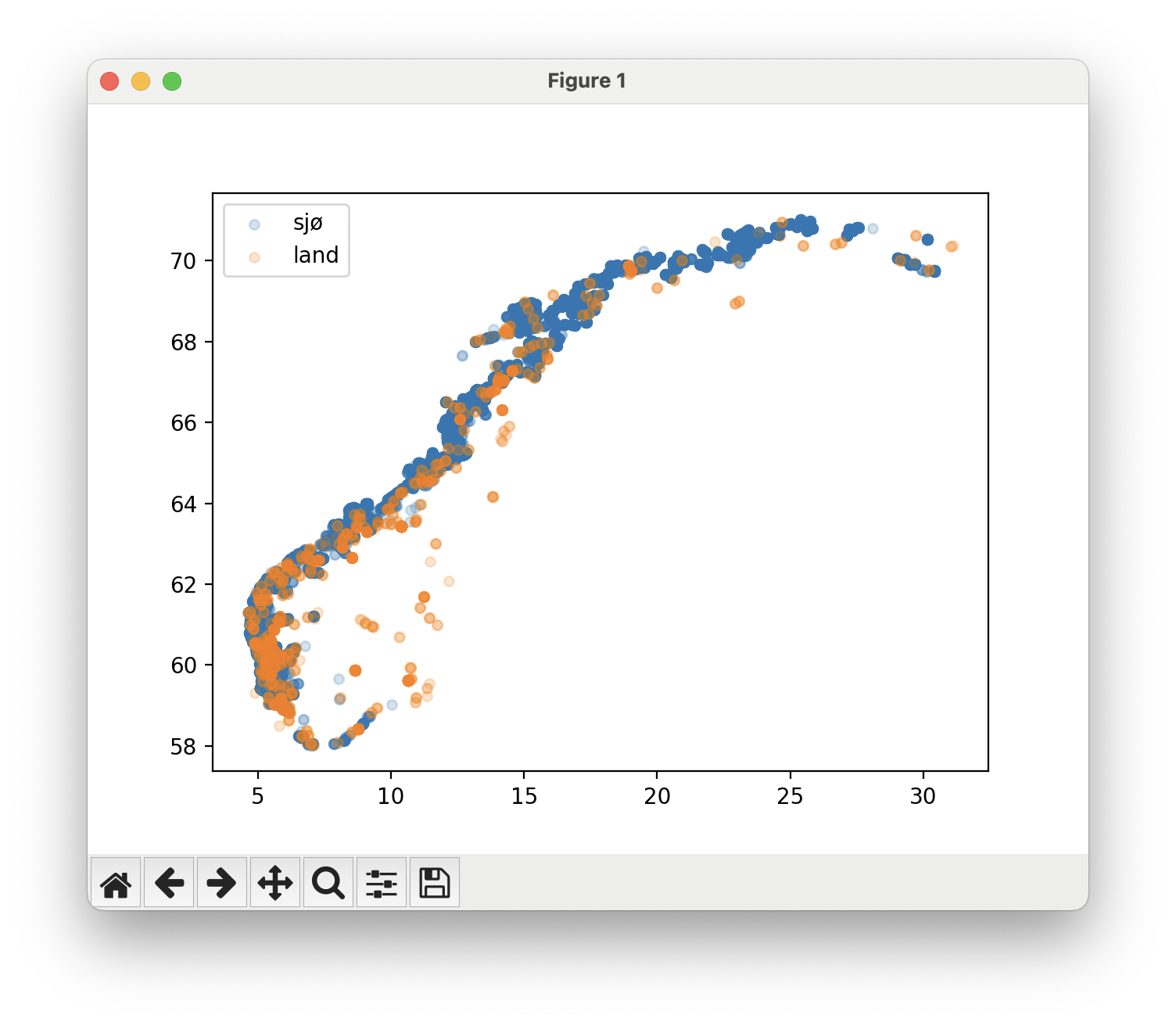
Lengste varmeperiode (dummydata)
I denne oppgaven skal du skrive en funksjon som finner den lengste sammenhengende perioden med temperaturer over ett gitt antall varmegrader.
I filen longest_hot_period_dummy.py, skriv en funksjon longest_hot_period(temperatures, threshold) som tar inn en liste temperatures med temperaturer og et flyttall threshold som representerer hvor mange grader som definerer en varm dag. Funksjonen skal returnere indeksene som definerer den lengste sammenhengende perioden med temperaturer med threshold eller flere varmegrader. Hvis det er flere perioder som er like lange, skal den returnere den tidligste perioden.
Hvis det ikke er noen perioder med temperaturer over threshold, skal funksjonen returnere (-1, -1). Se også eksemplene i testene du kan lime inn nederst i filen for å se hvordan funksjonen skal fungere.
Følg konvensjon for start og sluttindekser i Python (start, end):
starter den første indeksen i perioden, inklusiv. Det betyr at den peker på den første verdien i perioden.ender den siste indeksen i perioden, eksklusiv. Det betyr at den peker på den første verdien etter perioden. Om det er den siste verdien i listen, så erendlik lengden på listen.
def test_longest_hot_period():
print('Testing longest_hot_period... ', end='')
temps = [25, 23, 19, 22, 24, 25, 21, 25, 26]
threshold = 22
expected_start, expected_end = 3, 6
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 23
expected_start, expected_end = 0, 2
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 15
expected_start, expected_end = 0, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 21
expected_start, expected_end = 3, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 25
expected_start, expected_end = 7, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 30
expected_start, expected_end = -1, -1
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
print('OK')
if __name__ == '__main__':
test_longest_hot_period()
Lengste varmeperiode (ekte data)
I denne oppgaven skal du skrive en funksjon som finner den lengste sammenhengende perioden der hver dag har temperaturer over ett gitt antall varmegrader. Denne gangen skal vi bruke ekte data hentet fra frost.met.no.
- Å hente data fra frost.met.no er gratis, men for å hindre misbruk må du registrere deg. Registrering er en uvanlig kortfattet prosess som du kan gjøre her: https://frost.met.no/auth/requestCredentials.html. For å gjennomføre denne oppgaven må du ta vare på din client_id; for enkelhets skyld kan du kopiere denne inn i en fil som heter client_id.txt. I kodeeksemplene under antar vi at din client id er det eneste som ligger lagret i denne filen.
Full dokumentasjon for hva slags data du kan hente fra frost.met.no kan være litt overveldende; vi presenterer derfor noen relevante eksempler vi kan begynne å utforske her.
import requests
import json
from pathlib import Path
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
api_endpoint = 'https://frost.met.no/observations/v0.jsonld'
source_id = 'SN50540' # SN50540 er Florida målestasjon i Bergen
response = requests.get(
api_endpoint,
params={
'sources': source_id,
'referencetime': '2024-04-01/2024-04-07',
'elements': 'mean(air_temperature P1D)',
'levels': 'default',
'timeoffsets': 'default',
},
headers={'User-Agent': 'inf100.ii.uib.no student'},
auth=(client_id, '')
)
json_data = response.json()
print(json.dumps(json_data, indent=2))
Tips for å utforske dataene du mottar: sett et breakpoint like etter at
json_datahar blitt opprettet, og bruk debuggeren for å utforske hva som ligger i denne variabelen.
- client_id er en variabel som peker på en streng, nemlig din client id.
- api_endpoint er en variabel som peker på en streng, nemlig adressen til frost.met.no hvor vi kan hente data.
- source_id er en variabel som peker på en streng, i dette tilfellet representerer strengen id-en til Florida målestasjon i Bergen.
- response er en variabel som peker på responsen vi får fra frost.met.no når vi spør om data.
Argumentene vi gir ved kallet til requests.get er
- api_endpoint er stammen for nettadressen hvor vi henter data. Dette utgjør begynnelsen av en URL/nettadresse.
- til params gir vi et oppslagsverk med nøkkel-verdi-par som vil utgjøre slutten av url’en. Den komplette URL’en vil til slutt bli
https://frost.met.no/observations/v0.jsonld?sources=SN50540&referencetime=2024-04-01/2024-04-07&elements=mean(air_temperature%20P1D)&levels=default&timeoffsets=default. Vi kunne laget denne strengen på andre måter og ikke benyttet params-parameteren i det hele tatt; men det ser mer oversiktelig og fint ut å bruke params og et oppslagsverk enn å bedrive omfattende streng-manipulasjon på egen hånd.- sources er en komma-separert liste over målestasjoner vi ønsker data fra. I vårt tilfelle er det kun én målestasjon.
- referencetime tidsrommet vi ønsker måledata fra.
<fra dato>/<til dato>. Merk at fra-dato er inklusiv mens til-dato er ekslusiv (i tråd med god standard praksis i programmering for øvrig). - elements angir hva slags måledata vi ønsker. Strengen
mean(air_temperature P1D)innebærer at vi ønsker oss gjennomsnittstemperaturen for tidsperioder på én dag. - levels angir hvilket «nivå» målingen er gjort på. For temperaturdata er standardnivået 2 meter over bakken, mens noen målestasjoner har temperaturmålinger også på andre høyder. Ved å angi
defaulther eksluderer vi data fra andre målehøyder enn standardnivået. - timeoffsets angir hvilket tidspunkt på døgnet gjennomsnittsmålingen begynner. Default som verdi her betyr at gjennomsnittsmålingen begynner ved midnatt.
- til headers gir vi et oppslagsverk hvor vi angir en verdi for «User-Agent». Dette feltet benyttes for å beskrive hva slags software som brukes.
- til auth gir vi en tuple med (brukernavn, passord). I vårt tilfelle er ikke passord nødvendig, siden frost.met.no ikke krever dette når vi bare ber om å lese informasjon. Derfor oppgir vi en tom streng som passord.
requests har innebygget en metode for å konvertere en respons som kommer i json-format til et oppslagsverk/json-objekt. Dette gjøres ved å kalle response.json(). Vi bruker json.dumps for å skrive ut dette oppslagsverket på en lesbar måte.
Et lite program for å finne id’ene til værstasjoner i Bergen. Vi laster først ned en oversikt over alle værstasjoner i Norge, og søker etter dem som har Bergen i navnet.
import requests
from pathlib import Path
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
api_endpoint = 'https://frost.met.no/sources/v0.jsonld'
response = requests.get(
api_endpoint,
headers={'User-Agent': 'inf100.ii.uib.no student'},
auth=(client_id, '')
)
json_data = response.json()
for item in json_data['data']:
if 'name' not in item:
continue
if 'bergen' in item['name'].lower():
print(item['id'], item['name'])
I filen longest_hot_period_realdata.py skriv en funksjon longest_hot_period(client_id, source_id, start_date, end_date, threshold) som tar inn en client id, en stasjonsid, en start-dato, en slutt-dato og en temperaturgrense, og som så returnerer den lengste sammenhengende perioden i den angitte perioden med temperaturer over threshold. Hvis det ikke er noen perioder med temperaturer over threshold, skal funksjonen returnere (None, None). Dersom det er flere periode med samme varighet, skal den siste av dem returneres.
Her skal du returnere datetime.datetime objekter for start og slutt slik som du ser i testen under. Følg fortsatt konvensjon for start og sluttpunkt i Python (start er første dag i perioden, slutt er første dag etter perioden)
from pathlib import Path
from datetime import datetime
def longest_hot_period(client_id, source_id, start_date, end_date, threshold):
... # din kode her
def test_longest_hot_period():
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
start_date = datetime(year=2000, month=1, day=1)
end_date = datetime(year=2024, month=1, day=1)
threshold = 20
source_id = 'SN50540' # Florida målestasjon i Bergen
actual_start, actual_end = longest_hot_period(
client_id, source_id, start_date, end_date, threshold
)
actual_start = actual_start.replace(tzinfo=None) # Fjerner tidssone
actual_end = actual_end.replace(tzinfo=None) # Fjerner tidssone
expected_start = datetime(year=2009, month=6, day=25)
expected_end = datetime(year=2009, month=7, day=5)
assert actual_start == expected_start
assert actual_end == expected_end
if __name__ == '__main__':
test_longest_hot_period()