
Lab7
I hovedfeltet i denne lab’en skal du generere dine egne QR-koder! Selv om stegene bygger på hverandre, kan de faktisk løses helt isolert fra hverandre, og de scores isolert fra hverandre på CodeGrade.
- Vi vil trekke poeng manuelt dersom vi oppdager at oppgaven åpenbart ikke er løst, eller man forsøker å trikse seg gjennom de automatiske testene.
- Hver lab kan leveres så mange ganger du vil; det er siste innlevering som teller. Du kan umiddelbart se resultatene på de automatiske testene og hvor mange poeng du har fått etter hver innlevering.
Hver lab utgjør 2.5% av den endelige karakteren din i emnet. Du må få til sammen 100 poeng eller mer på labene for at eksamenskarakteren skal telle med i den endelige karakteren.
Det er veldig viktig at du siterer alle kilder og eventuelle samarbeid.
Det er lurt å levere inn mange ganger underveis. Du får umiddelbart en automatisk tilbakemelding på oppgavene, og du kan prøve igjen hvis noe ikke virker.
Kolonnesum
I filen sum_of_column.py, skriv en funksjon sum_of_column(path, col) som returnerer summen av verdiene fra den oppgitte kolonnen i csv-filen med filsti path. Ikke inkluder verdier i summen som ikke er flyttall; hvis det ikke finnes noen tallverdier i oppgitt kolonne, skal funksjonen returnere 0. Kolonne 0 er den første kolonnen fra venstre i csv-filen. Du kan anta at csv-filen benytter komma (,) som skilletegn og dobbel rett apostrof (") som anførselstegn/grupperingssymbol («quotechar»).
Eksempelkjøringer med foo.csv, Statistikk_Tilsyn_ar.csv og airport-codes.csv
def test_sum_of_column():
print('Tester sum_of_column... ', end='')
assert(42.0 == sum_of_column('foo.csv', 0))
assert(95.0 == sum_of_column('foo.csv', 1))
assert(0.0 == sum_of_column('foo.csv', 2))
assert(76363.0 == sum_of_column('Statistikk_Tilsyn_ar.csv', 1))
assert(46007.0 == sum_of_column('Statistikk_Tilsyn_ar.csv', 2))
assert(5024518.0 == sum_of_column('airport-codes.csv', 3))
print('OK')
if __name__ == '__main__':
test_sum_of_column()
Introduksjon
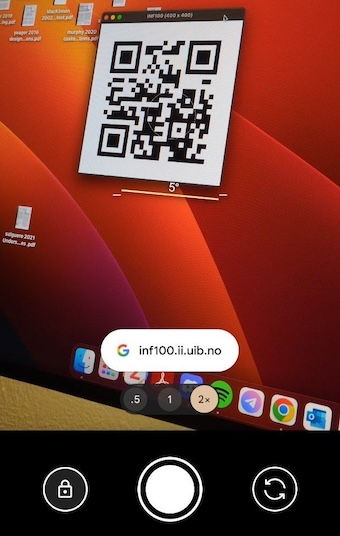
I denne oppgaven skal vi lære hvordan vi genererer en QR-kode! Når vi er helt ferdige skal programmet vårt fungere som følger:
- Input: en nettadresse, for eksempel strengen
'https://inf100.ii.uib.no' - Resultat: en QR-kode vises på skjermen. Om vi scanner QR-koden med mobilen kommer vi til nettadressen oppgitt som input.
Før du vi begynner, anbefaler vi sterkt at du ser igjennom denne videon som forklarer hvordan QR-koder fungerer (det er greit om du ikke klarer å følge med på de aller mest tekniske detaljene om Reed-Solomon -enkoding):
Prosessen med å lage en QR-kode går igjennom følgende steg:

Selv om prosessen begynner med å konvertere en streng til en liste med bits (1’ere og 0’ere), vil oppgavene i denne lab’en være organisert «baklengs», slik at vi begynner med å skrive funksjonen for å tegne QR-koden. Grunnen til dette er rett og slett at du får prøve at koden din fungerer etter hvert steg ved å scanne QR-kodene du produserer!
Kom i gang
Last ned disse filene til arbeidsmappen din:
| qr_dummies.py | Inneholder placeholder -varianter for funksjonene vi skal skrive, samt noen ekstra funksjoner som gir oss dummy-data for å hjelpe oss å sjekke underveis at vi er på riktig vei. Når vi er helt ferdige trenger vi ikke denne filen lengre. |
| qrv2_layout.json | Informasjon om layouten for en QR-kode i versjon 2. Denne informasjonen benytter vi flere steder. Hvis vi er flinke til å skrive koden vår basert på verdiene vi finner her, kan vi senere bytte ut denne filen med f. eks. qrv3_layout.json og umiddelbart være i stand til å generere QR-koder i versjon 3. |
Opprett også en fil qr0_main.py og lim inn følgende kode:
import json
from pathlib import Path
from qr1_draw import display
# from qr3_masking import get_refined_matrix
from qr_dummies import get_refined_matrix
# from qr4_zigzag import bit_list_to_raw_matrix
from qr_dummies import bit_list_to_raw_matrix
# from qr5_bit_list import string_to_bit_list
from qr_dummies import string_to_bit_list
def get_qr_matrix(content_string):
qr_layout = json.loads(Path('qrv2_layout.json').read_text(encoding='utf-8'))
bit_list, err_corr = string_to_bit_list(content_string, qr_layout)
raw_matrix = bit_list_to_raw_matrix(bit_list, qr_layout)
matrix = get_refined_matrix(raw_matrix, err_corr, qr_layout)
return matrix
if __name__ == '__main__':
url = 'https://inf100.ii.uib.no'
qr_matrix = get_qr_matrix(url)
display(qr_matrix)
Æsj, programmet krasjer allerede. Kan det være fordi vi ikke er ferdige med qr1_draw.py enda? Gjennomfør neste steg og finn ut!
1: Tegning
I denne oppgaven skal vi skrive et program som tegner en QR-kode til skjermen, gitt at vi får en matrise (2D-liste) med hvilke felter som skal være svarte og hvilke som skal være hvite i et rutenett. I denne deloppgaven skal vi opprette filen qr1_draw.py.
draw_qr
I filen qr1_draw.py skriven funksjon draw_qr med fem parametre:
canvas: et lerret QR-koden skal tegnes på;x_leftogy_top: koordinatene til hjørnet øverst til venstre;size: bredden og høyden til QR-koden som skal tegnes (tegningen skal være like høy som den er bred); ogqr: en kvadratisk 2D-dimensjonell liste som inneholder 1’ere og 0’ere. En 1’er betyr at ruten skal være svart, mens en 0’er betyr at ruten skal være hvit.
For å teste programmet ditt kan du legge til disse linjene nederst i filen qr1_draw.py. Når du kjører programmet, skal bildet under vises.
def display(matrix):
from uib_inf100_graphics.simple import canvas, display as dsp
canvas.create_rectangle(0, 0, 400, 400, fill='white', outline='')
draw_qr(canvas, 25, 25, 350, matrix)
dsp(canvas)
if __name__ == '__main__':
sample_grid = [
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1],
[0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1],
[0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
]
display(sample_grid)

Får du linjer mellom rutene? Det skal det ikke være. Angi
outline=''som et av argumentene når du kaller på create_rectangle.
Ta utgangspunkt i kode du har skrevet tidligere for Rutenett (lab4) eller Snake (lab5) og gjør noen små tilpasninger slik at funksjonen din for å tegne et rutenett passer med de nye parametrene.
-
Husk: både bredde og høyde er lik
size. -
Husk: høyresidens x-koordinat er lik venstresidens x-koordinat pluss bredde. Tilsvarende er bunnen lik topp pluss høyde.
Sjekk deg selv
Gå tilbake til qr0_main.py fra introduksjonssteget og kjør den nå. Om du har gjort alt riktig, skal det vises en QR-kode. Scan QR-koden med mobilen og se hvor du kommer… forhåpentligvis fant du en spennende nettside. Dessverre er det ikke riktig nettside, siden vi ikke ender opp på hovedsiden til https://inf100.ii.uib.no/ slik vi forventer ut i fra å lese koden i qr0_main.py. Det viser seg nemlig at get_refined_matrix-funksjonen som ligger i qr_dummies.py ikke bryr seg om argumentene den får, men alltid gir samme matrise tilbake uansett. Dette skal vi rette opp i løpet av de neste to stegene i oppgaven.
2: Faste mønstre og meta-felter
Det finnes mange ulike typer QR-koder. Den mest fremtredende forskjellen er kanskje dimensjonen til QR-koden, som avgjør hvor mange piksler det er i den. Jo større QR-kode, jo mer informasjon (f. eks. lengre nettadresser) kan den inneholde. I denne oppgaven skal vi for enkelhets skyld begrense oss til å kun jobbe med versjon 2 (QRv2), noe som innebærer at rutenettet vi skal lage er en matrise (2D-liste) med størrelse 25x25.
Matrisen for en QRv2 -kode er delt inn i følgende hovedkomponenter:
- En fast komponent som er lik for alle QRv2 -koder (markert i blått/lyseblått under). Disse feltene hjelper en QR-scanner å finne i hvilken del av bildet QR-koden befinner seg og hvordan den er vinklet og orientert. For oss som ikke er i businessen av å scanne QR-koder men istedet bare produsere dem, er ikke dette noe vi graver oss videre ned i utover at vi selvfølgelig må følge reglene og alltid lage koder som følger dette faste mønsteret.
- En datakomponent som inneholder selve data’en som er lagret (i svart/hvitt under). Dette datafeltet inneholder også underkomponenter for feilretting (error correction), men det kommer vi tilbake til senere.
- En komponent for metadata som sier noe om hvordan datafeltet er «maskert» og hvilket feilrettingsnivå koden benytter seg av i datafeltet (i rødt/rosa under).

I filen qrv2_layout.json (som du allerede har lastet ned til arbeidsmappen din, se introduksjon) finner du en datastruktur som forteller oss hvilke posisjoner i matrisen som hører til den faste komponenten og hvilke verdier de skal ha, samt hvilke posisjoner i matrisen som hører til metadata og hvilke verdier disse posisjonene kan ha ved ulike konfigurasjoner. Ta en kikk på filen den og prøv å forstå hvilken informasjon den inneholder.
En QRv2 -kode kan variere på følgende måter:
- Selve dataen som er lagret i QR-koden kan selvfølgelig variere. Ofte er dette en nettadresse, men det kan i prinsippet være hvilken som helst data. I denne oppgaven begrenser vi oss til å kun jobbe med strenger som data. Nettadresser er en form for streng, så vi vil kunne bruke programmet vårt til å lage QR-koder som fører oss til en nettside.
- Alle QR-koder har en viss kapasitet til å rette opp feil i avlesningen på egen hånd; men hvor stor andel av QR-koden som er feilaktig tolket før lesingen feiler kan variere. Du kan velge mellom fire nivåer av feilretting: L, M, Q og H. Disse ulike nivåene gjør at du kan hente ut korrekt informasjon selv om respektivt 7%, 15%, 25% eller 30% av matrisen blir feiltolket av programmet som leser bildet fra kameraet.
- Alle QR-koder har gått igjennom en prosess som heter «maskering», slik at bildet får en jevn fordeling av svarte og hvite piksler uavhengig av hvilken data bildet representerer. Prosessen innebærer å «flippe» enkelte ruter i matrisen etter et bestemt mønster. Det finnes 8 ulike mønstre man kan velge mellom, og ideelt sett velger vi mønsteret som gir den jevnest mulige fordeling av hvite og svarte ruter.
Når vi oppretter matrisen for QR-koden, gjøres det i fire hovedsteg:
| Råversjon | Maskering | Metadata | Faste komponenter |
 |
 |
 |
 |
Vi skal nå fokusere på de to siste stegene i denne helheten, nemlig fra vi har en ferdig maskert matrise til vi får en komplett QR-kode. Vi begynner med det siste steget først: å lime inn de faste komponentene. Deretter lager vi en funksjon for å lime inn feltene for metadata.
Begge oppgavene på denne siden skal skrives i filen qr2_matrix_completion.py.
set_fixed_fields
Opprett funksjonen set_fixed_fields som har to parametere
matrixen kvadratisk matrise (2D-liste), ogqr_layoutet oppslagsverk på samme format du ser i qrv2_layout.json.
Funksjonen skal (destruktivt) endre 2D-listen matrix slik at de faste feltene får riktig verdi i henhold til qr_layout.
def test_set_fixed_fields():
print('Testing set_fixed_fields...', end='')
matrix = [
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1],
]
sample_layout = {
'about': 'A fake and incomplete QR layout for testing only',
'side_length': 5,
'fixed_positions': {
'zeros': [
[3, 2], [3, 3], [3, 4], [4, 2], [4, 3], [4, 4]
],
'ones': [
[0, 0], [0, 1], [0, 2], [1, 0], [1, 1], [1, 2]
]
}
# skipping keys 'byte_capacity', 'meta_positions' and 'meta_patterns'
# since they are irrelevant here
}
set_fixed_fields(matrix, sample_layout)
assert matrix == [
[1, 1, 1, 0, 1],
[1, 1, 1, 1, 0],
[1, 0, 1, 0, 1],
[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
]
print(' OK')
Benytt en løkke over punktene i qr_layout['fixed_positions']['zeros']. Iteranden i en slik løkke blir [rad, kolonne] for et sted i matrisen som skal settes til 0. Tilsvarende for «ones».
set_meta_fields
Metadata-feltet varierer basert på to parametre:
- Feilrettingsnivå (L, M, Q eller H), og
- Maskenummer (angitt ved et tall mellom 0 og 7)
Opprett funksjonen set_meta_fields som har fire parametere:
matrixen kvadratisk matrise (2D-liste),err_corren streng på ett tegn som indikerer feilrettingsnivå (enten L, M, Q eller H),mask_noet tall 0-7 som angir hvilken maske som er benyttet, ogqr_layoutet oppslagsverk på samme format du ser i qrv2_layout.json.
Husk, vi skal ikke gjøre noe med feilrettingskoder eller maskering akkurat nå; vi kan anta at dette allerede er tatt hånd om. Vi skal bare gjøre informasjon om valgene som er gjort tilgjengelig i QR-kodens metafelter.
Funksjonen skal (destruktivt) endre 2D-listen matrix slik at metafeltene får riktig verdi i henhold til qr_layout. Merk at for å vite hvilket mønster som skal brukes, må du slå opp i «meta_patterns» i qr_layout i henhold til parametrene err_corr og mask_no; og for å vite posisjonene hvor dette mønsteret skal plasseres, må du slå opp i «meta_positions». Studer også testen for et forenklet eksempel.
def test_set_meta_fields():
print('Testing set_meta_fields...', end='')
# For easier visualization the test uses a matrix of strings rather
# than 0's and 1's, but ultimately 1's and 0's should also work
matrix = [
['-', '|', '-', '|', '-'],
['|', '-', '|', '-', '|'],
['-', '|', '-', '|', '-'],
['|', '-', '|', '-', '|'],
['-', '|', '-', '|', '-'],
]
sample_layout = {
'about': 'A fake and incomplete QR layout for testing only',
'side_length': 5,
# skipping key 'fixed_positions' since it is irrelevant here
'meta_positions': {
'first': [
[0, 0], [0, 1], [0, 2]
],
'second': [
[0, 4], [4, 4], [3, 1]
]
},
'meta_patterns': {
'L': [
['A', 'B', 'C'], # mask_no = 0
['a', 'b', 'c'] # mask_no = 1
],
'Q': [
['Q', 'R', 'S'], # mask_no = 0
['q', 'r', 's'] # mask_no = 1
],
}
}
err_corr = 'L'
mask_no = 0
set_meta_fields(matrix, err_corr, mask_no, sample_layout)
assert matrix == [
['A', 'B', 'C', '|', 'A'],
['|', '-', '|', '-', '|'],
['-', '|', '-', '|', '-'],
['|', 'C', '|', '-', '|'],
['-', '|', '-', '|', 'B'],
]
err_corr = 'Q'
mask_no = 1
set_meta_fields(matrix, err_corr, mask_no, sample_layout)
assert matrix == [
['q', 'r', 's', '|', 'q'],
['|', '-', '|', '-', '|'],
['-', '|', '-', '|', '-'],
['|', 's', '|', '-', '|'],
['-', '|', '-', '|', 'r'],
]
print(' OK')
Begynn med å finne hvilket bit-mønster du skal bruke (qr_layout['meta_patterns'][err_corr][mask_no]) og hvor det skal plasseres (qr_layout['meta_positions']['first'/'second']). Legg merke til at disse listene er like lange, og derfor har de samme indeksene. Bruk en løkke over indeksene (for ... in range(len(...))). For hver indeks i, hent ut [rad, kolonne] fra plassering-listene og hent ut riktig verdi fra bit-mønster-listen; sett så riktig verdi i matrisen på disse posisjonene.
Sjekk deg selv
Legg til denne snutten nederst i qr2_matrix_completion.py. Om du har gjort alt rett skal du kunne besøke en nettside med en hyggelig melding når du scanner QR-koden som vises.
if __name__ == '__main__':
from qr_dummies import sample_masked_matrix
from qr1_draw import display
from pathlib import Path
import json
# Retrieve sample of premasked matrix without meta/fixed fields
# and getting the matching config for it.
matrix, error_correction_level, mask_no = sample_masked_matrix()
qr_layout = json.loads(Path('qrv2_layout.json').read_text(encoding='utf-8'))
# Try the functions we have created here
set_meta_fields(matrix, error_correction_level, mask_no, qr_layout)
set_fixed_fields(matrix, qr_layout)
# Draw the picture
display(matrix)
3: Maskering
I dette steget skal vi maskere en matrise. Hensikten med å maskere matrisen er å få en jevn fordeling av svarte og hvite ruter i QR-koden, slik at den blir lettere å lese for en QR-scanner. Dette innebærer å «flippe» noen av verdiene i en matrise i henhold til et bestemt mønster. QR -standarden spesifiserer 8 ulike masker man kan velge mellom. Gitt et radnummer row og et kolonnenummer col så skal en posisjon i matrisen flippes dersom en gitt betingelse er oppfylt:
| Maske nr | Betingelse for flipping | Illustrasjon |
| 0 | (row + col) % 2 == 0 |  |
| 1 | row % 2 == 0 |  |
| 2 | col % 3 == 0 |  |
| 3 | (row + col) % 3 == 0 |  |
| 4 | (row//2 + col//3) % 2 == 0 |  |
| 5 | (row*col) % 2 + (row*col) % 3 == 0 |  |
| 6 | ((row*col) % 2 + (row*col) % 3) % 2 == 0 |  |
| 7 | ((row+col) % 2 + (row*col) % 3) % 2 == 0 |  |
I illustrasjonene er de svarte rutene posisjoner hvor betingelsen er oppfylt, og rutene skal flippes.
Funksjonen beskrevet på denne siden skal skrives i filen qr3_masking.py.
should_flip
En funksjon should_flip som skal avgjøre hvorvidt en posisjon skal flippes eller ikke. La funksjonen ha parametre:
rowhvilken rad posisjonen er i,colhvilken kolonne posisjonen er i, ogmask_nohvilken maske som skal benyttes.
La funksjonen returnere True dersom verdien i cellen skal flippes i henhold til gitt maske, og False hvis ikke. Denne funksjonen kan du benytte som en hjelpefunksjon for get_masked_matrix.
get_masked_matrix
En ikke-destruktiv funksjon get_masked_matrix med parametre:
matrixen matrise (2D-liste) hvor alle verdiene er 0 eller 1, ogmask_noet nummer som indikerer hvilken maske som skal benyttes.
Funksjonen skal returnere en ny matrise (2D-liste) med samme dimensjoner som matrix. Verdiene skal også være de samme som i matrix, bortsett fra at alle 1’ere er omgjort til 0’ere og alle 0’ere er omgjort til 1’ere i de posisjonene hvor verdien skal flippes i henhold til maskenummeret.
Legg merke til: det er oppgitt at funksjonen skal være «ikke-destruktiv». Det betyr at funksjonen ikke skal mutere
matrix.
def test_get_masked_matrix():
print('Testing get_masked_matrix...', end='')
blank_5x5_matrix = [[0] * 5 for _ in range(5)]
actual = get_masked_matrix(blank_5x5_matrix, 0)
expected = [
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 1],
]
assert expected == actual
assert blank_5x5_matrix == [[0] * 5 for _ in range(5)]
actual = get_masked_matrix(expected, 1)
expected = [
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
[0, 1, 0, 1, 0],
]
assert expected == actual
print(' OK')
score_matrix
En ikke-destruktiv funksjon score_matrix med én parameter:
matrix, en matrise (2D-liste) med 1’ere og 0’ere.
Funksjonen skal returnere absolutt-forskjellen på antall enere og nullere i matrisen.
PS: Dette er en forenkling; hvis du er interessert i å skrive en ordentlig score-funksjon, kan du lese deg opp hos Thonky sin QR-tutorial. Men: benytt forenklingen vår når du leverer på CodeGrade, siden testene våre forventer det slik.
def test_score_matrix():
print('Testing test_score_matrix...', end='')
arg = [
[1, 0, 0],
[0, 1, 0],
[0, 0, 0]
]
assert 5 == score_matrix(arg)
arg = [
[1, 1, 0],
[1, 1, 0],
[0, 0, 1]
]
assert 1 == score_matrix(arg)
print(' OK')
get_refined_matrix
En ikke-destruktiv funksjon get_refined_matrix med tre parametere:
raw_matrix, en matrise (2D-liste) med 1’ere og 0’ere som representerer en «rå» matrise med umaskert data;error_correction_level, enten L, M, Q eller H som indikerer hvilket nivå av feilretting som ligger i den rå matrisen;qr_layoutet oppslagsverk på formatet gitt i qrv2_layout.json som angir detaljer om hvor de faste kompontentene og meta-komponentene i matrisen befinner seg og hvordan de skal fylles ut.
Funksjonen skal returnere en komplett ferdig matrise som er både maskert og fylt med riktige verdier i de faste komponentene og i meta-komponentene. Importer og benytt funksjoner fra tidligere steg som nødvendig. Funksjonen skal velge det maskenummeret som gir lavest score (og hvis det er to masker som gir samme score, skal den med lavest maskenummer blant dem velges). De faste komponentene og meta-feltene skal legges til matrisen før den scores.
I denne funksjonen skal du «binde sammen» alt du har gjort så langt.
Merk: Dersom du på forhånd vet hvilket maskenummer du skal bruke, kan du fullføre oppgaven ved å bruke (1) get_masked_matrix, (2) set_meta_positions og (3) set_fixed_positions. Tenk på disse tre stegene som å «bygge matrisen».
Det jobben get_refined_matrix skal gjøre, er å prøve ut alle muligheter for maskenummer (bruk en for-løkke). For hvert maskenummer, bygg matrisen og se hvordan den scorer (etter at matrisen er ferdig bygget). Ta vare på matrisen med best score etter hver iterasjon av løkken. Til slutt returnerer du den beste matrisen du fant etter at løkken er ferdig.
Sjekk deg selv
Gå tilbake til qr0_main.py fra introduksjonssteget og endre importene slik at get_refined_matrix importeres fra qr3_masking og ikke fra qr_dummies. Kjør programmet og scan QR-koden som vises. Om du har gjort alt riktig, skal du kunne lese en hyggelig melding.
4: Sikksakk
Det neste steget er å skape en «råmatrise» fra en streng. Denne prosessen vil foregå i to hovedsteg:
- først konverteres strengen til en (1-dimensjonell) liste med «bits» (1’ere og 0’ere), og
- så plasseres den 1-dimensjonelle listen av bits som en slange gjennom en matrise.

Vi skal fokusere på det siste først.

Når vi skal legge listen med bits inn i slangen, følges det et spesielt mønster som slanger seg gjennom matrisen. Vi begynner nederst til høyre og legger bitene som en slange som går opp og ned gjennom matrisen mot venstre. Det som gjør det litt komplisert er at man går «to og to» kolonner om gangen i et sikksakk -mønster. Se illustrasjonen under.
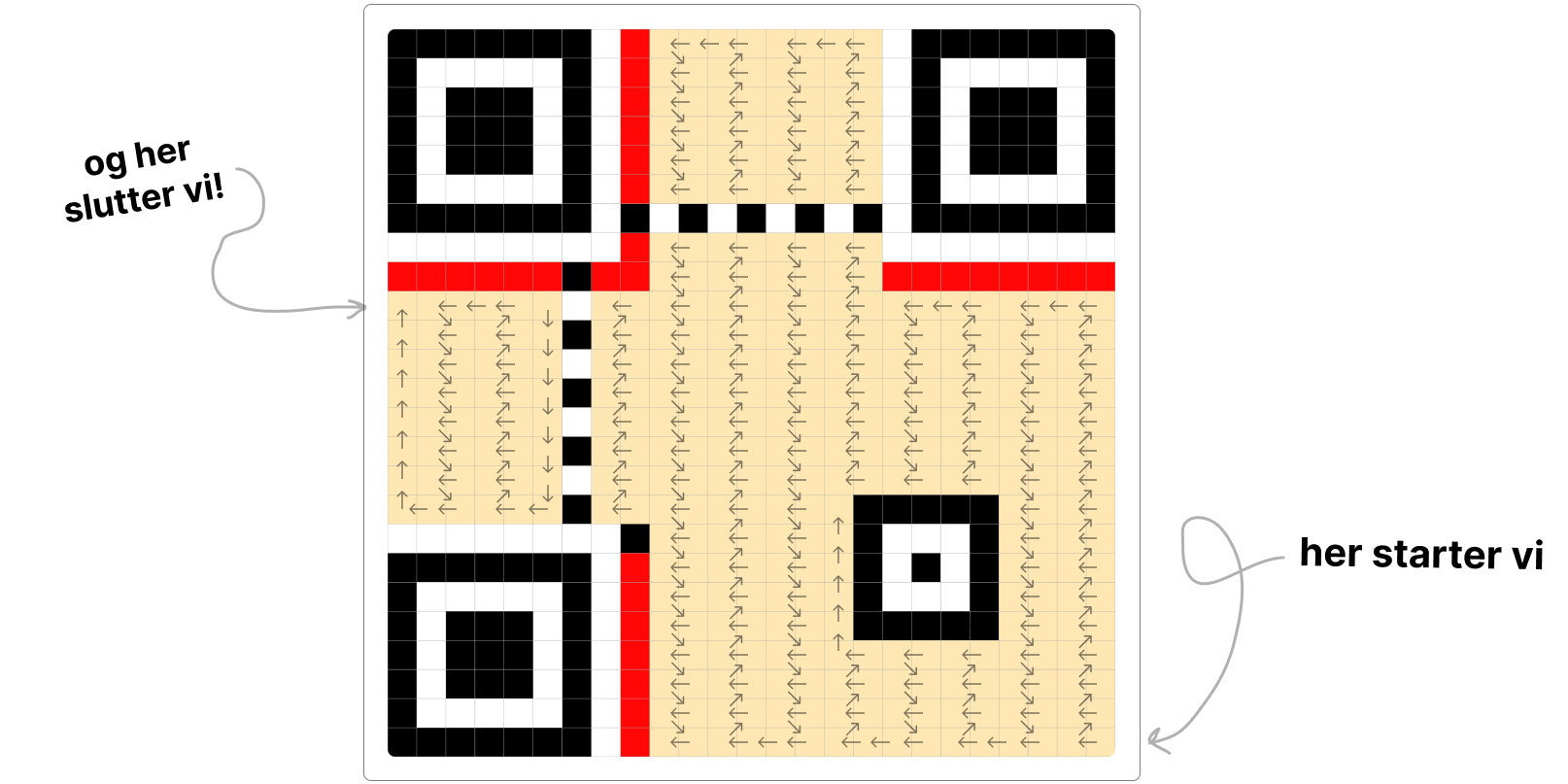
Noen steder (i nærheten av de faste komponentene) ser det ut som mønster av og til avviker fra det vanlige; men det som er kult, er at vi faktisk kan følge det vanlige mønsteret hele tiden, bare at vi hopper over de posisjonene som tilhører faste komponententer og meta-komponentene.
get_next_pos
I filen qr4_zigzag.py skriv en funksjon get_next_pos med parametre:
rowogcolumn, heltall som beskriver en posisjon i en matrise (2D-liste), ogsizeet heltall som beskriver sidelengden i en kvadratisk matrise.
Funksjonen skal returnere en tuple (next_row, next_column) i henhold til slange-sikksakk-mønsteret illustrert over. Du skal ikke ta hensyn til at noen deler av matrisen er forbudt, men la mønsteret fylle hele matrisen.
Du kan anta at size én mer enn delelig på fire, altså at size % 4 er 1 (dette er sant for alle QR-størrelser).
-
Hvis man er i en partallskolonne, flytter man seg ett steg til venstre. Unntaket er hvis man er i kolonne 0, da flytter man seg et steg opp i stedet.
-
Hvis man er i en oddetallskolonne som er én mer enn delelig med fire, er man på vei nedover. Man flytter seg da én ned og én til høyre. Unntaket er hvis man allerede er nederst, da flytter man seg et steg til venstre.
-
Ellers er man i en oddetallskolonne som er tre større enn delelig med fire. Da er man på vei oppover. Man flytter seg da én opp og én til høyre. Unntaket er hvis man allerede er øverst, da flytter man til venstre.
def test_get_next_pos_basic():
print('Testing get_next_pos (basic)...', end='')
size = 25
# De første flyttene
assert (24, 23) == get_next_pos(24, 24, size)
assert (23, 24) == get_next_pos(24, 23, size)
assert (23, 23) == get_next_pos(23, 24, size)
...
# Når vi har sikksakket helt til topps
assert (0, 23) == get_next_pos(0, 24, size)
assert (0, 22) == get_next_pos(0, 23, size)
assert (0, 21) == get_next_pos(0, 22, size)
assert (1, 22) == get_next_pos(0, 21, size)
assert (1, 21) == get_next_pos(1, 22, size)
assert (2, 22) == get_next_pos(1, 21, size)
...
# Når vi har ned helt til bunns igjen
assert (24, 20) == get_next_pos(24, 21, size)
assert (24, 19) == get_next_pos(24, 20, size)
...
# Siste kolonne
assert (24, 0) == get_next_pos(24, 1, size)
assert (23, 0) == get_next_pos(24, 0, size)
assert (22, 0) == get_next_pos(23, 0, size)
print(' OK')
def test_get_next_pos_5x5():
print('Testing get_next_pos (5x5)...', end='')
size = 5
expected = [
[24, 11, 10, 9, 8],
[23, 13, 12, 7, 6],
[22, 15, 14, 5, 4],
[21, 17, 16, 3, 2],
[20, 19, 18, 1, 0]
]
actual = [[-1] * size for _ in range(size)]
row, col = 4, 4
for i in range(size * size):
actual[row][col] = i
row, col = get_next_pos(row, col, size)
assert expected == actual
print(' OK')
def test_get_next_pos_9x9():
print('Testing get_next_pos (9x9)...', end='')
size = 9
expected = [
[80, 55, 54, 53, 52, 19, 18, 17, 16],
[79, 57, 56, 51, 50, 21, 20, 15, 14],
[78, 59, 58, 49, 48, 23, 22, 13, 12],
[77, 61, 60, 47, 46, 25, 24, 11, 10],
[76, 63, 62, 45, 44, 27, 26, 9, 8],
[75, 65, 64, 43, 42, 29, 28, 7, 6],
[74, 67, 66, 41, 40, 31, 30, 5, 4],
[73, 69, 68, 39, 38, 33, 32, 3, 2],
[72, 71, 70, 37, 36, 35, 34, 1, 0]
]
actual = [[-1] * size for _ in range(size)]
row, col = 8, 8
for i in range(size * size):
actual[row][col] = i
row, col = get_next_pos(row, col, size)
assert expected == actual
print(' OK')
bit_list_to_raw_matrix
I filen qr4_zigzag.py skriv en funksjon bit_list_to_raw_matrix med parametre:
bit_listen liste med bits (1’ere og 0’ere) som skal limes inn i en matriseqr_layoutet oppslagsverk med formatet du finner i qrv2_layout.json.
Funksjonen skal opprette en kvadratisk matrise som i utgangspunktet består av kun 0’ere (størrelsen på matrisen som opprettes er angitt i qr_layout). Du skal deretter legge inn elementene fra bit_list: begynn i hjørnet nederst til høyre og benytt get_next_pos -funksjonen for å finne neste posisjon. Hopp over alle posisjoner som er tilhører en fast komponent eller en meta-komponent (informasjon om hvilke posisjoner dette er finnes i qr_layout).
- Hvis det ikke er plass til alle elementene i bit_list, bør programmet krasje.
- Hvis det er plass til overs etter at bitene fra bit_list er plassert, bare la det være 0 i de siste posisjonene.
def test_bit_list_to_raw_matrix():
print('Testing bit_list_to_raw_matrix...', end='')
# To make the test easier to read, bit_list contain distinct elements here
# (in actual applications, bit_list would only have 0's and 1's)
arg_bit_list = list(range(1, 72))
arg_qr_layout = {
'about': 'A fake and incomplete QR layout for testing only',
'side_length': 9,
'fixed_positions': {
'ones': [
[1, 3], [1, 4],
],
'zeros': [
[2, 3], [2, 4],
]
},
'meta_positions': {
'first': [
[5, 2], [5, 3]
],
'second': [
[6, 2], [6, 3]
]
}
# key 'meta_patterns' skipped, since it is irrelevant for this task
}
expected = [
[ 0, 50, 49, 48, 47, 20, 19, 18, 17],
[ 0, 52, 51, 0, 0, 22, 21, 16, 15],
[71, 54, 53, 0, 0, 24, 23, 14, 13],
[70, 56, 55, 46, 45, 26, 25, 12, 11],
[69, 58, 57, 44, 43, 28, 27, 10, 9],
[68, 59, 0, 0, 42, 30, 29, 8, 7],
[67, 60, 0, 0, 41, 32, 31, 6, 5],
[66, 62, 61, 40, 39, 34, 33, 4, 3],
[65, 64, 63, 38, 37, 36, 35, 2, 1]
]
actual = bit_list_to_raw_matrix(arg_bit_list, arg_qr_layout)
assert expected == actual
print(' OK')
Det kan være lurt å samle alle de ulovlige posisjonene i én datastruktur (aller mest effektivt med tanke på kjøretid er det å bruke en mengde av tupler (rad, kolonne) til dette, men en vanlig liste med [rad, kolonne] -elementer fungerer også helt fint med så små matriser vi jobber med nå).
Sjekk deg selv
Gå tilbake til qr0_main.py fra introduksjonssteget og endre importene slik at bit_list_to_raw_matrix importeres fra qr4_zigzag og ikke fra qr_dummies. Kjør programmet og scan QR-koden som vises. Om du har gjort alt riktig, skal du kunne lese en hyggelig melding.
5: Feilretting
I denne siste delen skal vi se nærmere på hvordan vi skal representere en streng som en liste av bits (1’ere og 0’ere). Du husker kanskje fra kursnotatene om unicode at en streng kan representeres som en sekvens av enere og nullere. Det skal vi ser nærmere på her.
Listen med bits i en QR-kode er delt inn i seks deler:

- Modus er fire bits som forteller hvordan resten av bit-listen skal tolkes. For våre formål skal denne verdien alltid være 0100, som betyr at data’en er lagret som «binær» data; de fleste QR-scannere tolker dette i praksis som at dataen representerer en streng i latin-1 (eller ASCII) enkoding (andre mulige verdier som vi altså ikke skal bruke er: 0001 numerisk modus, 0010 alfanumerisk modus, 1000 japansk kanji, og 0111 ECI-modus).
- Lengde er et tall (i totallsystemet) som indikerer hvor mange bytes dataen består av. Åtte bits utgjør én byte, så vi kan gange tallet med 8 for å finne ut for mange bits som befinner seg i data-seksjonen.
- Data er selve dataen. For våre formål et dette en ASCII-enkodet streng.
- Terminator er fire nuller som følger etter dataen (disse brukes egentlig ikke til noen ting i binærmodus, men må være til stede for å fylle opp plassen).
- Padding er noen faste mønstre som gjentar seg. Hensikten er å bruke opp resten av plassen før feilrettingen begynner. Hvor mye padding det er kommer an på hvor mye data det er og hvor mye plass feilrettingen tar (paddingen kan også være ingenting).
- Feilretting er spesielle bits som gjør det mulig å gjenopprette den originale dataen selv om noen bits av en eller annen grunn har blitt flippet. Denne delen regnes ut på bakgrunn av de foregående delene av bit-listen.
Funksjonene på denne siden skal opprettes i filen qr5_bit_list.py.
string_to_data
Opprett en funksjon string_to_data med én parameter:
content_stringen streng du kan anta består av ASCII -symboler.
Funksjonen skal returnere en liste av bits som representerer strengen i ASCII-enkoding.
def test_string_to_data():
print('Testing string_to_data...', end='')
assert [0,1,0,0,0,0,0,1] == string_to_data('A')
assert [0,1,0,0,0,0,0,1,0,1,0,0,0,0,1,1] == string_to_data('AC')
foo = [0,1,1,0,0,1,1,0,0,1,1,0,1,1,1,1,0,1,1,0,1,1,1,1]
assert foo == string_to_data('foo')
print(' OK')
Denne koden konverterer ett symbol til sin ASCII-enkoding:
c = 'A'
bit_list = [int(x) for x in f'{ord(c):08b}']
Hva skjer her da?
ord-funksjonen gir oss ordinalen (tallverdien) for symbolet.b-en inne i krøllparantesene betyr at tallet skal skrives i totall-systemet i strengen som opprettes.08i krøllparantesene betyr at tallet skal skrives med minst åtte siffer, og bruk ledende 0’er om nødvendig. F-strengen evaluerer altså til strengen ‘01000001’. For-løkken går gjennom alle symbolene x i strengen ogintkonverterer hvert symbol til et heltall. Det blir da 1 eller 0 alt etter som. Verdiene legges til i en liste ved bruk av listebygger-notasjon.
For å løse oppgaven, bruk en løkke og gjenta operasjonen over for hvert symbol c i strengen. La bit-listen du finner utvide en resultat-liste du har opprettet før løkken begynner.
# la 'result' være er en tom liste
# for hvert symbol i content_string:
# finn bit-listen for symbolet
# utvid (extend) 'result' med bit-listen
# returner resultatet
get_core_bit_list
Opprett en funksjon get_core_bit_list med én parameter:
content_stringen streng du kan anta består av ASCII -symboler.
Funksjonen skal returnere de fire første delene av en bit-liste: modus, lengde, data og terminator for den gitte strengen
def test_get_core_bit_list():
print('Testing get_core_bit_list...', end='')
arg = 'hei'
expected_head = [0, 1, 0, 0]
expected_len = [0, 0, 0, 0, 0, 0, 1, 1] # 3 in binary
expected_data = [int(x) for x in '011010000110010101101001']
expected_term = [0, 0, 0, 0]
expected = expected_head + expected_len + expected_data + expected_term
actual = get_core_bit_list(arg)
assert expected == actual
print(' OK')
my_len = 42
len_bit_list = [int(x) for x in f'{my_len:08b}']
pad_bit_list
Opprett en funksjon pad_bit_list med to parameter:
core_bit_listen liste med bitspad_to_byteset tall som sier hvor mange bytes den ferdig paddeded bit-listen skal inneholde
Funksjonen skal destruktivt legge til padding-mønstre på slutten av core_bit_list slik at den til sammen blir pad_to_bytes lang. Husk at én byte er åtte bit, så lengden på den endelige listen skal være 8 * pad_to_bytes.
Paddingen som legges til skal veksle mellom [1, 1, 1, 0, 1, 1, 0, 0] og [0, 0, 0, 1, 0, 0, 0, 1] annenhver gang helt til listen er tilstrekkelig lang.
def test_pad_bit_list():
print('Testing pad_bit_list...', end='')
PAD1 = (1, 1, 1, 0, 1, 1, 0, 0)
PAD2 = (0, 0, 0, 1, 0, 0, 0, 1)
arg = [1, 1, 1, 1, 1, 1, 1, 1]
expected = arg + list(PAD1) + list(PAD2) + list(PAD1)
pad_bit_list(arg, 4)
assert expected == arg
arg = [1, 1, 1, 1, 1, 1, 1, 1]
expected = arg + list(PAD1) + list(PAD2) + list(PAD1) + list(PAD2)
pad_bit_list(arg, 5)
assert expected == arg
arg = [1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1]
expected = arg + list(PAD1) + list(PAD2) + list(PAD1) + list(PAD2)
pad_bit_list(arg, 6)
assert expected == arg
print(' OK')
string_to_bit_list
Opprett en funksjon string_to_bit_list med to parametere:
content_string, en streng du kan anta består av ASCII -symboler, ogqr_layout, et oppslagsverk på formatet du finner i qrv2_layout.json.
Funksjonen skal returnere to ting i en tuple:
- en komplett bit-liste, inkludert modus, lengde, data, terminator, padding, og feilretting, og
- en streng på ett tegn: ‘L’, ‘M’, ‘Q’ eller ‘H’ som indikerer hvilket feilrettingsnivå som brukes i bit-listen.
Før vi begynner:
En QRv2-kode har 25x25 piksler, og representerer dermed 625 bit med informasjon. Mye av dette brukes imidlertid til faste komponenter og meta-komponenter, så i praksis er det bare 352 bits (44 bytes) vi har til rådighet (nøkkelen ‘byte_capacity’ i qr_layout forteller oss dette). Denne plassen skal fordeles mellom feltene for modus, lengde, data, terminator, padding og feilrettingskode.
En QR-kode kan ha fire ulike nivåer av feilretting: L, M, Q eller H som gir bedre og bedre nivåer av feilretting. Disse nivåene krever henholdsvis 80, 128, 176 og 224 bits (eller 10, 16, 22 og 28 bytes om du vil). Jo bedre feilretting vi ønsker oss, jo mer plass krever altså feilrettings-komponenten. Konsekvensen av dette er at vi bare kan bruke et høyt nivå av feilretting dersom dataen vi lagrer er tilstrekkelig liten.
Når vi velger nivå av feilretting, gjør vi som følger:
- Vi finner først bit-listen for modus, lengde, data og terminator og ser hvor stor plass dette tar.
- Vi velger deretter nivå av feilretting L, M, Q eller H så høyt som mulig, men slik at det likevel er plass til begge deler (hvis det ikke er plass til laveste feilrettingsnivå, krasj programmet og gi en hensiktsmessig feilmelding).
- Hvis vi ser at det vil bli plass til overs, legger vi til padding før vi regner ut selve feilrettingsmønsteret.
Husk å holde tungen rett i munnen med tanke på bytes og bits. 1 byte = 8 bits.
Forresten, en funksjon for å regne ut selve feilrettingsmønsteret kan du laste ned her: qr6_error_correction.py (du må også installere den eksterne pakken reedsolo. Prøv å skrive python3 -m pip install reedsolo i terminalen eller se notatene om eksterne pakker for eksempler på hvordan man installerer eksterne pakker).
Vil du lære å regne ut feilrettingsmønsteret selv? Sjekk ut INF243.
Ferdigstilling
Gå tilbake til qr0_main.py fra introduksjonssteget og endre importene slik at string_to_bit_list importeres fra qr5_bit_list og ikke fra qr_dummies. Kjør programmet og scan QR-koden som vises. Om du har gjort alt riktig, programmet nå fungerer. Yay!
Kombinere CSV-filer
I denne oppgaven skal vi bruke CSV- biblioteket til å håndtere CSV-filer. Derfor bør du lese om dette i kursnotatene om csv
I denne oppgaven skal vi kombinere flere CSV-filer som ligger i en mappe til én stor CSV-fil. Hver av CSV-filene har det samme formatet, som også er det formatet den kombinerte CSV-filen skal ha:
uibid,karakter,kommentar
abc101,A,"Veldig bra, fra start til slutt"
abc102,B,"Denne kandidaten kan sin INF100, men bommer litt i oppgave 2 og 3"
abc103,C,"Denne kandidaten valgte å kun svare på partallsoppgavene"
I csv_combiner.py skriv en funksjon combine_csv_in_dir(dirpath, result_path) som har to parametre:
dirpather en sti til en mappe som inneholder en rekke CSV-filer som skal kombineres. Det er kun filene som slutter på .csv i mappen som skal inkluderes, andre filtyper skal vi overse.result_pather en sti til en CSV-fil som skal opprettes, som inneholder de kombinerte dataene fra alle CSV-filene.
For å teste funksjonen kan du laste ned samples.zip og pakke ut innholdet i samme mappe hvor du også finner csv_combiner.py. Innholdet skal ligge i en mappe som heter samples. Du kan så teste funksjonen din med denne koden:
print("Tester combine_csv_in_dir... ", end="")
# Mappen samples må ligge i samme mappe som denne filen
dirpath = os.path.join(os.path.dirname(__file__), "samples")
combine_csv_in_dir(dirpath, "combined_table.csv")
with open("combined_table.csv", "rt", encoding='utf-8') as f:
content = f.read()
assert("""\
uibid,karakter,kommentar
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
""" == content or """\
uibid,karakter,kommentar
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
""" == content)
print("OK")
Merk: csv-biblioteket sin standard oppførsel når du lagrer 2D-lister som CSV er at det kun benyttes hermetegn dersom det er nødvendig. Det er nødvendig med hermetegn dersom en celle inneholder skilletegn (komma), linjeskift eller hermetegn. Dersom cellen ikke inneholder noen av de tre tegnene, vil det ikke inkluderes hermetegn i filen. Denne oppførselen kan endres ved å kalle på write_csv_file -funksjonen i kursnotatene med argumentene quoting=csv.QUOTE_NONNUMERIC eller quoting=csv.QUOTE_ALL (se også offisiell dokumentasjon).
Dette betyr at selv om det kanskje er hermetegn i input-filen, vil disse ikke nødvendigvis bli med i resultat-filen. Assert-setningene over viser resultatet slik det blir med standard-innstillingene til csv-biblioteket.
-
CSV-filene i dette eksempelet er best lest med csv-biblioteket. Det blir fort komplisert å tolke dem selv, siden det kan være komma-tegn i kommentar-feltet.
-
Les om
os-modulen, og legg spesielt merke tilos.walk-funksjonen. -
Bruk gjerne en hjelpefunksjon
merge_table_into(master_table, new_table)som tar som input en 2D-listemaster_tablesom skal muteres, og en 2D-listenew_tablesom inneholder det nye innholdet som skal legges til. For hver rad i new_table (bortsett fra første rad), kopier raden inn i master_table.
-
Opprett først en 2D-liste for resultat-tabellen vår, som initielt inneholder én rad (overskriftene). På slutten skal vi konvertere denne listen til CSV.
-
Bruk
os.walkelleros.listdirfor å gå igjennom alle filene i mappen gitt veddirpath(os.walk vil også gå inn i undermapper, og du trenger en nøstet løkke inne i os.walk for å gå gjennom listen med filer; ellers fungerer de nokså likt). For hver fil som ender på .csv (bruk f. eks..endswith-metoden på strenger), åpne filen og les innholdet. -
Husk å bruke
os.path.join-funksjonen for å omgjøre filnavn til filstier. -
For hver .csv -fil du finner, omgjør den til en 2D-liste, og legg til radene i resultat-tabellen (bruk hjelpefunksjonen beskrevet over).
Værmelding
I filen forecast.py skriv en funksjon weather_in_bergen_next_hour() uten parametre som returnerer en streng som sammenfatter været i Bergen den neste timen. Funksjonen skal hente vær-data fra meterologisk instutt, og bruke informasjon fra feltet «symbol_code» om den nærmeste timen.
Eksempelkjøring:
print("Været i Bergen neste time:", weather_in_bergen_next_hour())
Været i Bergen neste time: cloudy
For å løse denne oppgaven, skal vi
- Finne ut hvilken url vi kan bruke for å få informasjon om været fra meterologisk institutt
- Bruke requests -pakken for å laste ned informasjonen fra meterlogisk institutt inn i python-programmet
- Bruke json -pakken for å konvertere den nedlastede informasjonen til et oppslagsverk, og til slutt
- Slå opp på riktig sted i oppslagsverket og returnere denne informasjonen.
Steg A: nettadresse fra meterologisk institutt
Meterologisk instutt tilbyr massevis av vær-informasjon gratis (under lisensen CC-BY 4.0) fra sine nettsider. Slå opp på nettsiden https://api.met.no/weatherapi/locationforecast/2.0/ og finn OPENAPI UI fannen (Øverst i siden ved siden av DOCUMENTATION). Les om GET /compact under data.
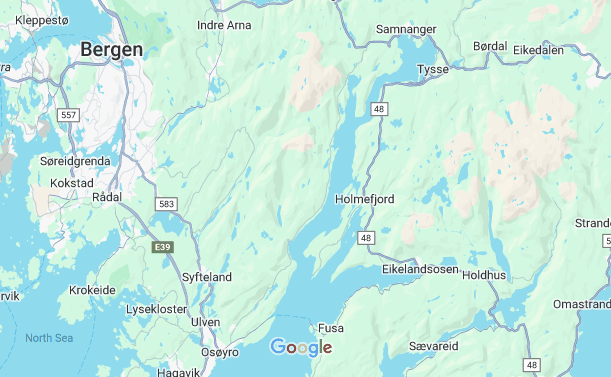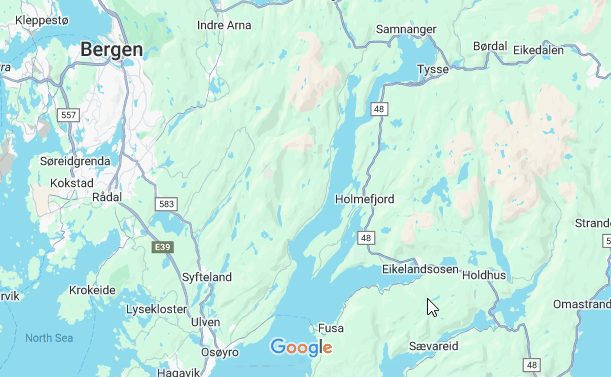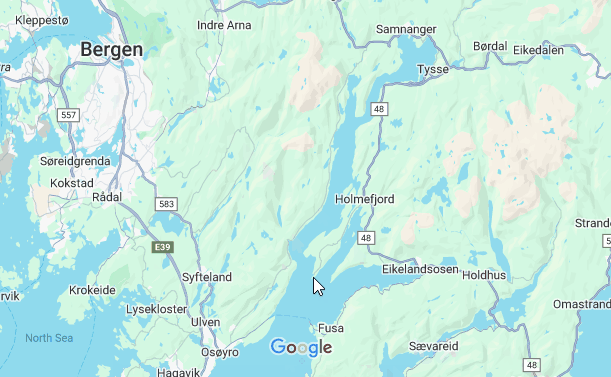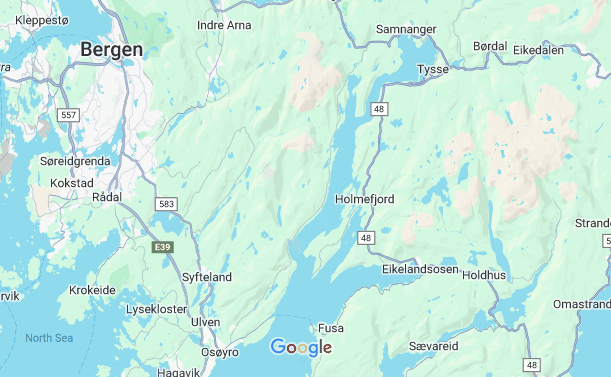
- Du vil under «parameters» se to felter lat og lon hvor du kan fylle ut henholdsvis breddegrad og lengdegrad for hvilken posisjon du ønsker.
For å finne breddegrad og lengdegrad for et gitt sted, kan du på til https://maps.google.com og trykke på kartet. Da vil koordinatene til det gitte stedet vises.
- Når du har fylt ut breddegrad og lengdegrad, trykk på «Try it out!»
- Kopier med deg internettadressen under «Request URL». Dette er adressen til siden vi skal laste ned i programmet vårt (prøv den direkte i nettleseren også og se hva du får).
- Undersøk innholdet under «Response Body». Dette er den strengen vi får når vi laster ned innholdet fra den overnevnte nettadressen. Hvor ligger informasjonen vi er ute etter? Husk, vi ser etter verdier knyttet til nøkkelen «symbol_code».
Steg B: bruk requests for å laste ned informasjon
Bruk nettadressen vi fant i forrige steg som url. Merk at vilkårene til Meterologisk institutt sier at vi må identifisere hvem vi er i User-Agent -feltet i «header». Det er tilstrekkelig å bruke "inf100.ii.uib.no <ditt uib-brukernavn>" som verdi for dette feltet.
Steg C: bruk JSON for å konvertere til oppslagsverk
Du kan bruke json.loads() for å konvertere en streng til et oppslagsverk. Her er et eksempel på hvordan du kan gjøre det:
import json
s = '{"a": 1, "b": 2}'
d = json.loads(s)
print(d["a"]) # 1
Her blir d et oppslagsverk med nøklene “a” og “b” og verdiene 1 og 2.
Steg D: returner verdien knyttet til nøkkelen «symbol code» i oppslagsverket
Det gjelder å holde tungen rett i munnen når du skal slå opp i oppslagsverket. En strategi kan være å begynne med å returnere d["properties"] og så spesifisere videre ved å returnere d["properties"]["timeseries"] og så videre, helt til riktig verdi blir returnert.
Det er ikke nødvendig å finne nøyaktig riktig time for å få oppgaven godkjent, det holder å returnere den første timen du får informasjon om (selv om den var i fortiden)
Steg E (frivillig): finn nøyaktig riktig time å rapportere for
For å rapportere for nøyaktig riktig time, må du matche den timen du får fra meterologisk instiutt med tiden akkurat nå. Les deg opp på datetime -modulen og se om du kan bruke informasjonen fra meterologisk institutt for å finne den nærmeste timen å rapportere fra.
Steg F (frivillig): mer omfattende værmelding
Kan du finne mer informasjon å rapportere? Nedbørsmengder? Vind? Sannsynlighet for nedbør (nå må du over på GET /complete hos meterologisk institutt)?