
Lab3
Kursnotater for tema som er nye i denne laben:
Merk at 5 av poengene i denne laben gis ved deltakelse i gruppeaktivitet i din gruppetime. De resterende 20 poeng gis ved innleveringer i CodeGrade.
Gruppeaktivitet
Denne oppgaven innebærer fysisk oppmøte i gruppetimen din. Du vil få 5 poeng godkjent ved å delta aktivt i gruppeaktiviteten.
Tallrekke
Del A: Tallrekke med for-løkke
I en fil sequence.py, skriv en funksjon sequence_for() som tar inn et heltall n og bruker en for-løkke til å sette sammen en string av alle tall fra 0 til og med n med mellomrom mellom seg. Du kan anta at n er et positivt heltall.
Funksjonen range er veldig nyttig for å jobbe med tallrekker!
NB: Vi forventer at det er et mellomrom også på slutten av strengen som returneres.
Du kan begynne fra denne koden:
def sequence_for(n):
... # Din kode her
# Initialiser en tom streng
# For hvert tall i rekken fra 0 til og med n:
# Legg til tallet i strengen med mellomrom
# Returner streng
Her er en funksjon du kan kalle for å teste sequence_for:
def test_sequence_for():
print("Tester sequence_for... ", end="")
assert "0 1 2 3 4 5 " == sequence_for(5)
assert "0 1 2 3 4 5 6 7 8 9 10 " == sequence_for(10)
assert "0 " == sequence_for(0)
print("OK")
Husk at range ikke inkluderer det siste tallet i rekken. For eksempel vil ikke range(5) inkludere tallet 5, men vil inkludere tallene fra 0 til og med 4.
Derfor trenger du å gi n+1 som argument til range for å få den til å inkludere n.
Del B: Tallrekke med while-løkke
I samme fil, skriv en funksjon sequence_while() som gjør det samme som over, men bruker i stedet en while løkke. Du kan begynne fra denne koden:
def sequence_while(n):
... # Din kode her
# Initialiser en tom streng
# Initialiser en variabel i til 0
# Så lenge i er mindre enn eller lik n:
# Legg til tallet i strengen med mellomrom
# Øk i med 1
# Returner streng
Her er en funksjon du kan kalle for å teste sequence_while:
def test_sequence_while():
print("Tester sequence_while... ", end="")
assert "0 1 2 3 4 5 " == sequence_while(5)
assert "0 1 2 3 4 5 6 7 8 9 10 " == sequence_while(10)
assert "0 " == sequence_while(0)
print("OK")
Tell x'er
I en fil count_xs.py, skriv en funksjon count_xs(s) som tar inn en streng s og returnerer antall x’er i strengen. Du kan anta at s kun inneholder små bokstaver.
Du kan begynne fra denne koden som har kommentarer for å hjelpe deg:
def count_xs(s):
... # Din kode her
# initialiser en variabel x_count til 0
# for hvert tegn i strengen:
# hvis tegnet er en x:
# øk x_count med 1
# returner x_count
Teste deg selv:
def test_count_xs():
print('Tester count_xs... ', end='')
assert 0 == count_xs('foo bar hei')
assert 1 == count_xs('x')
assert 4 == count_xs('xxCoolDragonSlayer99xx')
print('OK')
Chatbot
I denne oppgaven skal du lage en veldig primitiv chatbot. Chatboten skal altså bare kunne si tre ting: «Hi! Do you want to talk to me?», «That’s cool!», eller «All right, bye!».
I filen chatbot.py, skriv kode som gjør følgende:
- Ber brukeren for input med teksten, «Hi! Do you want to talk to me?».
- Om brukeren skriver inn, «no» skal programmet skrive ut, «All right, bye!» og avslutte å kjøre.
- Om brukeren skriver in noe annet enn «no», skal programmet skrive ut «That’s cool!», og siden be om input fra brukeren igjen med teksten, «Hi! Do you want to talk to me?»
Eksempelkjøring:
Hi! Do you want to talk to me?
yes
That's cool!
Hi! Do you want to talk to me?
egentlig ikke
That's cool!
Hi! Do you want to talk to me?
no
All right, bye!
Denne oppgaven kan løses på flere måter, men siden vi ikke vet hvor mange ganger løkken skal kjøres på forhånd, må vi i alle tilfeller bruke en while-løkke.
-
Alternativ A: Du kan benytte en while True -løkke, og så benytte break dersom brukeren svarer no.
-
En iterasjon av den innerste løkken er ansvarlig for å skrive ut ett tall, nemlig produktet av iterandene (løkke-variablene) fra de to løkkene.
-
Alternativ B: Du kan opprette en variabel answer = "" før while -løkken starter, og la betingelsen for while-løkken være answer != “no”.
Tallanalyse
Opprett en fil number_analysis.py og skriv inn programmet under.
|
|
Opprett også en fil numbers.json i arbeidsmappen din og skriv inn
[1, 2, 3, 42, 95]
Del A: analyse
Kjør number_analysis.py og verifiser at programmet skriver ut fem linjer som begynner med «Tittei!» samt én linje som begynner med «Summen av tallene». Kjør gjennom koden på nytt med debuggeren, og sørg for at du er i stand til å muntlig besvare følgende spørsmål:
- Hvorfor skrives «Tittei» ut flere ganger, mens «Summen av tallene» bare skrives ut én gang?
- Hva er egentlig rollen til
numi koden? Hvorfor er den kalt dette og ikke for eksempeli? Kunne den hatt et annet navn? - Hva ville skjedd dersom setningen på linje 8 (
total = 0) hadde blitt flyttet inn i løkkekroppen? Hvorfor må den være utenfor? - Hva ville skjedd dersom det var et innrykk (fire mellomrom) på linje 22 før print-setningen?
Del B: modifisering
Gjør nødvendige endringer i number_analysis.py slik at du:
- forteller om tallet er delbart med 3 eller ikke,
- sier ingenting om kvadratet av tallet, og
- regner ut produktet av tallene i listen i stedet for summen
For en fil numbers.json i arbeidsmappen din med innhold som i eksempelet over skal utskriften være nøyaktig:
Tittei! 1 kan ikke deles på 3
Tittei! 2 kan ikke deles på 3
Tittei! 3 kan deles på 3
Tittei! 42 kan deles på 3
Tittei! 95 kan ikke deles på 3
Produktet av tallene [1, 2, 3, 42, 95] er 23940
Dersom restverdien etter heltallsdivisjon med 3 er 0, betyr det at tallet er delbart med 3.
x = 42
remainder = 42 % 3
if remainder == 0:
message = f'{x} kan deles på 3'
else:
message = f'{x} kan ikke deles på 3'
print(message)
Produktet av en samling tall er alle tallene multiplisert med hverandre. For eksempel er produktet av [2, 3, 4] det samme som 2 * 3 * 4.
På samme måte som når vi regner ut summen av flere tall kan vi legge til et og ett tall i en løpende totalsum, så kan vi også med produktet multiplisere inn ett og ett tall om gangen. Forskjellen er hvilken verdi vi starter med før vi ganger inn det første tallet.
-
Når man skal summere, begynner vi med
0. Å legge til0ikke endrer svaret, så da gjør det ingenting om vi plusser inn en ekstra0i svaret vårt. -
Når man skal multiplisere, begynner vi med
1. Å gange med1ikke endrer svaret, så da gjør det ingenting om vi multipliserer inn en ekstra1i svaret vårt.
Pop art
I denne oppgaven skal du lage din egen pop art i filen pop_art.py.
Pop art er en kunststil som ble populær på 1950-tallet. Pop art-kunstnere brukte ofte fargerike bilder av kjente personer, produkter og reklame, og benyttet seg mye av repetisjon av samme bilde i ulike farger. Den fremste eksponenten av pop art var Andy Warhol fra nydelige Pittsburgh PA, som blant annet lagde bilder av Marilyn Monroe og Campbell’s suppebokser.
Programmet ditt skal benytte en funksjon for å tegne et motiv, og funksjonen må kalles minst to ganger for å tegne variasjoner av det samme motivet ulike steder på lerretet. Du må benytte uib_inf100_graphics.simple for å lage tegningen. Du kan velge motivet ditt helt selv. Når du leverer oppgaven på CodeGrade, vil bildet ditt automatisk lastes opp i galleriet, hvor du også kan se hva dine medstudenter har laget. Noen eksempler på hva du kan lage:
Tverrsum
En tverrsum er summen av alle sifrene i et tall. For eksempel, tverrsummen av tallet 123 er 1 + 2 + 3 = 6.
Del A: Tverrsum
I filen cross_sum.py skriv en funksjon cross_sum som med en parameter x som tar inn et heltall og returnerer tverrsummen av tallet.
Du kan begynne fra denne koden:
def cross_sum(x):
... # din kode her
Her er en testfunksjon du kan bruke for å teste cross_sum:
def test_cross_sum():
print('Tester cross_sum... ', end='')
assert 6 == cross_sum(123)
assert 7 == cross_sum(34)
assert 0 == cross_sum(0)
assert 1 == cross_sum(100)
print('OK')
Del B: N-te tallet med tverrsum
I samme fil, skriv en funksjon nth_cross_sum med parametre n og x som tar inn heltall og som returnerer ut det n’te tallet med tverrsummen x.
Eksempel: det første tallet med tverrsum 7 er bare tallet 7, mens det andre tallet med tverrsum 7 er 16. Derfor skal programmet ditt skrive ut 7 på input n = 1 og x = 7, mens programmet skal ut 16 på input n = 2 og x = 7.
Her er en testfunksjon du kan bruke for å teste nth_cross_sum:
def test_nth_cross_sum():
print('Tester nth_cross_sum... ', end='')
assert nth_cross_sum(3, 7) == 25
assert nth_cross_sum(1, 10) == 19
assert nth_cross_sum(2, 10) == 28
assert nth_cross_sum(10, 2) == 2000
print('OK')
-
Du vet ikke før løkken starter hvor mange iterasjoner løkken skal ha. Derfor bør du velge en while-løkke, og ikke en for-løkke for å finne det n-te tallet med en gitt tverrsum.
Smiley
I filen smiley.py ligger det en funksjon for å tegne et smilefjes. Last ned filen (vi trenger ikke endre på den for denne oppgaven, men les litt i den og forstå hva den gjør).
I tillegg kan du opprette filen smiley_grid.py i samme mappe. Begynn med å kopiere inn dette programmet:
|
|
Når du kjører filen smiley_grid.py skal du se tre smilefjes delvis oppå hverandre.
Del A
Akkurat nå ligger smilefjesene oppå hverandre. Det hadde vært bedre om det var nok plass slik at smilefjesene ikke kommer oppå hverandre, men i stedet ligger inntil hverandre. Endre x -verdiene i listen på linje 10 slik at at smilefjesene ikke kommer oppå hverandre, men ligger helt inntil hverandre.

Del B
Vi ønsker å kunne enkelt justere hvor store smilefjesene er. Legg merke til at draw_smiley -funksjonen vi importerer har size som en parameter; men i draw_smiley_line så kaller vi draw_smiley foreløpig bare med argumentet 100 for size-parameteren hver eneste gang. Dette ønsker vi å endre.
- Legg til
sizesom en parameter også i draw_smiley_line -funksjonen. - Benytt den nye parameteren som argument når du gjør kallet til draw_smiley på linje 11.
- I funksjonskallet på linje 6, benytt 60 som et argument for size (du kan såklart prøve andre verdier også)
Når du kjører programmet nå, skal det se slik ut:

Del C
Å nei! Smiley’ene ligger ikke inntil hverandre lengre! Vi må visst regne ut x-posisjonene basert på størrelsen.
- Uten å fjerne for-løkken: endre verdiene i iterabelen (listen av x-verdier) slik at de regnes ut på bakgrunn av størrelsen i stedet for å være helt faste verdier.
Husk at x-verdiene representerer avstanden fra venstre kant av bildet til der smilefjeset begynner. Første x-verdi er altså 0; andre x-verdi skal være like mye som bredden på det første smilefjeset; tredje x-verdi er like mye som bredden på de to første smilefjesene.
[0 * size, 1 * size, 2 * size]
Når du er ferdig skal funksjonkall med ulike verdier for størrelsen gi rader med smilefjes som ligger kant-i-kant uansett. Illustrasjonen under viser kjøringer av programmet der det eneste som er endret er størrelsesverdien vi gir som argument på linje 6.

Del D
Vi ønsker nå justere hvor mange smilefjes vi skal tegne.
- Legg til
nsom et tredje parameter i definisjonen av draw_smiley_line på linje 9 slik at parametrene nå er både canvas, størrelse og antall. - Tilsvarende i funksjonskallet til draw_smiley_line på linje 6 må du legge til et argument for antall fjes som skal tegnes, for eksempel 4.
- I stedet for at iterabelen i for-løkken på linje 10 er en fast liste med verdier, la den i stedet være et range-objekt
range(n). Antall iterasjoner løkken utfører blir da bestemt avn(for eksempel hvis n er 4, kan vi tenke pårange(n)som en slags liste[0, 1, 2, 3]). - Endre navnet på iteranden fra
xtili, siden iteranden nå ikke lengre representerer en x-verdi, men snarere en «indeks» som forteller hvilken iterasjon løkken har kommet til. - På en egen linje inne i løkken, opprett variabelen
xog regn ut en passende verdi for den.
x = i * size
Når du er ferdig skal funksjonskall med ulike verdier for n tegne en rad med n smilefjes som ligger kant-i-kant. Illustrasjonen under viser kjøringer av programmet der det eneste som er endret er argumentet for n gitt i funksjonskallet på linje 6 (animasjonen viser kjøringer med argumenter 0, 1, 2, 3, 4, 5).
Del E
Vi ønsker nå å justere hvor smilefjesene tegnes på y-aksen
- Legg til
ysom den andre parameteren i definisjonen av draw_smiley_line, slik at parametrene nå er(canvas, y, size, n). - Benytt denne parameteren som argument når du kaller på draw_smiley inne i løkken
Når du er ferdig, kan du bytte ut hele main -funksjonen i programmet ditt med denne:
def main():
from uib_inf100_graphics.simple import canvas, display
draw_smiley_line(canvas, 0, 60, 5)
draw_smiley_line(canvas, 60, 100, 3)
draw_smiley_line(canvas, 160, 60, 5)
display(canvas)
Kjør programmet ditt og se følgende bilde:
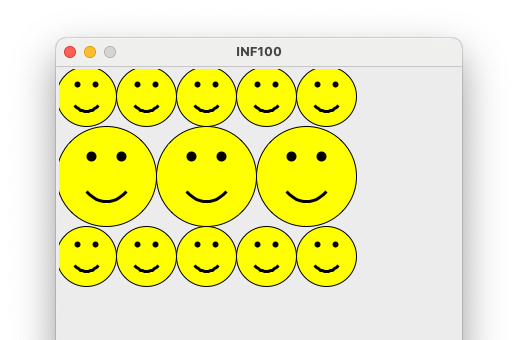
Del F
I filen smiley_grid.py, opprett en funksjon draw_smiley_grid med parametre canvas, size og n. Funksjonen skal tegne et rutenett med smilefjes, der size er størrelsen til ett smilefjes, og n er antall smiljefjes i begge retninger.
Når du er ferdig, kan du bytte ut hele main -funksjonen i programmet ditt med denne:
def main():
from uib_inf100_graphics.simple import canvas, display
draw_smiley_grid(canvas, 70, 5)
display(canvas)
Om du har gjort alt riktig kan du kjøre programmet ditt og se følgende bilde:

-
Bruk en for-løkke for å kalle på draw_smiley_line
nganger -
Regn ut en egnet verdi for
yi hver iterasjon av løkken (dette ligner veldig 😉 på hvordan du regnet ut x)
Oppdelt linjestykke
Del A: Finn endepunkter for et enkelt segment
Et linjestykke langs x-aksen begynner i et punkt \(x_{\text{lo}}\) og slutter i et punkt \(x_{\text{hi}}\). Vi ønsker å klippe opp linjestykket i \(n\) like store deler. Til slutt vil vi vite hvor del \(i\) begynner og slutter.
For eksempel, hvis
- \(x_{\text{lo}} = 50\)
- \(x_{\text{hi}} = 150\)
- \(n = 4\)
- \(i = 1\)
da er svaret vi leter etter \((75, 100)\). Se illustrasjon:

I filen split_line.py lag en funksjon get_endpoints. Denne funksjonen skal ha fire parametere: i, n, x_lo og x_hi. Parametrene x_lo og x_hi er flyttall og definerer linjestykket som nevnt ovenfor. Parametrene i og n er begge heltall. Funksjonen skal returnere start- og sluttpunktet for segmentet med indeks i når vi deler hele linjen i n like store deler. For eksempel: get_endpoints(1, 4, 50.0, 150.0) skal returnere 75.0, 100.0, og get_endpoints(3, 4, 50.0, 150.0) skal returnere 125.0, 150.0.
Legg merke til at lengden til det opprinnelige linjestykkebit er $$\ell_{\text{tot}} = x_{\text{hi}}-x_{\text{lo}}$$
Lengden til en utklippet bit blir da $$\ell_{\text{bit}} = \frac{\ell_{\text{tot}}}{n}$$
Observer også at utklippet bit nummer \(i\) begynner i $$x_{i\text{lo}} = x_{\text{lo}} + i \cdot \ell_{\text{bit}}$$ og slutter i $$x_{i\text{hi}} = x_{i\text{lo}} + \ell_{\text{bit}}$$
PS: funksjoner kan returnere flere verdier. Følgende eksempel viser hvordan:
def foo(bar):
a = 2 * bar
b = 3 * bar
return a, b
x, y = foo(5)
print(x) # 10
print(y) # 15
Test deg selv:
def almost_equals(a, b):
return abs(a - b) < 0.000000001
def test_get_endpoints():
print('Testing get_endpoints... ', end='')
start, end = get_endpoints(1, 4, 50.0, 150.0)
assert almost_equals(75, start)
assert almost_equals(100, end)
start, end = get_endpoints(3, 4, 50.0, 150.0)
assert almost_equals(125, start)
assert almost_equals(150, end)
start, end = get_endpoints(0, 3, -30, 60)
assert almost_equals(-30, start)
assert almost_equals(0, end)
print('OK')
Del B: Lag et interaktivt program
I samme fil (split_line.py) utvid koden med en if __name__ == '__main__' -blokk slik at når du kjører programmet så blir brukeren bedt om å:
- oppgi \(x_{\text{lo}}\)
- oppgi \(x_{\text{hi}}\)
- oppgi tallet \(n\); antall biter linjestykket skal deles opp i.
Deretter skriver programmet ditt ut n linjer, der hver linje består av to tall som representerer et linjestykke. Benytt funksjonen fra del A for å finne punktene (du skal altså ikke gjøre alt på nytt, men i stedet kalle på funksjonen vi allerede har skrevet).
Eksempelkøringer skal se sånn ut:
x_lo = 1.0
x_hi = 7.0
n = 3
1.0 3.0
3.0 5.0
5.0 7.0
x_lo = 0.0
x_hi = 1.0
n = 4
0.0 0.25
0.25 0.5
0.5 0.75
0.75 1.0
Det er vanlig å ha «hovedprogrammet» ditt i en funksjon som heter main, og så kan du kalle på den i if __name__ == '__main__': -blokken. Filen din vil altså ha en struktur som er omtrent slik:
def get_endpoints(i, n, x_lo, x_hi):
... # allerede gjort i del A
def main():
... # skriv dennne i del B
if __name__ == '__main__':
main()
-
Begynn med å be brukeren om verdier for x_lo, x_hi og n (bruk
input-funksjonen og konverter til riktig type). -
Benytt så en løkke for å gå gjennom alle aktuelle verdier for
i. Inne i løkkekroppen, kall på get_endpoints fra del A for å få tak i verdiene du ønsker å skrive ut (du skal altså ikke skrive om igjen koden fra del A, men bruke funksjonen du allerede har skrevet som en hjelpefunksjon). -
I denne oppgaven vet du allerede før løkken starter hvor mange iterasjoner løkken skal ha (nemlig n). Derfor bør du velge en for-løkke, og ikke en while-løkke.
Når du er ferdig skal to ting fungere samtidig:
- Når en bruker kjører split_line.py som hovedfil vil brukeren få en interaktiv opplevelse som utviklet i del B, og
- funksjonen
get_endpointskan importeres fra split_line.py til andre filer uten at det starter en interaktiv opplevelse. For eksempel skal split_line_extra_tests.py kunne kjøres uten at det er behov for at brukeren interagerer med programmet.
Storting
Opprett en fil representatives.py og skriv inn koden under. Kjør programmet og se hva som skjer.
|
|
Del A: forklaring av koden
Hva er hensikten med koden? Kjør gjennom koden steg for steg med debuggeren, og forklar høyt for en medstudent hva som skjer i de ulike seksjonene av koden.
Del B: endringer i koden
Endre programmet slik at det skriver ut en liste over representanter fra Hordaland uansett parti. Listen skal være sortert alfabetisk etter etternavn, og hver linje i listen skal inneholde fullt navn (fornavn og etternavn), samt partiforkortelse i parentes.
De første par linjene i korrekt utskrift (for en kjøring av programmet gjort før det nye stortinget trer i kraft 1. oktober 2025):
Nils T. Bjørke (Sp)
Liv Kari Eskeland (H)
Peter Frølich (H)
Silje Hjemdal (FrP)
Odd Harald Hovland (A)
...
Avvik i utslipp
Karbonintensistet er et mål for hvor store utslipp av CO2 det er per produserte kWh. Storbrittannia sin operator for nasjonale energisystemer (NESO) forsøker å forutsi hvordan dette varierer over tid i strømnettet, slik at miljøbevisste energikonsumenter har muligheten til å legge sitt energibruk til tidspunkter hvor den produserte strømmen har et lavere klimaavtrykk.
I denne oppgaven skal vi finne ut hvor ofte prognosen avviker mye fra den faktiske karbonintensiteten. Som et eksempel på den typen datasett vi skal analysere, kan du laste ned emissions.json.
Programmet vårt for å analysere dette skriver vi i deviation.py. Vi kommer til å bruke flere hjelpefunksjoner for å løse oppgaven, så vi deler den opp i flere deler.
Del 1: Last inn data
I filen deviation.py, skriv en funksjon load_emission_data(filename) som tar inn et parameter filename og returnerer dataene fra json-filen som rike objekter. Her er starterkode:
from pathlib import Path
import json
def load_emission_data(filename):
... # Skriv kode her
return ...
Del 2: Hent ut relevant data
I filen deviation.py, skriv en funksjon get_deviations(data) som tar inn en parameter data (objektet fra del 1) og returnerer en liste med alle «avvik» -verdier. For eksempel, hvis prameteren data viser til et objekt
{
"data": [
{
"from": "2025-09-13T23:00Z",
"to": "2025-09-13T23:30Z",
"intensity": {
"forecast": 100,
"actual": 80,
"index": "low"
}
},
{
"from": "2025-09-13T23:30Z",
"to": "2025-09-14T00:00Z",
"intensity": {
"forecast": 90,
"actual": 94,
"index": "low"
}
},
{
"from": "2025-09-14T00:00Z",
"to": "2025-09-14T00:30Z",
"intensity": {
"forecast": 93,
"actual": None,
"index": "low"
}
}
]
}
skal returverdien fra funksjonen være
[20, 4]
Her kommer tallet 20 fra den første tidsintervallet, hvor prognosen tilsa en verdi på 100, mens den faktiske verdien var 80; altså et avvik på 20. På samme måte var det et avvik mellom prognose og faktisk verdi på 4 i det andre tidsintervallet. I det tredje tidsintervallet var én av verdiene None. I slike tilfeller skal tidsintervallet ignoreres fullstendig.
Noen datapunkter mangler: dette indikeres med
nulli json-filen, og vil automatisk bli omgjort til objektetNonenår du leser inn json-filen i deloppgave 1. Hvis minst én av forecast og actual -verdiene mangler skal du ignorere punktet fullstendig.
Du kan teste deg selv underveis. Last ned deviation_get_deviations_test.py og sjekk at testene passerer.
Husker du for-løkker?
1 2 3 4 5 6 7 8 9 10 11my_list = [ { 'id': 42, 'fact': 'towel'}, { 'id': 95, 'fact': 'McQueen'} ] fact_collection = [] for entry in my_list: fact = entry['fact'] fact_collection.append(fact) print("All the facts:", fact_collection) # ['towel', 'McQueen']I eksempelet over er my_list en «iterabel» (en samling av ting), mens entry er en «iterand». Løkkekroppen (setningene med innrykk, linje 8-9) utføres én gang for hvert ting som er i iterabelen. Iteranden er en variabel som blir tilordnet å peke på neste element fra iterabelen før hver iterasjon av løkken.
-
Bruk en for-løkke med
data['data']som iterabel. -
Hva er et egnet navn på iteranden? (husk, iteranden vil peke på objektet tilhørende ett og ett tidsintervall)
-
I løkkekroppen, hent ut forecast og actual -verdier, og regn ut forskjellen mellom dem. Bruk
abs-funksjonen for å finne absoluttverdien (endrer fra minus til pluss hvis nødvendig/fjerner fortegnet). -
Før du regner ut forskjellen mellom forecast og actual, må du sjekke at ingen av dem er None. Bruk for eksempel en if-setning. Når man sjekker om noe er
Nonebruker man operatorenisi stedet for==. For eksempelif x is None: .... -
Legg til utregnet verdi i en liste.
-
Etter at løkken er ferdig, returner listen.
Del 3: Antall større enn en gitt verdi
I filen deviation.py, skriv en funksjon count_values_larger_than(values, threshold) som tar inn to parametere: values (en liste med tall) og threshold (et tall). Funksjonen skal telle hvor mange tall i listen som er større enn threshold og returnere dette tallet.
Du kan teste deg selv underveis. Last ned deviation_count_values_larger_than_test.py og sjekk at testene passerer.
Del 4: Hovedfunksjon
Nå er vi kommet til hovedfunksjonen hvor vi skal sette sammen hjelpefunksjonene vi har skrevet. I filen deviation.py, skriv en funksjon main() som gjør følgende:
- Bruker
input()til å lese inn et filnavn (f.eks. «emissions.json»). - Bruker
input()igjen til å lese inn en terskelverdi (f.eks. 10). - Regner ut hvor mange avvik som er større enn terskelverdien ved å bruke hjelpefunksjonene du har skrevet.
- Skriver ut resultatet i formatet: “Antall avvik større enn {threshold}: {count}”, for eksempel: “Antall avvik større enn 10: 5”.
På slutten av filen din kan du legge inn dette for å kjøre hovedfunksjonen:
if __name__ == "__main__":
main()
Tegn π
Opprett en fil draw_pi.py og kopier inn dette programmet:
from uib_inf100_graphics.simple import canvas, display
import random
def draw_dot(canvas, x, y):
canvas.create_oval(x-5, y-5, x+5, y+5, fill='orange')
# Draw a circle in the window
canvas.create_oval(0, 0, 400, 400)
# Highlight a random point on 400x400 canvas
x = random.random() * 400
y = random.random() * 400
draw_dot(canvas, x, y)
display(canvas)
Kjør programmet et par ganger. Sjekk at programmet tegner både:
- en liten prikk et tilfeldig sted hver gang programmet kjøres
- en stor sirkel med radius 200 og sentrum i punktet (200, 200).
Del A: tegn mange tilfeldige prikker
Endre koden slik at det ikke bare er én prikk som tegnes, men 1000 tilfeldige prikker. Når du er ferdig skal en kjøring av programmet se omtrent slik ut:

n = 1000
for _ in range(n):
# Kode for å generere ett tilfeldig punkt og tegne det legges her
...
Del B: fargelegg prikkene som er innenfor sirkelen
Endre programmet slik at prikkene som er innenfor sirkelen får en annen farge enn prikkene som er utenfor. Vi sier at en prikk er innenfor sirkelen dersom avstanden fra prikkens sentrum til sirkelens sentrum er mindre enn sirkelens radius, nemlig 200. Sirkelen har sentrum i punktet (200, 200). Når du er ferdig, skal en kjøring av programmet se omtrent slik ut:

- Legg til en parameter for farge i funksjonen som tegner en prikk.
- Bruk en if/else-setning for tegne prikken med enten den ene eller den andre fargen. Betingelsen er at avstanden til sirkelens sentrum (200, 200) er mindre enn 200.
- For å regne ut avstanden mellom to punkter: du kan gjenbruke funksjonen for å beregne avstand fra en tidligere lab, eller du kan regne det ut på nytt.

Del C: tell hvor mange prikker som er innenfor sirkelen
Endre programmet slik at du skriver ut en melding på skjermen som forteller hvor mange av prikkene som er innenfor sirkelen og hvor mange som er utenfor.

- Før løkken: opprett en tellevariabel med initiell verdi 0
- Inne i løkken: når betingelsen er oppfylt slik at det tilfeldige punktet er innenfor sirkelen, øk tellevariabelen med én.
- Etter løkken: tegn en firkant på toppen av bildet ditt. Oppå firkanten kan du skrive en streng.
# Eksempel som skriver ut tekst på toppen av en firkant
message = 'Carpe diem'
canvas.create_rectangle(100, 180, 300, 220, fill='white')
canvas.create_text(200, 200, text=message, fill='blue')
Del D: finn \(\pi\)
\(\pi\) er definert som en sirkels omkrets delt på sin diameter. Uten å vite nøyaktig hvilken verdi \(\pi\) har, kan matematikere bevise at denne verdien, om vi en vakker dag skulle få vite hva den er, kan brukes for å regne ut en sirkel sitt areal:
$$ A_{\bigcirc} = \pi \cdot r^2 $$
Den beste tilnærmingen vi har til \(\pi\) i skrivende stund inneholder over \(10^{12}\) siffer. I Python har vi en tilnærmingen gitt ved
math.pibegrenset til de første 15 siffrene. Det finnes andre moduler som gir oss en bedre tilnærming, men da må vi slutte å brukefloatog heller bruke en annen datatype som er i stand til å gi oss høyere presisjon.
Vi har i de forrige deloppgavene tegnet en sirkel med radius \(r = 200\) som befinner seg inne i et kvadratisk lerret med sidelengde \(s = 400\). Vi legger verdiene for r og s inn i formelene for areal av henholdsvis sirkler og kvadrat, og får følgende:
$$A_{\bigcirc} = \pi \cdot r^2 = \pi \cdot 200^2 = \pi \cdot 40\,000$$ $$A_{\square} = s^2 = 400^2 = 160\,000$$
Dersom vi velger et helt tilfeldig punkt inne i kvadratet, vil punktet med viss sannsynlighet \(p\) også havne inne i sirkelen. Fordi sirkelen er omsluttet av kvadratet på alle kanter, ser vi at \(p\) er gitt ved forholdet mellom arealet av sirkelen og kvadratet:
$$ p = \frac{A_{\bigcirc}}{A_{\square}} = \frac{\pi \cdot 40\,000}{160\,000} = \frac{\pi}{4}$$
Det følger at hvis vi klarer å finne ut hva \(p\) er for noe, trenger vi bare multiplisere tallet med 4 for å finne \(\pi\). Det leder oss til følgende algoritme:
- Gjett et tilfeldig punkt mellom (0, 0) og (400, 400)
- Sjekk om punktet er innenfor eller utenfor sirkelen
- Gjenta steg 1-2 tilstrekkelig mange ganger, og tell opp hvor ofte det tilfeldige tallet havnet inne i eller utenfor sirkelen. Da bli forholdet mellom antall treff i sirkel og totalt antall genererte punkter tilnærmet lik \(p\). La oss kalle tilnærmingen \(\hat{p}\). $$\frac{\text{antall prikker i sirkel}}{\text{antall prikker totalt}} = \hat{p} \approx p$$
- Gang opp \(\hat{p}\) med 4 for å finne en tilnærmet verdi for \(\pi\).
For å gjennomføre algoritmen, gjenstår det altså kun å regne ut \(\hat{p}\), multiplisere med fire og skrive ut estimatet på skjermen. Når du er ferdig, skal en kjøring av programmet se omtrent slik ut:
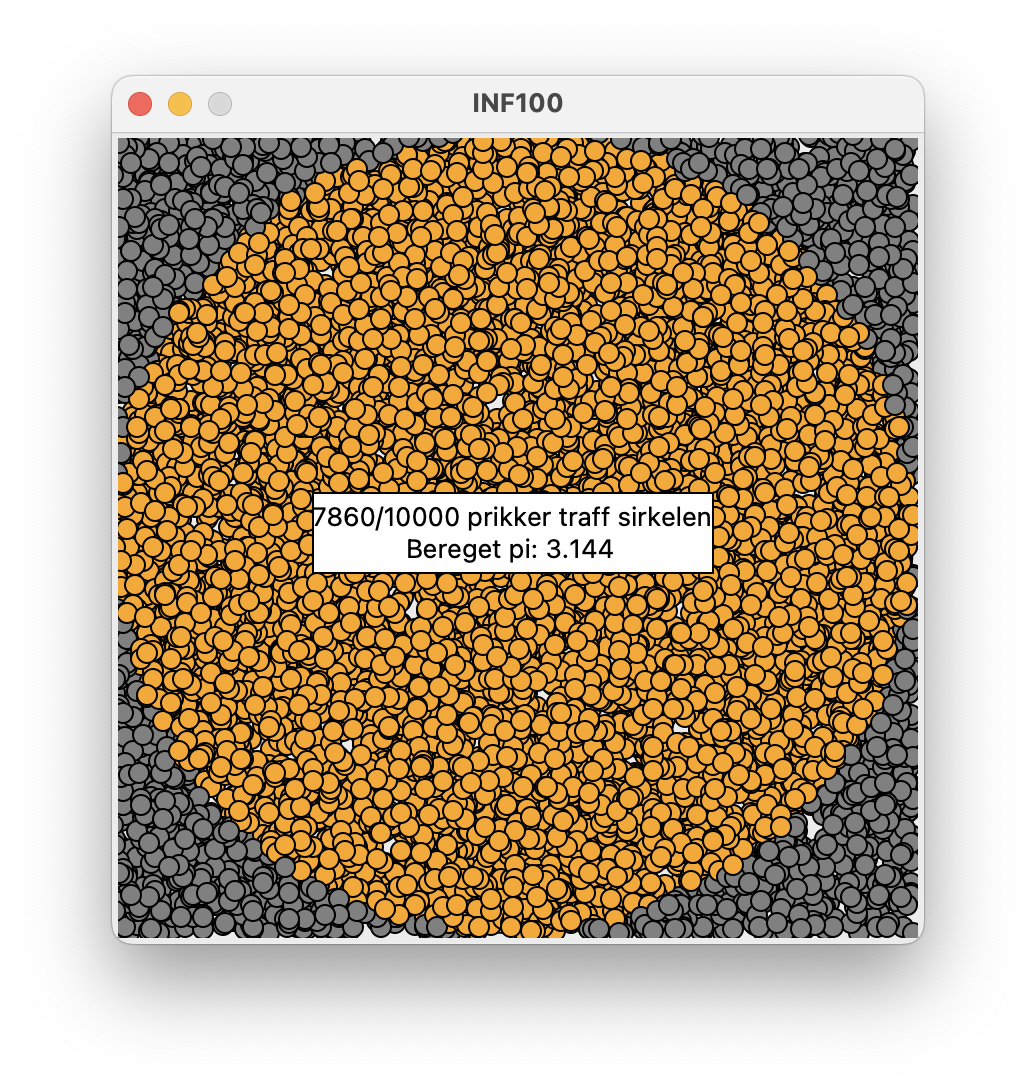
PS: For å få en bedre tilnærming av \(\pi\) kan du øke antall tilfeldige prikker, for eksempel er antallet prikker økt til \(10\,000\) i skjermbildet over. Når du leverer oppgaven på CodeGrade ber vi imidlertid om at du begrenser antall prikker til \(1\,000\) slik at maskinen ikke blir overbelastet.
Fotballkort
Emil samler på fotballkort. Hver lørdag kan han velge mellom å få en liten pose med godteri eller en liten pakke med fotballkort. I en slik pakke får man \(p=8\) tilfeldige kort.
Det er tilsammen \(k=409\) mulige fotballkort å samle på, som hver er nummerert med et tall mellom \(1\) og \(k\). Vi antar at alle kortene har like stor sjanse for å dukke opp i en pakke, og hvis man er riktig uheldig kan man til og med få det samme kortet flere ganger i samme pakke.
Faren til Emil har skrevet programmet football_cards.py for å simulere hvor mange pakker med fotballkort man trenger før man har samlet alle kortene som finnes.

Last ned og kjør programmet. Kikk på output. Hvor mange pakker må man kjøpe for å ha 50% sjanse for å kunne samle et komplett sett?
PS: Scenariet vi har beskrevet er enkelt nok til at en flink statistiker kan gi oss en «analytisk» løsning (altså en nøyaktig løsning – uten at vi skal beskrive hva statistikeren har tenkt og gjort her). Det nøyaktige svaret er at man må kjøpe 327 pakker for å ha minst 50% sjanse for å samle alle kortene. Hvordan sammenligner dette med den midterste kvartilen (medianen) når du kjører programmet? Hva om du kjører programmet flere ganger? Om du øker antall trails?
Forklar høyt for en medstudent hva som skjer i de ulike delene av koden, prøv å gå stegvis gjennom koden med debuggeren, og sørg for at du er i stand til å muntlig forklare ulike spørsmål om koden.
For eksempel, noen spørsmål om funksjonen get_pack_of_cards:
- Hva skjer i setningen
card = random.randrange(1, k+1)? Hvorfork+1? - Hvor kalles get_pack_of_cards, og hvor defineres den?
- Hvor mange iterasjoner av løkken vil finne sted i ett kall til funksjonen?
- Hva er hensikten med setningen
cards = []? Hva skjer hvis setningen flyttes inn i løkken? Hva skjer hvis setningen fjernes? - Hvilken type har retur-verdien?
- Hva skjer med
cardsnår setningenreturn cardsutføres? Hva skjer med variabelen? Hva skjer med objektet variabelen peker på? - Hvorfor krasjer ikke programmet selv om get_pack_of_cards -funksjonen er definert på et høyere linjenummer enn der den blir kallet fra?
Noen spørsmål om funksjonen simulate og repeated_simulations:
- Hva skjer i et kall til simulate-fuksjonen?
- Hva er betingelsen i while-løkken i simulate? Kan vi risikere at løkken varer evig?
- Hva skjer i et kall til repeated_simulations?
Spørsmål for deg som vil gå ett steg dypere:
- Hvorfor sorters sim_results i main-funksjonen?
- I for-løkken i get_pack_of_cards kalles iteranden for
_, mens i for-løkken i insert_pack_into_collection kalles den forcard. Hvorfor det? - Er det nødvendig med funksjonen insert_pack_into_collection eller kunne man like gjerne skrevet de samme setningene direkte i simulate -funksjonen?
Kom gjerne med dine egne spørsmål i tillegg for en god diskusjon med medstudenter eller med gruppeledere :)