
Lab8
Endelig er den her: semesterets siste lab! Denne lab’en er basert på poeng, og hver oppgave gir litt poeng. Det er maksimalt mulig å oppnå 25 poeng; så selv om du løser oppgaver som summerer til enda mer, får du likevel ikke bare 25 poeng på laben.
- Alle poenggivende oppgaver rettes automatisk. Hvis du ikke består de automatiske testene, får du ikke poeng.
- Vi vil trekke poeng manuelt dersom vi oppdager at oppgaven åpenbart ikke er løst, eller man forsøker å trikse seg gjennom de automatiske testene.
- Hver lab kan leveres så mange ganger du vil; det er siste innlevering som teller. Du kan umiddelbart se resultatene på de automatiske testene og hvor mange poeng du har fått etter hver innlevering.
Hver lab utgjør 2.5% av den endelige karakteren din i emnet. Du må få til sammen 100 poeng eller mer på labene for å kunne ta eksamen.
Det er veldig viktig at du siterer alle kilder og eventuelle samarbeid. Se mitt.uib for mer informasjon om vår policy på plagiat og samarbeid.
Det er lurt å levere inn mange ganger underveis. Du får umiddelbart en automatisk tilbakemelding på oppgavene, og du kan prøve igjen hvis noe ikke virker.
Lister vs oppslagsverk
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver i én felles fil, list_vs_dictionary.py.
I denne oppgaven skal vi undersøke slektskapet mellom oppslagsverk og lister. En nøkkel spiller på mange måter samme rolle for et oppslagsverk som en indeks gjør for en liste.
Del A
Skriv funksjonen key_value_getter(d) som tar inn en dictionary d, og skriver ut til skjermen nøklene, verdiene og nøkkel/verdi-par.
Eksempelkjøring:
key_value_getter({
"monday": 0,
"tuesday": 0.7,
"wednesday": 0,
"thursday": 4.7,
"friday": 10
})
skal gi utskriften:
Dictionary keys:
monday
tuesday
wednesday
thursday
friday
Dictionary values:
0
0.7
0
4.7
10
Dictionary keys/value:
monday 0
tuesday 0.7
wednesday 0
thursday 4.7
friday 10
Del B
Skriv funksjonen index_value_getter(a) som tar inn en liste a og skriver ut til skjermen indeksene, verdiene og indeks/verdi -parene.
Eksempelkjøring:
index_value_getter([7.0, 8.0, 10.0, 9.0, 10.0])
skal gi utskriften:
List indices:
0
1
2
3
4
List values:
7.0
8.0
10.0
9.0
10.0
List indices/value:
0 7.0
1 8.0
2 10.0
3 9.0
4 10.0
PS: Det skal ikke komme noen utskrift i terminalen dersom noen importerer filen din som en modul. Hvis du vil teste funksjonene dine lokalt på egen maskin kan du legge til dine egne kall til funksjonene nederst i filen din under if __name__ == "__main__":.
Collatz-sekvensen
Collatz-sekvensen er definert som følger:
- Start med et tall \(n\)
- Hvis \(n\) er jevnt så er neste tall \(\frac{n}{2}\), ellers så er neste tall \(3n +1\)
- Repeter steg \(2\) med det nye tallet helt til du får \(1\). Da er du ferdig.
Her er en funksjon som beregner Collatz-sekvensen gitt en en startverdi \(n\):
def collatz_sequence(n):
sequence = [n]
while n > 1:
if n % 2 == 0:
n = n // 2
else:
n = 3 * n + 1
sequence.append(n)
return sequence
I filen collatz.py, skriv en funksjon som heter collect_collatz(a, b) som bruker collatz_sequence -funksjonen gitt over til å beregne Collatz-sekvensen for alle tall fra og med \(a\) og opp til (men ikke inkludert) \(b\). Sekvensene skal returneres i form av et oppslagsverk hvor startverdiene er nøkler.
Test koden din ved å legge til disse linjene nederst i filen:
def test_collect_collatz():
print('Tester collect_collatz... ', end='')
# Test 1
expected = {
1: [1],
2: [2, 1],
3: [3, 10, 5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(1, 4)
assert expected == actual
# Test 2
expected = {
3: [3, 10, 5, 16, 8, 4, 2, 1],
4: [4, 2, 1],
5: [5, 16, 8, 4, 2, 1],
}
actual = collect_collatz(3, 6)
assert expected == actual
print('OK')
if __name__ == '__main__':
test_collect_collatz()
Begynn med å opprette et tomt oppslagsverk (som du skal returnere på slutten av funksjonen, når det er ferdig fylt opp med nøkler og verdier).
Bruk en løkke for å gå gjennom alle tall fra og med \(a\) opp til men ikke inkludert \(b\).
Inne i løkken: gjør et kall til
collatz_sequence-metoden med iteranden som argument. Oppdater oppslagsverket slik at iteranden blir en ny nøkkel med returverdien fra kallet tilcollatz_sequencesom verdi.
Filter for høye temperaturer
I filen filter_high_temperatures.py, skriv en funksjon som heter filter_high_temperatures med parametre:
path_input, en filsti til en eksisterende fil hvor hver linje inneholder først en dag, deretter et mellomrom, og så en temperatur. For eksempel, temperatures.txt.path_output, en filsti til en fil som skal opprettes, ogthreshold_temp, et flyttall som representerer en temperatur.
La funksjonen åpne filen path_input, gå gjennom linjene i filen og lager en ny fil path_output hvor kun de linjene der temperaturen er minst threshold_temp er inkludert. Om ingen dager har en temperatur som er minst threshold_temp så skal path_output være en tom fil.
For å teste programmet ditt, legg til nederst i filen:
def test_filter_high_temperatures():
print('Tester filter_high_temperatures... ', end='')
filter_high_temperatures('temperatures.txt', 'high_temps.txt', 23.5)
expected = (
'Monday 23.5\n'
'Wednesday 24.0\n'
'Thursday 23.9\n'
'Sunday 23.9\n'
)
with open('high_temps.txt', 'rt', encoding='utf-8') as file:
actual = file.read()
assert expected.strip() == actual.strip()
print('OK')
if __name__ == '__main__':
test_filter_high_temperatures()
Lønnsberegning
RandomFirma AS trenger et program for å beregne hvor mye de skal betale sine timeansatte. Arbeidsmiljøloven krever at ansatte får lønn for 1,5 time for alle timer over 40 som de jobber i løpet av en enkelt uke. For eksempel, hvis en ansatt jobber 45 timer, får de 5 timer overtid, til 1,5 ganger grunnlønnen. Regjeringen har innført minstelønn i bransjen dette firmaet operer i, og minstlønnen er 200 kr per time. RandomFirma AS krever også at en ansatt ikke jobber mer enn 60 timer i en uke.
Her er regler oppsummert:
- En ansatt får betalt (arbeidstimer) × (grunnlønn), for hver time inntil 40 timer.
- For hver time over 40 får de overtid = (grunnlønn) × 1,5.
- Grunnlønnen må ikke være lavere enn minstelønnen (200 i timen).
- Antall timer kan ikke være større enn 60.
I filen salary.py skriv en funksjon weekly_pay(hourly_rate, hours) som tar grunnlønn og antall timer en anstatt har jobbet som parametere, og returnerer enten totallønnen som en tallverdi, eller streng med en feilmelding. Feilmeldingene er 'Minstelønnskravet er ikke oppfylt' eller 'En ansatt jobber mer enn 60 timer'. Dersom begge reglene brytes, skal det returneres 'Minstelønnskravet er ikke oppfylt'.
def test_weekly_pay():
print('Tester weekly_pay... ', end='')
assert 2_000 == weekly_pay(200, 10)
assert 40_000 == weekly_pay(1000, 40)
assert 20_000 == weekly_pay(500, 40)
assert 41_500 == weekly_pay(1000, 41)
assert 70_000 == weekly_pay(1000, 60)
assert 'En ansatt jobber mer enn 60 timer' == weekly_pay(1000, 61)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(199, 40)
assert 'Minstelønnskravet er ikke oppfylt' == weekly_pay(100, 100)
print('OK')
if __name__ == '__main__':
test_weekly_pay()
Pinlig party
Denne oppgaven er tatt fra https://open.kattis.com/problems/awkwardparty.
Martin har invitert alle han kjenner til å feire bursdagen hans, og hele \(n\) folk fra hele verden har takket ja til invitasjonen.
Martins mor Margrethe har bestemt seg for at alle gjestene skal sitte med maksimal klossethet; dette er for å sikre at ingen har noe meningsfullt å diskutere under middagen, og at alle i stillhet vil nyte den ganske smakfulle koriandersuppen hennes.
Margrethe vet at klossheten maksimeres hvis gjestene sitter på en lang rekke langs et enkelt bord, på en slik måte at ingen sitter ved siden av noen som snakker samme språk som dem selv. Enda bedre, hun har definert klosshetsnivået til en sittearrangement til å være minimum antall seter som skiller to gjester som snakker samme språk. Hvis ikke to personer snakker samme språk, er klosshetsnivået definert til å være \(n\) (antall gjester). To seter ved siden av hverandre sies å være adskilt med 1.
I filen awkward_party.py skriv en funksjon awkwardness_level(seating) som tar inn en filsti seating som input parameter. Filen seating skal bestå av to linjer. Den første linjen inneholder et heltall \(n\) som angir antall gjester. På den andre linjen følger \(n\) heltall separert med mellomrom, hvorav det \(i\)-te indikerer språket som snakkes av gjesten som sitter på posisjon \(i\) i den foreslåtte ordningen (hver gjest snakker nøyaktig ett språk).
Funksjonen skal returnere ett enkelt heltall, klosshetsnivået til det foreslåtte sittearrangementet.
Kjør koden din på filene seating1.txt og seating2.txt.
Test koden din ved å legge til disse linjene nederst i filen:
print("Tester awkwardness_level... ", end="")
assert(awkwardness_level("seating1.txt") == 3)
assert(awkwardness_level("seating2.txt") == 3)
print("OK")
Bruk et oppslagsverk
Prikkprodukt
I filen dot_product.py skriv funksjonen dot_product(a, b) som regner ut prikkprodukuktet for to like lange lister med tall a og b. Prikkproduktet er definert som summen av produktene av verdiene som har lik posisjon i de to listene; altså (a[0] * b[0] + a[1] * b[1] + …)
def test_dot_product():
print('Tester dot_product... ', end='')
assert 36 == dot_product([1, 2, 3, 4], [4, 5, 6, 1])
assert 12 == dot_product([0, 6, 1], [400, 1, 6])
assert 651 == dot_product([43, 6], [15, 1])
print('OK')
if __name__ == '__main__':
test_dot_product()
Lengste varmeperiode (dummydata)
I denne oppgaven skal du skrive en funksjon som finner den lengste sammenhengende perioden med temperaturer over ett gitt antall varmegrader.
I filen longest_hot_period_dummy.py, skriv en funksjon longest_hot_period(temperatures, threshold) som tar inn en liste temperatures med temperaturer og et flyttall threshold som representerer hvor mange grader som definerer en varm dag. Funksjonen skal returnere indeksene som definerer den lengste sammenhengende perioden med temperaturer med threshold eller flere varmegrader. Hvis det er flere perioder som er like lange, skal den returnere den tidligste perioden.
Hvis det ikke er noen perioder med temperaturer over threshold, skal funksjonen returnere (-1, -1). Se også eksemplene i testene du kan lime inn nederst i filen for å se hvordan funksjonen skal fungere.
Følg konvensjon for start og sluttindekser i Python (start, end):
starter den første indeksen i perioden, inklusiv. Det betyr at den peker på den første verdien i perioden.ender den siste indeksen i perioden, eksklusiv. Det betyr at den peker på den første verdien etter perioden. Om det er den siste verdien i listen, så erendlik lengden på listen.
def test_longest_hot_period():
print('Testing longest_hot_period... ', end='')
temps = [25, 23, 19, 22, 24, 25, 21, 25, 26]
threshold = 22
expected_start, expected_end = 3, 6
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 23
expected_start, expected_end = 0, 2
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 15
expected_start, expected_end = 0, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 21
expected_start, expected_end = 3, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 25
expected_start, expected_end = 7, 9
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
threshold = 30
expected_start, expected_end = -1, -1
actual_start, actual_end = longest_hot_period(temps, threshold)
assert (expected_start, expected_end) == (actual_start, actual_end)
print('OK')
if __name__ == '__main__':
test_longest_hot_period()
Lengste varmeperiode (ekte data)
I denne oppgaven skal du skrive en funksjon som finner den lengste sammenhengende perioden der hver dag har temperaturer over ett gitt antall varmegrader. Denne gangen skal vi bruke ekte data hentet fra frost.met.no.
- Å hente data fra frost.met.no er gratis, men for å hindre misbruk må du registrere deg. Registrering er en uvanlig kortfattet prosess som du kan gjøre her: https://frost.met.no/auth/requestCredentials.html. For å gjennomføre denne oppgaven må du ta vare på din client_id; for enkelhets skyld kan du kopiere denne inn i en fil som heter client_id.txt. I kodeeksemplene under antar vi at din client id er det eneste som ligger lagret i denne filen.
Full dokumentasjon for hva slags data du kan hente fra frost.met.no kan være litt overveldende; vi presenterer derfor noen relevante eksempler vi kan begynne å utforske her.
import requests
import json
from pathlib import Path
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
api_endpoint = 'https://frost.met.no/observations/v0.jsonld'
source_id = 'SN50540' # SN50540 er Florida målestasjon i Bergen
response = requests.get(
api_endpoint,
params={
'sources': source_id,
'referencetime': '2024-04-01/2024-04-07',
'elements': 'mean(air_temperature P1D)',
'levels': 'default',
'timeoffsets': 'default',
},
headers={'User-Agent': 'inf100.ii.uib.no student'},
auth=(client_id, '')
)
json_data = response.json()
print(json.dumps(json_data, indent=2))
Tips for å utforske dataene du mottar: sett et breakpoint like etter at
json_datahar blitt opprettet, og bruk debuggeren for å utforske hva som ligger i denne variabelen.
- client_id er en variabel som peker på en streng, nemlig din client id.
- api_endpoint er en variabel som peker på en streng, nemlig adressen til frost.met.no hvor vi kan hente data.
- source_id er en variabel som peker på en streng, i dette tilfellet representerer strengen id-en til Florida målestasjon i Bergen.
- response er en variabel som peker på responsen vi får fra frost.met.no når vi spør om data.
Argumentene vi gir ved kallet til requests.get er
- api_endpoint er stammen for nettadressen hvor vi henter data. Dette utgjør begynnelsen av en URL/nettadresse.
- til params gir vi et oppslagsverk med nøkkel-verdi-par som vil utgjøre slutten av url’en. Den komplette URL’en vil til slutt bli
https://frost.met.no/observations/v0.jsonld?sources=SN50540&referencetime=2024-04-01/2024-04-07&elements=mean(air_temperature%20P1D)&levels=default&timeoffsets=default. Vi kunne laget denne strengen på andre måter og ikke benyttet params-parameteren i det hele tatt; men det ser mer oversiktelig og fint ut å bruke params og et oppslagsverk enn å bedrive omfattende streng-manipulasjon på egen hånd.- sources er en komma-separert liste over målestasjoner vi ønsker data fra. I vårt tilfelle er det kun én målestasjon.
- referencetime tidsrommet vi ønsker måledata fra.
<fra dato>/<til dato>. Merk at fra-dato er inklusiv mens til-dato er ekslusiv (i tråd med god standard praksis i programmering for øvrig). - elements angir hva slags måledata vi ønsker. Strengen
mean(air_temperature P1D)innebærer at vi ønsker oss gjennomsnittstemperaturen for tidsperioder på én dag. - levels angir hvilket «nivå» målingen er gjort på. For temperaturdata er standardnivået 2 meter over bakken, mens noen målestasjoner har temperaturmålinger også på andre høyder. Ved å angi
defaulther eksluderer vi data fra andre målehøyder enn standardnivået. - timeoffsets angir hvilket tidspunkt på døgnet gjennomsnittsmålingen begynner. Default som verdi her betyr at gjennomsnittsmålingen begynner ved midnatt.
- til headers gir vi et oppslagsverk hvor vi angir en verdi for «User-Agent». Dette feltet benyttes for å beskrive hva slags software som brukes.
- til auth gir vi en tuple med (brukernavn, passord). I vårt tilfelle er ikke passord nødvendig, siden frost.met.no ikke krever dette når vi bare ber om å lese informasjon. Derfor oppgir vi en tom streng som passord.
requests har innebygget en metode for å konvertere en respons som kommer i json-format til et oppslagsverk/json-objekt. Dette gjøres ved å kalle response.json(). Vi bruker json.dumps for å skrive ut dette oppslagsverket på en lesbar måte.
Et lite program for å finne id’ene til værstasjoner i Bergen. Vi laster først ned en oversikt over alle værstasjoner i Norge, og søker etter dem som har Bergen i navnet.
import requests
from pathlib import Path
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
api_endpoint = 'https://frost.met.no/sources/v0.jsonld'
response = requests.get(
api_endpoint,
headers={'User-Agent': 'inf100.ii.uib.no student'},
auth=(client_id, '')
)
json_data = response.json()
for item in json_data['data']:
if 'name' not in item:
continue
if 'bergen' in item['name'].lower():
print(item['id'], item['name'])
I filen longest_hot_period_realdata.py skriv en funksjon longest_hot_period(client_id, source_id, start_date, end_date, threshold) som tar inn en client id, en stasjonsid, en start-dato, en slutt-dato og en temperaturgrense, og som så returnerer den lengste sammenhengende perioden i den angitte perioden med temperaturer over threshold. Hvis det ikke er noen perioder med temperaturer over threshold, skal funksjonen returnere (None, None). Dersom det er flere periode med samme varighet, skal den siste av dem returneres.
Følg konvensjon for start og sluttindekser i Python (start, end):
starter den første indeksen i perioden, inklusiv. Det betyr at den peker på den første verdien i perioden.ender den siste indeksen i perioden, eksklusiv. Det betyr at den peker på den første verdien etter perioden. Om det er den siste verdien i listen, så erendlik lengden på listen.
For å teste funksjonen, kan du legge til denne koden nederst i filen:
from pathlib import Path
from datetime import datetime
def longest_hot_period(client_id, source_id, start_date, end_date, threshold):
... # din kode her
def test_longest_hot_period():
client_id = Path('client_id.txt').read_text(encoding='utf-8').strip()
start_date = datetime(year=2000, month=1, day=1)
end_date = datetime(year=2024, month=1, day=1)
threshold = 20
source_id = 'SN50540' # Florida målestasjon i Bergen
actual_start, actual_end = longest_hot_period(
client_id, source_id, start_date, end_date, threshold
)
actual_start = actual_start.replace(tzinfo=None) # Fjerner tidssone
actual_end = actual_end.replace(tzinfo=None) # Fjerner tidssone
expected_start = datetime(year=2009, month=6, day=25)
expected_end = datetime(year=2009, month=7, day=5)
assert actual_start == expected_start
assert actual_end == expected_end
if __name__ == '__main__':
test_longest_hot_period()
Penguins
Today, we’re going to analyse a dataframe about penguins using the Python libraries pandas and altair. You can load the data in 2 ways:
- directly loading the file (penguins.csv) ,
- or by url from github - in that case, make sure to click
Rawbutton on the top right corner before copying the url (so it would start ashttps://raw.githubusercontent.com/...)

Del 1: Load the data
Task. Write a function load_clean_data() that takes either path to the file or url as an argument and returns pandas dataframe with some preceeding procedures:
- it should drop observations that contain NaN values
- it should print a concise summary (or info) of a dataframe
Del 2: Summary statistics
Now our task is to learn how to distinguish one penguin from another. For this purpose, we will calculate some summary statistics, like mean values. Note: when working with averages values, it is super important to keep in mind how many observations we have aggregated.
Task. Your task is to write a function calculate_means(), which asks for a dataframe and returns aggregated data. You will need to:
- Calculate amount of species of each sex
- Derive a dataframe with mean measurements for bills and flipper for each sex of each species
- Add (1) as a new column
'count'to (2)
Therefore, return data should look like this:
| bill_length_mm | bill_depth_mm | flipper_length_mm | count | ||
|---|---|---|---|---|---|
| species | sex | float | float | float | int |
| Adelie | FEMALE | float | float | float | int |
| MALE | float | float | float | int | |
| Chinstrap | FEMALE | float | float | float | int |
| MALE | float | float | float | int | |
| Gentoo | FEMALE | float | float | float | int |
| MALE | float | float | float | int |
Del 3. Correlations
Task. Write a function pairwise_corr() that takes the original data and returns pairwise correlation of columns dataframe. You can find how to do this in the lecture notes.
Bonus task: If you want to practice more (without grading), update previous functions so it returns the top N highest correlations. Example input and output should be something like:
top_corr(data, top_n = 3)
| Variable 1 | Variable 2 | Correlation |
|---|---|---|
| flipper_length_mm | body_mass_g | float |
| flipper_length_mm | bill_length_mm | float |
| flipper_length_mm | bill_depth_mm | float |
Del 4. Visualizing the numbers
Summary statistics help us uncover patterns and trends in our dataset; at the same time, they hide the rich details that were once in the data. This is where visualizations can come to the rescue! In the next two tasks, you will generate charts that visually represent the statistics from Del 2 and Del 3.
Task. Your task is to visualize the distribution of a physical feature (e.g., flipper length) across all penguins in the dataset. You will write a function draw_bar() that:
- takes a dataframe, x-value (string), and color (string) as its inputs
- draws a Chart() object using those values. It should draw a histogram, which uses bars as marks and bins x-values.
- returns this chart as its output
If you are working in a python (.py) file, you will need to render the chart as an HTML file and look at it in a web browser. You can do this using save(), like this: draw_bar(...).save('yourfilename.html').
If you are working in a notebook (.ipynb) file, you can call the function and the chart will display under the code block.
Here is what your output could look like:

Del 5. Visual correlation
In the previous task, we visualized the distribution of a penguin’s physical feature across all three species. Now, we will look at how these physical features are correlated across all three species. This time, we will distinguish between the species using color.
Task. Your task is to visualize the correlations of physical features (e.g., flipper length and bill length) across all penguins in the dataset. You will write a function draw_corr() that:
- takes a dataframe and physical features (list of strings) as its inputs
- draws a Chart() object using those inputs. It should draw multiple scatterplot charts that use circles as marks. The circles are color coded by species.
- returns a set of charts as its output
If you are working in a python (.py) file, you will need to render the chart as an HTML file and look at it in a web browser. You can do this using save(), like this: draw_corr(...).save('yourfilename.html').
If you are working in a notebook (.ipynb) file, you can call the function and the chart will display under the code block.
Bonus task: If you want to practice more (without grading), add the ability to specify a chart title, x-axis label, and y-axis label! Or, make the output an interactive chart (hint: this can be done by chaining just one method to the chart object)
Here is what your output could look like:

Deliverables
For this lab, please submit three files:
- penguins.py containing all the functions you have written. Please use the libraries
pandasandaltairfor your solutions to this lab. - HTML file of your chart output from Del 4
- HTML file of your chart output from Del 5
Akvakulturregisteret
I denne oppgaven skal vi bruke datafilen Akvakulturregisteret.csv.
PS: akvakulturregisteret er dessverre ikke lagret i utf-8. Prøv deg frem til du finner riktig encoding (se notater om tekstkoding).
Del A
I filen aquaculture_a.py skriv en funksjon count_facilities_by_species(path) som tar som input en filsti til akvakulturregisteret, og som så skriver ut til terminalen en unicode-alfabetisk liste over antall oppdrettsanlegg for hver art. Med «unicode-alfabetisk» menes den rekkefølgen man får dersom man sorterer en liste med artsnavn med sorted -funksjonen innebygget i Python. Du kan ta utgangspunkt i følgende kode:
def count_facilities_by_species(path):
... # din kode her
if __name__ == '__main__':
count_facilities_by_species('Akvakulturregisteret.csv')
Eksempel på utskrift når programmet kjøres:
Abbor: 8
Acartia tonsa **(oppdrett): 4
Akkar: 1
Amerikansk hummer: 2
Arctic sea ice amphipod *: 1
Arktisk knurrulke: 1
Berggylt: 58
...
Les innholdet i filen til en egnet datastruktur ved å benytte csv -biblioteket.
Bruk et oppslagsverk (dict) for å telle hver art; bruk en løkke over hver rad i filen.
Første gangen du ser en art, opprett en ny nøkkel med artsnavnet i oppslagsverket og gi den verdien 1
Dersom nøkkelen derimot var i oppslagsverket fra før, øk verdien dens med 1
For å finne artene i ‘alfabetisk’ rekkefølge, bruk
sorted-funksjonen og gi listen med nøklene fra oppslagsverket som argument.
Del B
I filen aquaculture_bc.py, skriv et program som plotter alle oppdrettsanleggene i akvakulturregisteret på et kart. Bruk et scatterplot fra matplotlib for å plotte punktene. Posisjonene til oppdrettsanleggene er gitt i kolonnene som kalles Ø_GEOWGS84 og N_GEOWGS84 i csv-filen. Det er fint om punktene tegnes med en viss gjennomsiktighet.
Når du kjører programmet skal omtrent følgende vises:
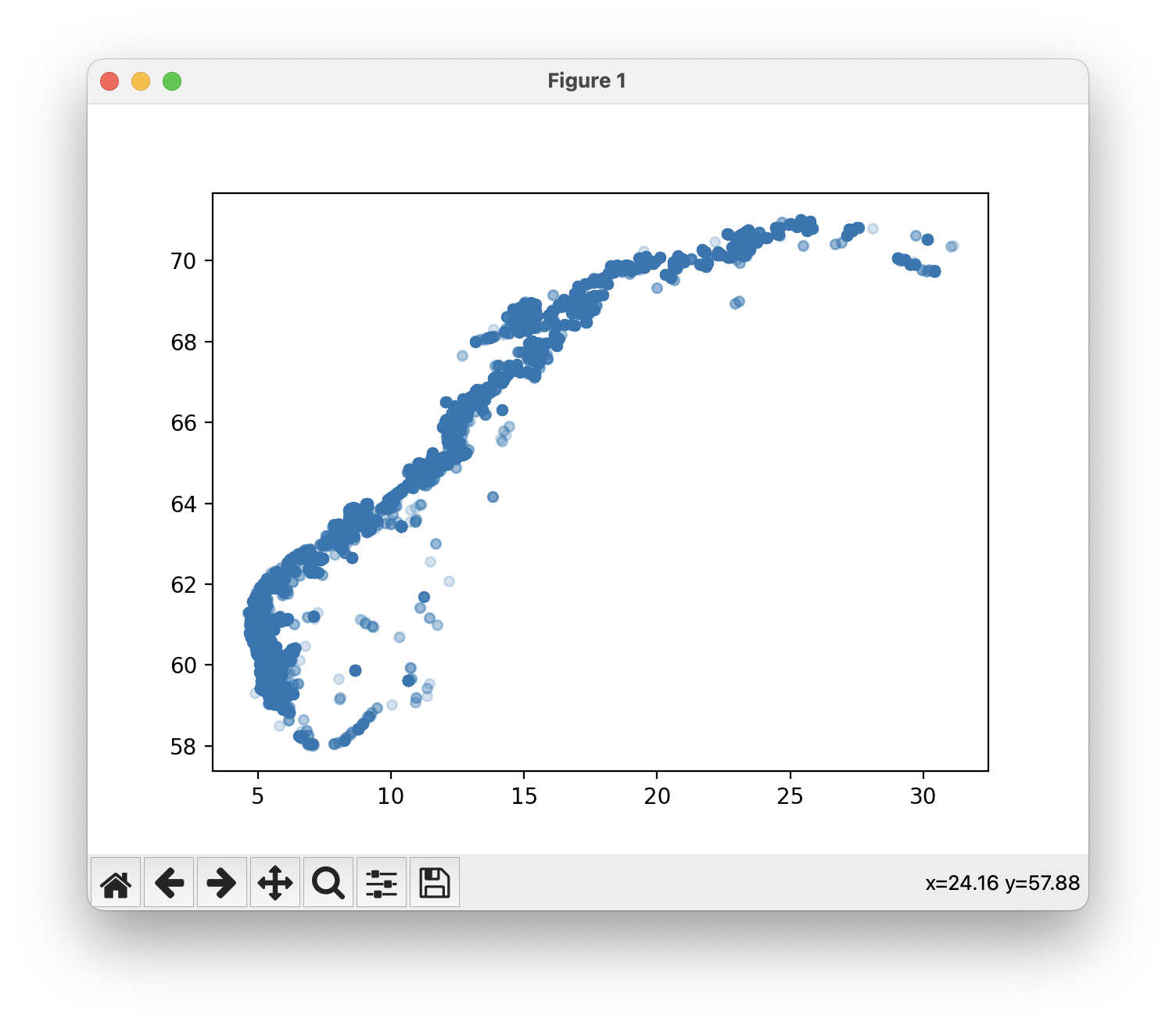
Del C
I filen aquaculture_bc.py, endre programmet slik at punktene får ulik farge avhengig av om det er et oppdrettsanlegg i sjø eller på land.
Når du kjører programmet skal omtrent følgende vises:
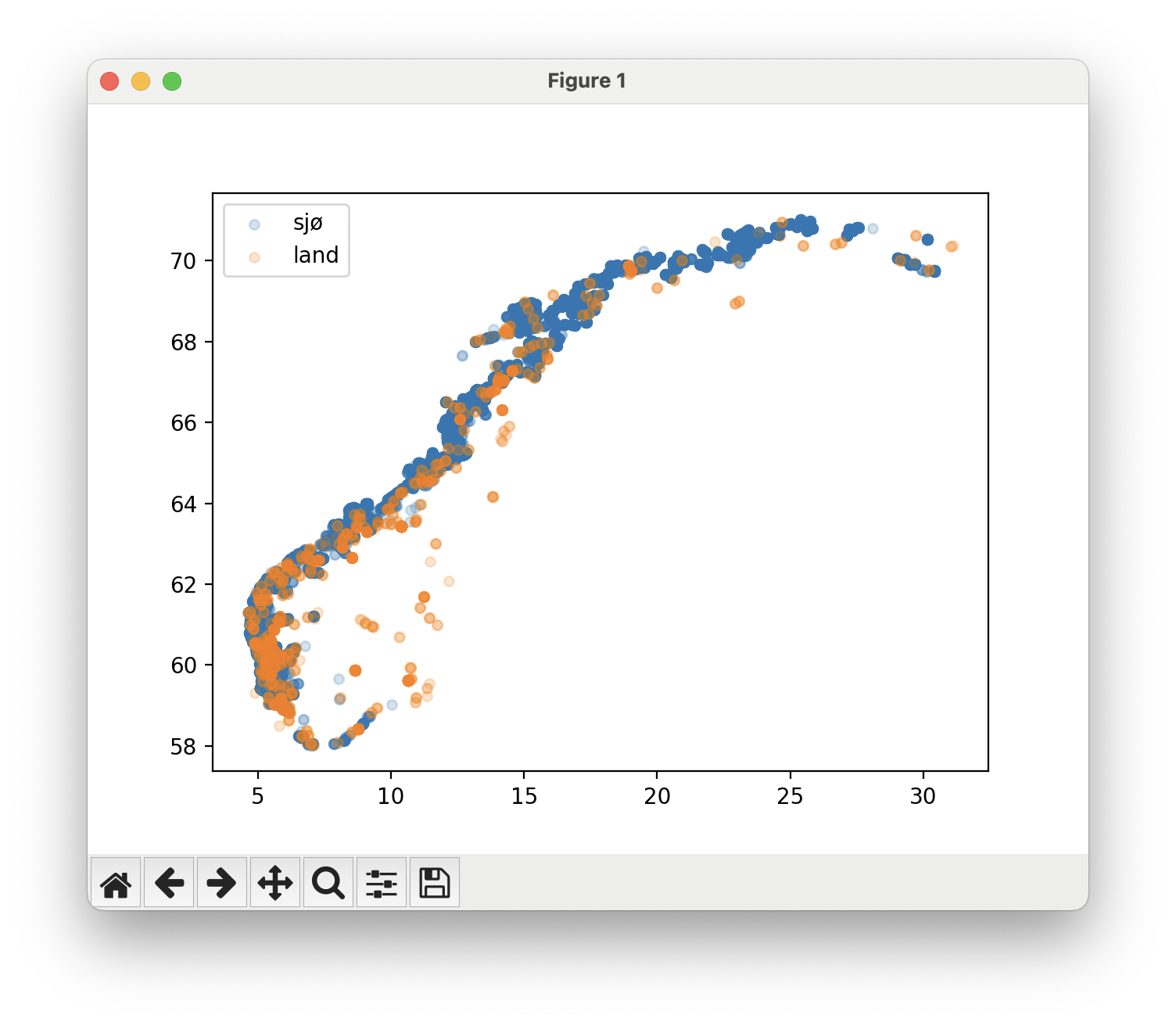
Jordskjelv
Du har blitt ansatt av et geologisk firma som skal finne ut de minst trygge stedene i verden å bygge boliger. Oppgaven din er å identifisere steder som har hatt store jordskjelv den siste tiden, slik at informasjonen kan selges til ulike boliginvesteringsfirmaer for at de ikke skal bygge boliger der.
I denne oppgaven skal vi kombinere bruken av minst fem moduler. Tre fra standardbiblioteket (datetime, csv, og json) og to eksterne moduler (requests og matplotlib).
Vi skal i denne oppgaven bruke requests til å laste ned data fra en nettside, og så konvertere dataen til en liste av oppslagsverk med csv-biblioteket. Deretter skal vi plotte den med pyplot fra matplotlib. Så skal vi kombinere dette med data fra en annen fil, og plotte begge deler sammen.
Skriv programmet ditt i filen earthquakes.py.
Del A: last ned data om nylige jordskjelv med requests og datetime
Nettsiden til U.S. Geological Survey har åpent tilgjengelig og oppdaterte jordskjelvdata for hele verden. Ta for eksempel denne URL’en: https://earthquake.usgs.gov/fdsnws/event/1/query?format=csv&starttime=2024-03-11T17%3A14%3A55%2B0000&endtime=2024-03-21T17%3A14%3A55%2B0000&minmagnitude=5.8&orderby=magnitude&limit=5000
Om du får spørsmål om å lagre en fil når du trykker på linken over, bør du lagre den som en .csv-fil; for det er nemlig det du får. Om du åpner filen i en teksteditor (f. eks. VSCode) vil du se at den inneholder jordskjelvdata på .csv -format:
time,latitude,longitude,depth,mag,magType,nst,gap,dmin,rms,net,id,updated,place,type,horizontalError,depthError,magError,magNst,status,locationSource,magSource
2024-03-14T21:10:24.786Z,29.7971,-42.6608,10,6.2,mww,189,54,16.297,0.59,us,us6000miy6,2024-05-18T21:22:58.040Z,"northern Mid-Atlantic Ridge",earthquake,9.43,1.776,0.037,71,reviewed,us,us
2024-03-13T15:13:22.779Z,-5.831,150.6843,44,6,mww,142,29,4.981,0.96,us,us6000milg,2024-05-18T21:22:41.040Z,"68 km ESE of Kimbe, Papua New Guinea",earthquake,8.19,1.917,0.041,56,reviewed,us,us
2024-03-16T00:14:51.989Z,-58.935,158.3538,10,5.9,mww,57,52,4.46,0.5,us,us6000mj77,2024-05-18T21:23:15.040Z,"Macquarie Island region",earthquake,11.01,1.827,0.06,27,reviewed,us,us
Vi fikk altså en liste med tre jordskjelv. Men hvilke jordskjelv er det egentlig vi får? For å undersøke det, kan vi undersøke URL’en vi brukte for å laste ned dataen. Vi kan dele opp URL’en i flere deler:
https://earthquake.usgs.gov/fdsnws/event/1/queryer basen for URL’en. Dette kaller vi for et «API-endepunkt».?betyr at resten av URL’en angir «query parametere» og tilhørende argumenter. Symbolet&brukes for å skille mellom ulike parametere.format=csvspesifiserer at vi ønsker dataen i .csv-format.starttime=2024-03-11T17%3A14%3A55%2B0000spesifiserer at vi ønsker jordskjelv som finner sted fra og med 11. mars 2024 kl. 17:14:55 UTC. Dette er en måte å skrive tidspunkt på som kalles ISO 8601, men hvor noen symboler har blitt kodet slik at de tryggere kan brukes i en URL (%3Aer en kode for symbolet:og%2Ber en kode for symbolet+, så egentlig kan du tolke denne delen somstarttime=2024-03-11T17:14:55+0000).endtime=2024-03-21T17%3A14%3A55%2B0000spesifiserer at vi ønsker jordskjelv som finner sted til og med til 21. mars 2024 kl. 17:14:55 UTC. Strengen kan tolkes somendtime=2024-03-21T17:14:55+0000minmagnitude=5.8er en parameter som spesifiserer at vi ønsker jordskjelv med en styrke på 5.8 eller mer på Richters skala.orderby=magnitudeer en parameter som spesifiserer at vi ønsker jordskjelv sortert etter styrke.limit=5000er en parameter som spesifiserer at vi ønsker maksimalt 5000 jordskjelv.
Det var altså fire jordskjelv som skjedde mellom 11. mars og 21. mars 2024 med en styrke på 5.8 eller høyere, og det er dem vi har fått informasjon om i .csv-filen som vi lastet ned.
For å laste ned data fra internett til et Python-program, bruker vi biblioteket requests.
- Installer
requests(men du har sannsynligvis allerede installert det, siden det installeres automatisk sammen med uib-inf100-graphics) - Sjekk at du klarer å laste ned dataen fra URL’en over og skrive den ut i konsollen. Du kan bruke programmet under (men husk å bytte til ditt eget uib-brukernavn):
# Rask sjekk for at vi har klart å installere requests -biblioteket
import requests
url = 'https://earthquake.usgs.gov/fdsnws/event/1/query?format=csv&starttime=2024-03-11T17%3A14%3A55%2B0000&endtime=2024-03-21T17%3A14%3A55%2B0000&minmagnitude=5.8&orderby=magnitude&limit=5000'
headers = {'User-Agent': 'no.uib.ii.inf100.h24.lab7.mitt_uib_brukernavn'}
response = requests.get(url, headers=headers)
content = response.content.decode('utf-8')
print(content)
# Sjekk at du ser csv-dataen fra over i terminalen
Når du har fått dette til, er det på tide å gjøre det litt mer dynamisk; for eksempel ønsker vi å kunne hente ut jordskjelvdata basert på datoen når programmet kjøres. Umiddelbart ser det ut som vi må gjøre en seriøs streng-manipulasjon for å konstruere URL’en vi trenger; men heldigvis har requests-modulen gjort det enkelt å generere URL’er med parametere. For eksempel vil koden under gi nøyaktig samme resultat som koden over. Sjekk at du også får samme resultat! (PS: husk å endre mit_uib_brukernavn til ditt brukernavn eller bruk egentlig en hvilken som helst streng som kan identfisiere at programmet er akkurat ditt program)
import requests
baseurl = 'https://earthquake.usgs.gov/fdsnws/event/1/query'
headers = {'User-Agent': 'no.uib.ii.inf100.h24.lab7.mitt_uib_brukernavn'}
params = {
'format': 'csv',
'starttime': '2024-03-11T17:14:55+0000', # ISO 8601 format
'endtime': '2024-03-21T17:14:55+0000', # ISO 8601 format
'minmagnitude': 5.8,
'orderby': 'magnitude',
'limit': 5000,
}
response = requests.get(baseurl, params=params, headers=headers)
content = response.content.decode('utf-8')
print(content)
Nå virker det forhåpentligvis litt mer overkommelig å generere URL’er slik vi selv ønsker. Det gjenstår bare å kunne lage en ISO 8601-formatert streng for tidspunktet vi ønsker å hente ut jordskjelvdata for. Til dette formålet bruker vi datetime-modulen.
- Importer datetime, timezone og timedelta fra den innebygde datetime-modulen.
- Opprett et datetime-objekt for sluttidspunktet med tidspunktet «nå» i UTC tid (
end_time = datetime.now(timezone.utc)). - Opprett et datetime-objekt for starttidspunktet med tidspunktet 365 dager før sluttidspunktet (
start_time = end_time - timedelta(days=365)). - Konverter begge tidspunkter til en ISO 8601-formatert streng:
my_iso8601_string = my_datetime_object.strftime('%Y-%m-%dT%H:%M:%S%z') - Bruk disse strengene i request’en din for å hente ut jordskjelvdata for det siste året.
Test at det fungerer. Helt til slutt skal vi flytte programmet vårt inn i en funksjon og gjøre det enda mer dynamisk:
- I filen earthquakes.py, skriv en funksjon
get_earthquakes_csv_stringmed to parametre:net antall dager ogmagnitudeet flyttall. Funksjonen skal returnere en CSV-formatert streng med informasjon hentet fra U.S. Geological Survey om alle jordskjelv som har skjedd de sistendagene som hadde en styrke påmagnitudeeller mer. Dersom det er flere enn 5000 slike jordskjelv, skal kun de 5000 sterkeste av dem inkluderes.
# earthquakes.py
import requests
from datetime import datetime, timezone, timedelta
def get_earthquakes_csv_string(n, magnitude):
# Din kode her
...
if __name__ == "__main__":
s = get_earthquakes_csv_string(30, 5.8)
print(s) # vi fjerner print senere, men vi ser nå at vi er på rett vei
Del B: hent ut relevante jordskjelvdata
Vi har så langt fått tak i jordskjelvene som en csv-formatert streng. Nå er tidspunktet for å konvertere fra en slik streng til en liste med oppslagsverk (eller en 2D-liste, om du foretrekker det). Vi kunne kanskje gjort det selv med split og lignende; men legg merke til at CSV-filen kan inneholde komma også i selve stedsnavnene. Da er det ikke så lett å splitte på komma som vi kanskje skulle ønske. Heldigvis har Python en innbygd modul for å lese CSV-filer som håndterer dette for oss: csv -modulen (det kan være spesielt aktuelt å lese avsnittet «DictReader med CSV-formatterte strenger»).
- Bruk csv-modulen for å konvertere csv-strengen til en liste med oppslagsverk. Strengen benytter komma (
,) som skilletegn («delimiter») og hermetegn (") som grupperingssymbol («quotechar»). Begge disse er standard, så det er egentlig ikke behov for å spesifisere dem i vårt tilfelle.
Det vi egentlig ønsker å hente ut fra datasettet er en liste med tupler (lengdegrad, breddegrad, styrke), slik at vi kan plotte punktene.
- I earthquakes.py, lag en funksjon
get_earthquake_listsom tar inn en csv-formatert strengcsv_stringog returnerer en liste med jordskjelv. Hvert jordskjelv skal være en tuple med breddegrad, lengdegrad og styrke som flyttall.
For å teste funksjonen kan du laste ned og kjøre test_get_earthquake_list.py. Hint: pass på at testene passerer før du fortsetter, hvis du gjør feil her kan du få merkelige feil senere.
Del C: plot jordskjelvdata
Nå som vi har fått tak i dataen vi ønsker, skal vi plotte den med pyplot fra det eksterne biblioteket matplotlib.
I earthquakes.py, lag en funksjon plot_earthquakes som tar inn en liste med koordinater data_points og plotter dem med plt.scatter som blå prikker. Merk at data_points er en liste med tupler (lengdegrad, breddegrad, magnitude), mens plt.scatter tar inn to lister xs og ys som henholdsvis inneholder x- og y-verdiene til punktene. Du kan bruke en for-løkke for å hente ut x- og y-verdiene fra data_points og legge dem i hver sin liste.
For å få et bedre inntrykk av hvor jordskjelvene har skjedd, ønsker vi å skalere størrelsen på prikkene etter magnituden på jordskjelvet. Dette kan gjøres ved å bruke parameteren s ved kallet til scatter-funksjonen. For å få en synlig størrelsesforskjell må vi skalere styrken eksponentielt med magnituden. Dette kan gjøres ved å lage en liste sizes som inneholder <(3 opphøyd i magnituden) / 10> for hvert jordskjelv, og gi denne listen som argument til s i scatter-funksjonen.
Vi kan også sette alpha=0.2 for å gjøre prikkene litt gjennomsiktige, slik at vi lettere kan se hvor det er flest jordskjelv.
For å teste at alt henger sammen, går vi til if __name__ == '__main__':-blokken som skal være på slutten av filen:
- her kaller du først get_earthquakes_string med styrke 4 og 50 dager som argument,
- deretter kaller du parse_earthquakes med resultatet av get_earthquakes_string som argument, og
- så gir du det resultatet til plot_earthquakes. Så kaller du
plt.show()for å vise plottet.
Når du er ferdig skal programmet produsere noe som ser noenlunde slik ut (dette ble kjørt 16. oktober 2024):

Men dette er jo bare en haug med prikker? Ja, det er jo allerede litt kult, og om vi legger godviljen til kan vi skimte konturene av noen kontinenter og land. Vi ønsker likevel å gi prikkene litt mer mening og kontekst, og dette skal vi gjøre videre.
I funksjonen plot_earthquakes:
- Gå gjennom
data_pointsog hent ut x-verdi, y-verdi og magnitude for hvert punkt. Legg disse verdiene i hver sin liste (opprette som tomme lister før løkken begynner), slik at du til slutt ender opp med en liste med x-verdier, en liste med y-verdier, og en liste med størrelser. Pass på at størrelsene blir skalert eksponentielt med magnitude (size = 3**mag / 10). - Gi disse verdiene som argumenter til
scatter. Pass på at du må brukes=for å sette listen av styrker inn som størrelser på prikkene. - Sett
alpha=0.2.
Husk at dersom plottet ser feil ut kan det være feil fra Del B eller Del C. Pass på at du gir xs og ys til plt.scatter i riktig rekkefølge, og at du har hentet ut koordinatene riktig i Del B. Husk: breddegrad (latitude) er som en y-verdi og sier noe om vertikal plassering, mens lengdegrad (longitude) er som en x-verdi og sier noe om horisontal plassering.
Del D: last inn kystlinjer
Ditt neste oppdrag vil være å finne fram et datasett av verdens kystlinjer, og så hente ut dataen vi har behov for slik vi gjorde for jordskjelvene. Først går du til Martyn Afford sitt prosjekt natural-earth-geojson, og laster ned ne_110m_coastline.json fra mappen /110m/physical. Du må klikke på «download raw file» oppe til høyre når du får opp kartet.

Det du har lastet ned nå, er en tekst-fil som inneholder koordinater for hele verdens kystlinjer. Dette er en JSON-fil, som er en måte å lagre data på som er veldig likt Python sine oppslagsverk. En forenklet versjon av filen ser slik ut, hvis vi legger til litt ekstra mellomrom og linjeskift for å gjøre det lettere å lese:
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"scalerank": 1,
"featurecla": "Coastline",
"min_zooom": 1.0
},
"geometry": {
"type": "LineString",
"coordinates": [
[ -163.71289567772871, -78.595667413241543 ],
[ -159.482404548154477, -79.046337579258974 ],
[ -163.027407803377002, -78.928773695794959 ]
]
}
},
{
"type": "Feature",
"properties": {
"scalerank": 0,
"featurecla": "Coastline",
"min_zooom": 0.0
},
"geometry": {
"type": "LineString",
"coordinates": [
[ -6.197884894220991, 53.867565009163364 ],
[ -9.977085740590269, 51.820454820353078 ],
[ -7.572167934591064, 55.131622219454869 ]
]
}
}
]
}
Om vi tolker data’en som om det var Python-kode, ser vi at den er organisert som et stort oppslagsverk som inneholder lister og andre oppslagsverk. Det er en nøkkel "features" hvor tilhørende verdi er en liste; hvert element i denne listen er én øy (eller verdensdel). Hver slik øy er igjen representert som et oppslagsverk, og har en nøkkel "geometry" hvor verdien igjen er et oppslagsverk som inneholder en nøkkel "coordinates" som inneholder en liste med koordinater. Dette er en liste med punkter som danner en kystlinje.
Anta at
dataer en variabel som inneholder oppslagsverket vist over. Da kan vi hente ut de første koordinatene til den første øyen slik:>>> data['features'][0]['geometry']['coordinates'][0] [-163.71289567772871, -78.595667413241543]Vi kan tolke oppslaget som at vi først åpner «features», så velger vi det første øyen i listen, så åpner vi «geometry» for nevnte øy, så «coordinates», og så henter vi ut det første punktet i listen.
json-modulen fra standardbiblioteket kan brukes for å konvertere en json-streng til et oppslagsverk.
I en funksjon load_coastlines, skal du
- lese inn dataen fra ne_110m_coastline.json som en streng, og
- bruke json-modulen fra standardbiblioteket for å konvertere strengen til et oppslagsverk, og
- returnere en liste med alle øyer. Hver øy skal være representert kun som en liste med koordinater.
Hvis den forenklede JSON-filen over var hele filen, ville altså funksjonen returnert en liste som så slik ut:
[
[ # Første øy
[ -163.71289567772871, -78.595667413241543 ],
[ -159.482404548154477, -79.046337579258974 ],
[ -163.027407803377002, -78.928773695794959 ]
],
[ # Andre øy
[ -6.197884894220991, 53.867565009163364 ],
[ -9.977085740590269, 51.820454820353078 ],
[ -7.572167934591064, 55.131622219454869 ]
]
]
Test deg selv: test_load_coastlines.py
- Les filen og konverter den til et oppslagsverk med json.
- Opprett en tom liste
linessom du skal legge linjene (listene av koordinater) i. - Den øverste nøkkelen i oppslagsverket er
"features". Dette er en liste med kystlinjer. - Iterer over kystlinjene (bruk en for-løkke
for island in data['features']) og hent ut kystlinjene somisland['geometry']['coordinates']. Legg disse linjene til ilines.
Del E: plot kystlinjer
Nå som vi har hentet ut kystlinjene, skal vi plotte dem sammen med jordskjelvdataen. I earthquakes.py, lag en ny funksjon plot_coastlines som tar inn en liste med verdensdeler/øyer islands og plotter dem som linjer med pyplot sin plot-funksjon. Bruk en løkke over øyene for å plotte hver øy en etter en. For å få det til å se ut som eksempelet, må du huske å sette color='grey' som argument til plot-funksjonen. Fargen er ikke et krav, og du får en kul overraskelse om du fjerner color -argumentet.
For å teste funksjonen, kan du legge følgende til i if __name__ == '__main__' -blokken, før kallet til plt.show:
- Et kall til load_coastlines for å laste inn kystlinjene.
- Et kall til plot_coastlines med resultatet fra foregående kall som argument for å plotte kystlinjene.
Når du er ferdig skal programmet produsere noe som ser noenlunde slik ut (hvis du kommenterer bort kallet til plot_earthquakes):

I funksjonen plot_coastlines kan du iterere over lines og hente ut x- og y-verdier for hver linje på samme måte som vi gjorde i del C. Plot linjene med plt.plot for å lage et linjeplot. Bruk color='grey' for å få linjene grå, eller fjern argumentet for en kul overraskelse.
Husk at dersom plottet ser feil ut kan det være feil fra Del D eller Del E. Pass på at du gir xs og ys til plt.plot i riktig rekkefølge, og at du har hentet ut koordinatene riktig i Del D.
Del F: plot jordskjelvdata og kystlinjer sammen
Nå har vi laget alt vi trenger for å plotte jordskjelv og kystlinjer sammen. Vi skal gjøre dette i if __name__ == '__main__'-biten som vi har brukt så langt. Kommenter inn igjen plot_earthquakes-kallet. Før du har kalt på funksjonene som plotter kystlinjer og jordskjelv, bruk plt.figure(figsize=(12,8)) for å lage en ny figur med størrelse 12x8. Dette er for å få et bedre perspektiv på jordskjelvene i forhold til kystlinjene. Legg også til et rutenett. Husk at plt.show() skal kalles etter alt annet for å vise plottet.
Når programmet ditt produserer noe tilsvarende dette, så er du i mål!

- Opprett en ny figur med
plt.figureog størrelsefigsize=(10,6). - Bruk funksjonene fra del A/B og D til å hente ut jordskjelvdata og kystlinjer.
- Plot jordskjelvdata og kystlinjer ved å bruke funksjonene fra del B og D med dataen over.
- Sett tittel på plottet med
plt.title. - Legg til et rutenett med
plt.grid(True). - Kall
plt.show()for å vise plottet.
Endre farge på prikk med piltaster
I denne oppgaven skal vi bruke uib_inf100_graphics.event_app for å lage et program hvor brukeren kan forandre fargen på en prikk ved å trykke på piltastene. Denne oppgaven rettes manuelt (det er ingen automatiske tester på CodeGrade).
Les deg gjerne opp på farger i kursnotatene om grafikk før du setter i gang.
En farge er i RGB-systemet representert av tre tall som beskriver lysintensiteten til rødt, grønt og blått lys. Hvert tall er mellom 0 og 255. I programmet vi skal lage i denne oppgaven, skal du tegne en prikk midt på skjermen. Brukeren skal kunne trykke på tastaturet for å endre fargen på prikken
- trykker brukeren på pil opp, økes mengden rød,
- trykker brukeren på pil ned reduseres mengden rød,
- trykker brukeren på pil høyre økes mengden grønn,
- trykker brukeren på pil venstre reduserers mengden grønn,
- trykker brukeren på
aøkes mengden blå, - trykker brukeren på
zreduseres mengden blå.
Ingen farge-verdier skal kunne være mindre enn 0 eller høyere enn 255.
Det ferdige programmet skal skrives i filen colorful_dot.py og skal se omtrent slik ut:
def rgb_to_hex(r, g, b):
return f'#{r:02x}{g:02x}{b:02x}'
# Example usage
hex_string = rgb_to_hex(255, 0, 128)
print(hex_string) # Output: #ff0080
La modellen (app) består av fire variabler: r, g, b (tallverdier) og message (en streng). Initialiser dem i app_started.
La redraw all tegne teksten og en runding midt på skjermen. La fargen være bestemt av r, g og b fra app.
La key_pressed håndtere tastetrykk som beskrevet i oppgaveteksten. I videoen over endres verdien med 10 for hvert tastetrykk.
Bonus:
- Ha ulike modus som bestemmer hvor store steg du tar hver gang. Endre modus ved å trykke på space.
- Ha ulike prikker, der du kan klikke på hvilken prikk du nå skal endre fargen til. Vis hvilken prikk som er valgt f. eks. ved å la den ha outline.