
Lab6
Kursnotater for tema som er nye i denne laben:
Merk at 5 av poengene i denne laben gis ved deltakelse i gruppeaktivitet i din gruppetime. De resterende 20 poeng gis ved innleveringer i CodeGrade.
Gruppeaktivitet
Denne oppgaven innebærer fysisk oppmøte i gruppetimen din. Du vil få 5 poeng godkjent ved å delta aktivt i gruppeaktiviteten.
Asterisk
I filen asterisk.py, skriv en funksjon add_asterisks med en parameter s for en streng. Anta at strengen du vil få som argument er en sekvens av ord separert med semikolon. La funksjonen returnere en streng med de samme ordene på det samme formatet, men hvor hvert av ordene har blitt omsluttet av asterisker. Se test for eksempler.
def test_add_asterisks():
print('Testing add_asterisks...', end='')
# Test 1
arg = 'foo;bar;qux'
actual = add_asterisks(arg)
expected = '*foo*;*bar*;*qux*'
assert expected == actual
# Test 2
arg = 'honey;mustard'
actual = add_asterisks(arg)
expected = '*honey*;*mustard*'
assert expected == actual
print('OK')
Se kursnotater om split og join.
Handleliste
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver i én felles fil, shopping_list.py.
Del A
Skriv funksjonen shopping_list_to_dict med en parameter shopping_list som er en streng som innholder en handleliste. Funksjonen skal returnere et oppslagsverk med varer som nøkler og antall som verdier. Du kan anta at strengen består av flere linjer, hvor hver linje (som ikke er tom) består av først et heltall, deretter et mellomrom, og deretter navnet på varen (uten mellomrom).
Test koden din:
def test_shopping_list_to_dict():
print('Tester shopping_list_to_dict... ', end='')
arg = '2 brød\n3 pizza\n10 poteter\n1 kaffe\n1 ost\n14 epler\n'
expected = {
'brød': 2,
'pizza': 3,
'poteter': 10,
'kaffe': 1,
'ost': 1,
'epler': 14,
}
actual = shopping_list_to_dict(arg)
assert expected == actual
print('OK')
if __name__ == '__main__':
test_shopping_list_to_dict()
-
Begynn med å opprette et tomt oppslagsverk (som skal returneres på slutten av funksjonen).
-
Bruk en løkke over hver av linjene i strengen
-
Inne i løkken, sjekk at linjen ikke er den tomme strengen (hvis den er det, bruk f. eks.
continuefor å hoppe over denne linjen og fortsette med neste). -
Inne i løkken, bruk linjen
num, food_name = line.split(" ")for å dele opp strengen i to biter; da blir num en variabel som holder en streng med antallet (f. eks."2"), og food_name blir en streng som inneholder navnet på maten (f. eks."brød"). -
I oppslagsverket, legg til food_name som en nøkkel med verdien
int(num).
Del B
Skriv funksjonen shopping_list_file_to_dict med en parameter path som er en streng som representerer en filsti til en fil som inneholder en handleliste.
For å teste funksjonen, last ned filen handleliste.txt og legg den i samme mappe programmet kjøres fra (husk at dette ikke nødvendigvis er samme mappe hvor shopping_list.py ligger med mindre du har åpnet VSCode i den samme mappen).
Test koden din ved å legge til disse linjene nederst i filen:
def test_shopping_list_file_to_dict():
print('Tester shopping_list_file_to_dict... ', end='')
expected = {
'brød': 2,
'pizza': 3,
'poteter': 10,
'kaffe': 1,
'ost': 1,
'epler': 13,
}
actual = shopping_list_file_to_dict('handleliste.txt')
assert expected == actual
print('OK')
Denne funksjonen består av 1-3 linjer med kode avhengig av hvor kompakt du skriver.
-
Begynn med å lese inn hele filen som en enkelt streng.
-
Bruk denne strengen og kall på funksjonen du skrev i forrige deloppgave.
-
Returner resultatet.
Filtrer ordliste
I en fil wordlist.py, lag en funksjon filter_wordlist som har parametre
path, en streng som angir et filnavn, ogsearch_string, en streng vi søker etter.
Funksjonen skal returnere en liste med alle ord fra filen som inneholder søkestrengen. Anta at filen inneholder ett ord på hver linje, og at den er lagret i UTF-8.
For eksempel, hvis filen inneholder
data
datasett
database
baser
syrer
bås
og søkestrengen er 'base', da skal funksjonene returnere en liste ['database', 'baser'] fordi dette er ordene i filen som inneholder «base» som en del av ordet.
Last først ned sample.txt og ordlisten fra Norsk Scrabbleforbund nsf2025.txt og legg filene i arbeidsmappen din (altså samme mappe du har åpnet VSCode i). Test funksjonen din:
def test_filter_wordlist():
print('Tester filter_wordlist... ', end='')
# Test 1
expected = ['database', 'baser']
actual = filter_wordlist('sample.txt', 'base')
assert expected == actual
# Test 2
expected = [
'småstad', 'småstaden', 'småstas', 'småstasen', 'småstat', 'småstaten',
'småstatene', 'småstater',
]
actual = filter_wordlist('nsf2025.txt', 'småsta')
assert expected == actual
# Test 3
expected = [
'stjerneskudd', 'stjerneskudda', 'stjerneskuddene', 'stjerneskuddet',
]
actual = filter_wordlist('nsf2025.txt', 'stjerneskudd')
assert expected == actual
print('OK')
- Opprett en variabel
filtered_wordssom initielt peker på en tom liste. Hensikten er at vi skal legge til de ordene som inneholdesearch_stringi denne listen etter hvert. - Les innholdet i filen (se notater om filer). Dette gir en streng med hele filen.
- Del opp strengen til en liste med linjer med
splitlines(). - Gå gjennom linjene med en for-løkke:
- For hver linje, sjekk om
search_stringer en del av linjen medif search_string in line. - Hvis den er det, legg til linjen i
filtered_wordsmed.append-metoden.
- For hver linje, sjekk om
-
Når du er ferdig med løkken, returner
filtered_words
Splitt dato
Last ned sample_in.csv og split_date.py i arbeidsmappen din.
Del A
Analyse. Spørsmål for refleksjon og diskusjon:
- Hva er hensikten med programmet?
- Hva er hensikten med hjelpefunksjonene csv_to_table og table_to_csv?
- Hva er hensikten med variabelen
date_col? - Hva skjer på linje 19? Hvorfor firkant-klammer?
- Sett et breakpoint på linje 21 og kjør debuggeren. Når programmet stopper på linje 21, inspiser variablene. Klikk på «continue» -knappen (som ser ut som en «play» -knapp i debugger-kontrollpanelet); dette betyr «fortsett å kjøre koden helt til du treffer et nytt breakpoint». Programmet kjører altså koden videre helt til vi er tilbake på linje 21 igjen. Nå skal du ha kommet til den neste iterasjonen av løkken. Verifiser at
row-variabelen nå peker på en annen verdi enn i første iterasjon. Følg med pårow-variabelen i det du klikker på continue enda en gang. Klarer du å forutsi hva som skjer? - Hva skjer i løkkekroppen når vi kommer til datapunktet som har dato 18. september?
- Hva er hensikten med try/except?
- Hva skjer i setningen på linje 28? Hva ville skjedd hvis denne setningen ikke fantes? Hvorfor?
Del B
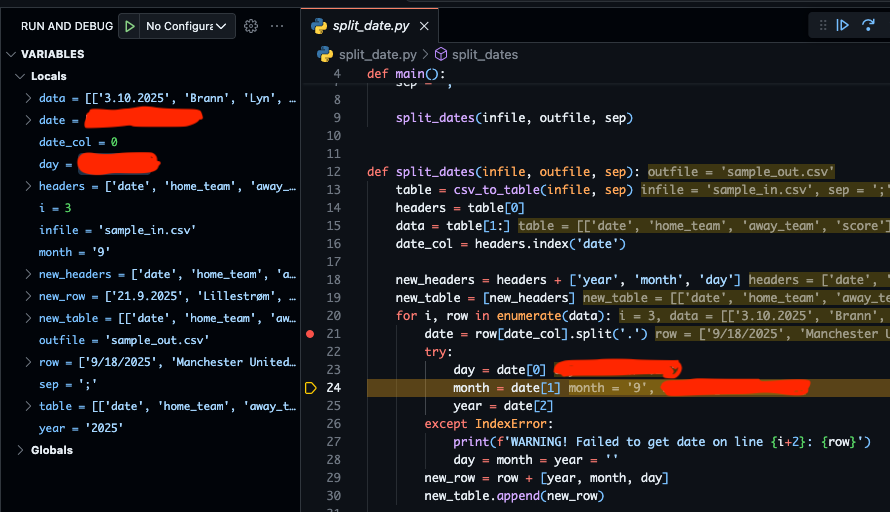
I denne oppgaven skal du levere et skjermbilde split_date.png (eller split_date.jpg) som viser hvilken verdi variabelen day fikk på linje 23 når løkken har kommet den iterasjonen som omhandler kampen mellom Manchester United og Brann 18. september. Eksempel på skjermbilde (men du skal selvfølgelig levere uten sladdene):
Gallius' varer
Trollmannen Gallius har bestemt seg for å åpne en butikk i landsbyen sin. Han har samlet sammen en mengde varer, og har så laget en csv-fil med varene, prisen av å lage varen, antall solgte varer og hva han selger dem for. Siden du enda ikke har sluttet som hans lærling, har han bestemt seg for å gi deg i oppgave å finne ut hvor mye han har tjent på varene sine.
Når skal han lære deg magi, egentlig?
I en fil sales.py, skriv en funksjon total_income som tar inn en filsti path og returnerer total inntekt fra varene opplistet i filen. Anta at filen er kodet i UTF-8 og har følgende format:
name,production_cost,price,sold
Potion of Healing,10,50,100
Potion of Strength,20,100,50
Crystal Ball,50,500,10
Cloak,100,1000,5
Rose of Versailles,500,10000,2
Last først ned sales.csv og legg den i arbeidsmappen din (samme mappe du har åpnet VSCode i). Test funksjonen din ved å kopiere denne testen inn nederst i sales.py.
def test_total_income():
print('Tester total_income... ', end='')
expected = (
(50 - 10) * 100
+ (100 - 20) * 50
+ (500 - 50) * 10
+ (1000 - 100) * 5
+ (10000 - 500) * 2
)
actual = total_income('sales.csv')
assert expected == actual, f'{expected=}, {actual=}'
print('OK')
Relevante kursnotater: lister (særlig avsnittet om konvertering mellom lister og strenger, samt avsnitt om beskjæring) og naturligvis filer og csv.
- Opprett en variabel
incomesom starter på 0. Denne skal holde styr på total inntekt. - Åpne filen og les innholdet som en streng.
- Konverter strengen til en liste av linjer med
.splitlines(). - Den første linjen i filen er kun overskrifter, så vi kan fjerne den ved å beskjære listen med
[1:]. - Gå gjennom hver av de resterende linjene i filen med en for-løkke.
- I utgangspunktet vil hver linje være en streng. Vi kan konverter linjen til en liste av verdier med
.split(','). Dette vil gi oss en liste med strenger, klippet opp med komma som skilletegn. - Hent verdiene for produktkostnad, pris og antall solgte varer fra listen vi nettopp laget; de befinner seg henholdsvis på indeks 1, 2 og 3. Husk at disse er strenger, så vi må konvertere dem til tall før vi kan bruke dem i regneoperasjoner (bruk
int()-funksjonen). - Regn ut inntekten for hver vare og legg den til
income.
- I utgangspunktet vil hver linje være en streng. Vi kan konverter linjen til en liste av verdier med
-
Når du er ferdig med å behandle alle linjene, returner
income
Asterisk CSV
I filen asterisk.py (altså i samme fil som en tidligere oppgave) skriv en funksjon add_asterisks_csv med to parametere:
org_file, filnavnet på en CSV-fil som benytter semikolon som seperasjonssymbol mellom kolonnene.new_file, filnavnet på en fil du skal opprette.
Funksjonen skal opprette en ny CSV-fil med det samme innholdet som den opprinnelige CSV-filen, men innholdet i hver eneste celle i CSV-filen skal være omsluttet av asterisker.
from pathlib import Path
def test_add_asterisks_csv():
print('Testing add_asterisks_csv...', end='')
infile = '.tmp.add_asterisks_csv_test.in.csv'
outfile = '.tmp.add_asterisks_csv_test.out.csv'
Path(infile).write_text((
'foo;bar;qux\n'
'honey;mustard;sausage\n'
), encoding='utf-8')
add_asterisks_csv(infile, outfile)
actual = Path(outfile).read_text(encoding='utf-8')
expected = (
'*foo*;*bar*;*qux*\n'
'*honey*;*mustard*;*sausage*\n'
)
assert expected.strip() == actual.strip()
print('OK')
Dette er i grunnen akkurat som den tidligere oppgaven om asterisker, bare i to dimensjoner.
-
Les inn filen som en stor streng
-
Splitt først på linjeskift.
-
For hver linje, splitt på semikolon.
-
For hvert ord på linjen, legg till asterisker.
-
Lim sammen igjen ordene på hver linje med semikolon
-
Lim sammen igjen linjene med linjeskift
Personlig postkort
Du er en kreativ sjel som elsker å lage personlige og unike postkort til venner og familie ved å bruke bokstaver og bilder klippet ut fra aviser og ukeblader. For å lage et spesielt postkort til en venn, har du bestemt deg for å skrive en hilsen som bruker bokstaver og tegn fra favorittmagasinet deres. For å sikre at du har nok og at du ikke kaster bort tid på å klippe for mye, trenger du å lage en oversikt over nøyaktig hvor mange av hver bokstav og tegn du trenger.
I en fil postcard.py, skriv en funksjon symbol_count som tar inn et filnavn path og returnerer et oppslagsverk som teller hvor mange ganger hvert tegn forekommer i filen. Mellomrom og linjeskift (såkalt whitespace) skal ikke telles. Du kan anta at filen er lagret i UTF-8.
Her er en nyttig funksjon for å fjerne all whitespace fra en tekststreng:
def remove_whitespace(s):
return ''.join(s.split())
Funksjonen split deler en tekststreng ved mellomrom og linjeskift (og annen whitespace), og returnerer en liste av ordene mellom. Deretter brukes join for å sette sammen ordene igjen til en enkelt tekststreng.
Test funksjonen din ved å laste ned postcard.txt i arbeidsmappen din og lim inn den følgende koden på slutten av postcard.py:
def test_count_letters():
print('Tester count_letters... ', end='')
expected = {
'K': 2, 'j': 1, 'æ': 1, 'r': 10, 'e': 15, 'v': 3, 'n': 10, ',': 2,
'S': 2, 'a': 3, 't': 2, 'y': 3, '.': 2, '"': 2, 'F': 2, 'i': 3,
':': 1, 'B': 1, 'o': 2, 'd': 2, 'J': 1, 'u': 1, "'": 1, 's': 4,
'E': 1, 'p': 1, '!': 1, 'l': 2, 'm': 3,
}
actual = symbol_count('postcard.txt')
assert 'æ' in actual, 'æ mangler, har du husket utf-8 encoding?'
assert expected == actual
print('OK')
I funksjonen:
- Les inn filen som en streng.
- Fjern all whitespace fra teksten.
- Lag et tomt oppslagsverk.
- Gå gjennom hvert tegn i teksten og gjør følgende:
- Hvis tegnet allerede finnes som en nøkkel i oppslagsverket, øk tilhørende verdi med 1.
- Hvis tegnet ikke finnes, legg det til med verdien 1.
- Returner oppslagsverket.
Strengsum
Denne oppgaven består av tre deler. Skriv alle deloppgaver i én felles fil, string_sum.py. Før du gjør oppgaven, les gjerne igjennom notater om å håndtere krasj.
Del A
Skriv en funksjon kalt get_stringsum med en parameter s. Anta at parameteren s er en streng hvor noen av «ordene» representerer tall (ulike ord i strengen er skilt av mellomrom). Funksjonen skal returnere summen av de ordene i strengen som er heltall. Hvis ingen av strengene inneholder heltall, skal funksjonen returnere 0.
Test koden din:
def test_get_stringsum():
print('Testing get_stringsum... ', end='')
assert 6 == get_stringsum('4 2')
assert 9 == get_stringsum('5 -1 3 +2')
assert 11 == get_stringsum('5 - 1 3 + 2')
assert 42 == get_stringsum('42')
assert 42 == get_stringsum('forty-one 42 førtitre')
assert 42 == get_stringsum('foo2 42 2qux 3x1')
assert 0 == get_stringsum('')
assert 0 == get_stringsum('foo bar qux')
assert 0 == get_stringsum('-9- 3+2')
print('OK')
Split-metoden klipper opp en streng ved et gitt symbol, og returnerer en liste av bitene som er igjen.
# Eksempler på bruk av .split()
s = 'foo bar qux'
parts = s.split(' ') # parts er nå en liste ['foo', 'bar', 'qux']
print(parts[1]) # bar
s = '3;9;42'
parts = s.split(';') # parts er nå en liste ['3', '9', '42']
print(parts[0] + parts[2]) # 342
-
Begynn med å benytte
.split()-metoden for å omgjøre strengen til en liste av ord. -
Bruk en løkke for å gå igjennom alle elementene i listen.
-
Før løkken starter, opprett en variabel som holder den løpende totalsummen initiert med verdien
0. For hver iterasjon av løkken kan det være vi legger til et nytt tall til denne variabelen. -
Benytt try-except når du forsøker å konvertere strengen til heltall. Dersom omgjøringen feiler, hopp over dette elementet og fortsett videre med neste element i listen.
-
Returner totalsummen når løkken er ferdig.
Del B
I samme fil, skriv en funksjon get_line_with_highest_stringsum med en parameter s som representerer en streng. Funksjonen skal returnere en tuple (i, t, r) hvor i er linjenummeret i strengen s med den høyeste strengsummen, t er selve strengsummen, og r er linjen som har denne strengsummen. Dersom det er flere linjer med samme høyeste strengsum, skal den tidligste av dem returneres. I denne oppgaven teller vi slik at første linje har linjenummer 1. Se også tester for detaljer.
def test_get_line_with_highest_stringsum():
print('Testing get_line_with_highest_stringsum... ', end='')
arg = '4 2\n3 3\n6 6 6 6 12 6\n'
assert (3, 42, '6 6 6 6 12 6') == get_line_with_highest_stringsum(arg)
arg = '4 99 -98\nfoo 42 qux\nfoo bar quz\n'
assert (2, 42, 'foo 42 qux') == get_line_with_highest_stringsum(arg)
arg = '4 2\n3 3\n'
assert (1, 6, '4 2') == get_line_with_highest_stringsum(arg)
print('OK')
Del C
I samme fil, skriv en funksjon main uten parametre som leser inn et filnavn fra brukeren. Deretter skal funksjonen åpne filen og rapportere hvilken linje som har den høyeste strengsummen. Kall main-funksjonen i if __name__ == '__main__' -blokken i programmet ditt, slik at når du kjører programmet får brukeren anledning til å bruke det. Eksempelkjøring (med filen stringsums_file.txt):
Filnavn: stringsums_file.txt
Høyeste strengsum er 42, funnet først på linje 2: «foo 42 qux»
Kraftige jordskjelv
Denne oppgaven består av tre deler. Skriv funksjoner til alle deloppgaver i én felles fil, high_impact.py.
Eksempelet under er en forkortet og forenklet oversikt over registrerte jordskjelv i CSV format hentet fra CORGIS.
id;location;impact;time
nc72666881;California;1.43;2016-07-27 00:19:43
us20006i0y;Burma;4.9;2016-07-27 00:20:28
nc72666891;California;0.06;2016-07-27 00:31:37
I dennne oppgaven skal vi skrive et program som leser inn en CSV-fil med formatet over, og produserer en ny fil som inneholder alle de rekkene i den første filen hvor impact er større enn en gitt verdi.
Det finnes biblioteker som gjør håndtering av CSV-filer enklere, og det kan vi se nærmere på i kursnotatene.. I denne oppgaven skal vi derimot ikke importere biblioteker for CSV-håndtering, men kun bruke standard streng-metoder og kode vi har skrevet selv.
Del A
Skriv en funksjon get_impact(line) som får én enkelt linje (en streng) som input, og som returnerer impact-kolonnen i den linjen som et flyttall. Dersom det er noe feil med input som gjør at det ikke er mulig å se hvilken styrke jordskjelvet har, skal funksjonen returnere None, men ikke krasje.
Test koden din:
def test_get_impact():
print('Tester get_impact... ', end='')
assert 1.43 == get_impact('nc72666881;California;1.43;2016-07-27 00:19:43')
assert 4.9 == get_impact('us20006i0y;Burma;4.9;2016-07-27 00:20:28')
assert None is get_impact('us20006i0y;Burma;not_a_num;2016-07-27 00:20:28')
print('OK')
if __name__ == '__main__':
test_get_impact()
Del B
Skriv en funksjon filter_earthquakes(earthquake_csv_string, threshold) som tar inn en streng earthquake_csv_string med CSV-data på formatet vist over, samt et flyttall threshold. Funksjonen skal returnere en streng på samme format, men hvor linjer med impact strengt større enn threshold -verdien og linjer hvor det ikke er gyldig impact-verdi ikke er inkludert.
Test koden din:
def test_filter_earthquakes():
print('Tester filter_earthquakes... ', end='')
input_arg = '''\
id;location;impact;time
nc72666881;California;1.43;2016-07-27 00:19:43
us20006i0y;Burma;4.9;2016-07-27 00:20:28
nc72666891;California;0.06;2016-07-27 00:31:37
nc72666892;California;not_a_number;2016-08-23 03:21:18
'''
# Test 1
expected_value = '''\
id;location;impact;time
nc72666881;California;1.43;2016-07-27 00:19:43
us20006i0y;Burma;4.9;2016-07-27 00:20:28
'''
actual_value = filter_earthquakes(input_arg, 1.1)
assert expected_value.strip() == actual_value.strip()
# Test 2
expected_value = '''\
id;location;impact;time
us20006i0y;Burma;4.9;2016-07-27 00:20:28
'''
actual_value = filter_earthquakes(input_arg, 3.0)
assert expected_value.strip() == actual_value.strip()
# Test 3
expected_value = 'id;location;impact;time\n'
actual_value = filter_earthquakes(input_arg, 5.0)
assert expected_value.strip() == actual_value.strip()
print('OK')
-
Benytt en for-løkke og .splitlines -metoden for å gå igjennom alle linjene med data. Husk at den første linjen må behandles annerledes
-
Bruk funksjonene fra forrige deloppgave for å finne ut om en gitt linje skal legges til i resultatet eller ikke.
-
Husk å legge til linjeskift.
Del C
Skriv en funksjon filter_earthquakes_file(source_filename, target_filename, threshold) som tar inn navnet på to filer, samt en grenseverdi. Funksjonen skal gjøre det samme som i forrige deloppgave, men leser inn data fra source_filename, og skriver ut data til target_filename.
For å teste funksjonen, last ned earthquakes_simple.csv og legg den i mappen hvor du kjører programmet fra. Så kan du bruke denne funksjonen for å teste:
def test_filter_earthquakes_file():
print('Tester filter_earthquakes_file... ', end='')
def read_file(path):
with open(path, 'rt', encoding='utf-8') as f:
return f.read()
filter_earthquakes_file('earthquakes_simple.csv',
'earthquakes_above_7.csv', 7.0)
expected_value = (
'id;location;impact;time\n'
'us100068jg;Northern Mariana Islands;7.7;2016-07-29 17:18:26\n'
'us10006d5h;New Caledonia;7.2;2016-08-11 21:26:35\n'
'us10006exl;South Georgia Island region;7.4;2016-08-19 03:32:22\n'
)
actual_value = read_file('earthquakes_above_7.csv')
assert expected_value.strip() == actual_value.strip()
print('OK')
# Manuell test: Åpne earthquakes_above_7.csv og se at innholdet stemmer
God stil
Denne oppgaven består av to deler. Skriv funksjoner til begge deloppgaver (A og B) i én felles fil, nice_style.py.
Del A
Tradisjonelt regnes 80 tegn for å være den maksimale lengden på en linje for å ha en god kodestil. Selv om moderne skjermer er i stand til å vise flere tegn på en linje, regnes grensen på 80 fremdeles for å være en god tommelfingerregel, og er for eksempel en del av Python sin offisielle stil-guide PEP 8.
Skriv funksjonen good_style(source_code) som returnerer True hvis alle linjene i strengen source_code er mindre enn eller lik 80 tegn, False ellers.
Merk at grensen på 80 tegn inkluderer selve linjeskift-symbolet på slutten av linjen, slik at det i praksis blir maksimalt 79 tegn på hver linje.
Test koden din:
def test_good_style():
print('Tester good_style... ', end='')
assert good_style('''\
def distance(x0, y0, x1, y1):
return ((x0 - x1)**2 + (y0 - y1)**2)**0.5
''') is True
assert good_style((('x' * 79) + '\n') * 20) is True
assert good_style('x' * 80) is False
assert good_style(
(('x' * 79) + '\n') * 5
+ (('x' * 80) + '\n')
+ (('x' * 79) + '\n') * 5
) is False
print('OK')
if __name__ == '__main__':
test_good_style()
Benytt en løkke som itererer over alle linjene i en streng. string.splitlines() kan hjelpe her. Pass på å ta hensyn til linjeskiftene (se også testene over).
Dersom vi blir ferdige med løkken uten å finne en eneste linje som er for lang, er svaret True.
Del B
Skriv funksjonen good_style_from_file(filename) som leser inneholdet i filen filename og returerer True hvis inneholdet har god kodestil (alle linjene har mindre enn eller lik 80 tegn), False hvis ikke. Kjør koden din på filene test_file1.py, test_file2.py og test_file3.py.
Test koden din med denne funksjonen (gjør et kall til den fra if __name__ == '__main__' -blokken). Det kan være du må justere filstien litt slik at «nice_style.py» viser til riktig fil, altså viser til samme fil du kjører koden fra:
def test_good_style_from_file():
print('Tester good_style_from_file... ', end='')
assert good_style_from_file('test_file1.py') is True
assert good_style_from_file('test_file2.py') is False
assert good_style_from_file('test_file3.py') is False
assert good_style_from_file('nice_style.py') is True
print('OK')
DNA-fragmenter
Som du kanskje har hørt, består DNA av en veldig lang tråd av nukleobaser. Hver nukleobase kan representeres som en av bokstavene A, C, G eller T (henholdsvis adenine, cytosine, guanine, og thymine). Det er derfor mulig å representere et individ sitt DNA som en veldig lang streng med bokstavene ACGT. Det er akkurat dette man har gjort i Human Genome Project, hvor man beskriver det fullstendige DNA’et til et «gjennomsnittsmenneske» som en enkelt streng med omtrent 3.1 milliarder symboler. Prosjektet med å lage denne strengen startet i 1990, og ble helt ferdigstilt først i 2022. Om vi skulle lagret hele strengen i en vanlig tekstfil ville den vært 3.1GB (siden ett symbol i en streng normalt krever én byte å lagre).
Et «genom» er en komplett DNA-streng. Dette til forskjell fra en «DNA-sekvens» som ikke nødvendigvis er komplett.
Ulike mennesker har selvfølgelig forskjellige genomer, men forskjellene er egentlig ganske små: de aller fleste posisjoner i genomet er like for alle mennesker. Selv om det er langt mellom dem, vil noen forskjeller likevel alltid forekomme; til og med én-eggede tvillinger er bittelitt forskjellige fra hverandre grunnet naturlige mutasjoner som oppstår som tidlig foster.
Når man tar en DNA-test av for eksempel en spyttprøve, klarer ikke måleinstrumentet som brukes å lese hele genomet på én gang. I stedet klarer den å lese av en liten bit av det, en såkalt «DNA-sekvens». Instrumentet vet dessverre ikke hvilken bit den har lest. Ved hjelp av et dataprogram (som vi nå skal lage) kan vi derimot sammenligne avlesningen fra instrumentet med genomet for gjennonsnittsmennesket, og på den måten kan vi finne i hvilken posisjon den avleste DNA-sekvensen «hører hjemme».
For eksempel, la oss si at gjennomsnittsmennesket sitt genom er strengen
AAACACCCCCGGGGGTGTTTTTTTTTTTTTTTTTTTTTTTTTTTT
og måleinstrumentet vårt brukt på en bestemt spyttprøve har lest av sekvensen
ACACCCCCGGGGATGT
Vi ønsker da å bestemme en plassering av sekvensen vår slik at den passer best mulig inn med gjennomsnittsmennesket sitt genom. I vårt eksempel er best mulige match å plassere sekvensen slik at den starter på index 2 i genomet; da blir det det kun ett avvik fra gjennomsnittsmennesket. Alle andre plasseringer ville gitt flere avvik.
AAACACCCCCGGGGGTGTTTTTTTTTTTTTTTTTTTTTTTTTTTT
|||||||||||| |||
ACACCCCCGGGGATGT
Del A
I filen dna_fragment_match.py skriv en funksjon best_alignment med to parametre:
genomeen streng som beskriver genomet til et gjennomsnittsmenneske, ogsequenceen (kortere) streng som beskriver en måling gjort av måleinstrumentet.
Funksjonen skal returnere et tall i som beskriver hvilken posisjon i genomet sekvensen mest sannsynlig stammer fra. Dette tallet i skal være indeksen slik at målingen passer best mulig med begynnelsen av genome[i:]. I eksempelet over, er altså svaret 2.
def test_best_alignment():
print('Testing best_alignment...', end='')
genome = 'AAACACCCCCGGGGGTGTTTTTTTTTTTTTTTTTTTTTTTTTTTT'
sequence = 'ACACCCCCGGGGATGT'
assert 2 == best_alignment(genome, sequence)
genome = 'AAAAAAAAAAAAAAAAACACCCCCGGGGGTGTTTTTTTTTTTTTT'
sequence = 'CCGGGGATGT'
assert 22 == best_alignment(genome, sequence)
genome = 'TTTAAG'
sequence = 'AAGT'
assert 2 == best_alignment(genome, sequence)
print(' OK')
Når du sammenligner to plasseringer, er én plassering bedre enn den andre dersom færre posisjoner må endres i mønsteret for å gjøre det helt likt som den gitte delen av genomet.
PS: du skal aldri returnere så stor i at sekvensen plasseres «utenfor» genomet.
Opprett en hjelpe-funksjon alignment_difference med parametre genome, sequence, i som returnerer hvor mange posisjoner som er forskjellig dersom man begynner sammenligningen på posisjon i i genomet.
def test_aligment_difference():
print('Testing alignment_difference...', end='')
genome = 'AAACCC'
sequence = 'ACC'
assert 2 == alignment_difference(genome, sequence, 0)
assert 1 == alignment_difference(genome, sequence, 1)
assert 0 == alignment_difference(genome, sequence, 2)
assert 1 == alignment_difference(genome, sequence, 3)
print(' OK')
Prøv så alle mulige valg av i i en løkke og ta vare på den som gir lavest aligment_difference.
Del B
I samme fil, skriv en funksjon best_alignment_to_file med parametere path og sequence. Denne funksjonen skal lese inn genomet fra filen gitt ved path, men ellers fungere som funksjonen i del A.
Siden det fører til unødvendig mye datatrafikk om alle skal laste ned en 3.1GB tekstfil bare for å gjøre lab-oppgaven sin i INF100, har vi i stedet laget et bittelite eksempel human_genome_excerpt.txt på bare 50KB i stedet. Den inneholder selvfølgelig ikke hele det menneskelige DNA’et, bare et lite utvalg: de 49941 første nukleobasene fra det menneskelige genomet (versjon GRCh38.p14).
def test_best_alignment_to_file():
print('Testing best_alignment_to_file...', end='')
path = 'human_genome_excerpt.txt'
assert 30864 == best_alignment_to_file(path, 'AAACAAAGAA')
assert 2097 == best_alignment_to_file(path, 'GAGTGGGATGAGCCATTGTTCATCT')
assert 0 == best_alignment_to_file(path, 'TAACCC' * 18)
assert 49913 == best_alignment_to_file(path, 'CATTTCAGTAGTAATAGGAATCTCCAC')
print(' OK')